Pi Agent 101|03|Session Turn Loop
Pi 的 Agent Loop 像一条工作链:模型提出下一步,runtime 执行,再把结果交回模型。
普通聊天是一问一答。你问一句,模型回一句,事情就结束了。
Coding agent 不一样。你让它修一个失败测试,它可能先读文件,再运行测试,再看报错,再改代码,再运行测试。每一步都不是终点,而是下一步的依据。
你用 Claude Code 或 Codex CLI 时,会看到它一边生成,一边读文件,一边跑命令。它不是“回答慢一点的聊天机器人”,而是在跑一条工作链。
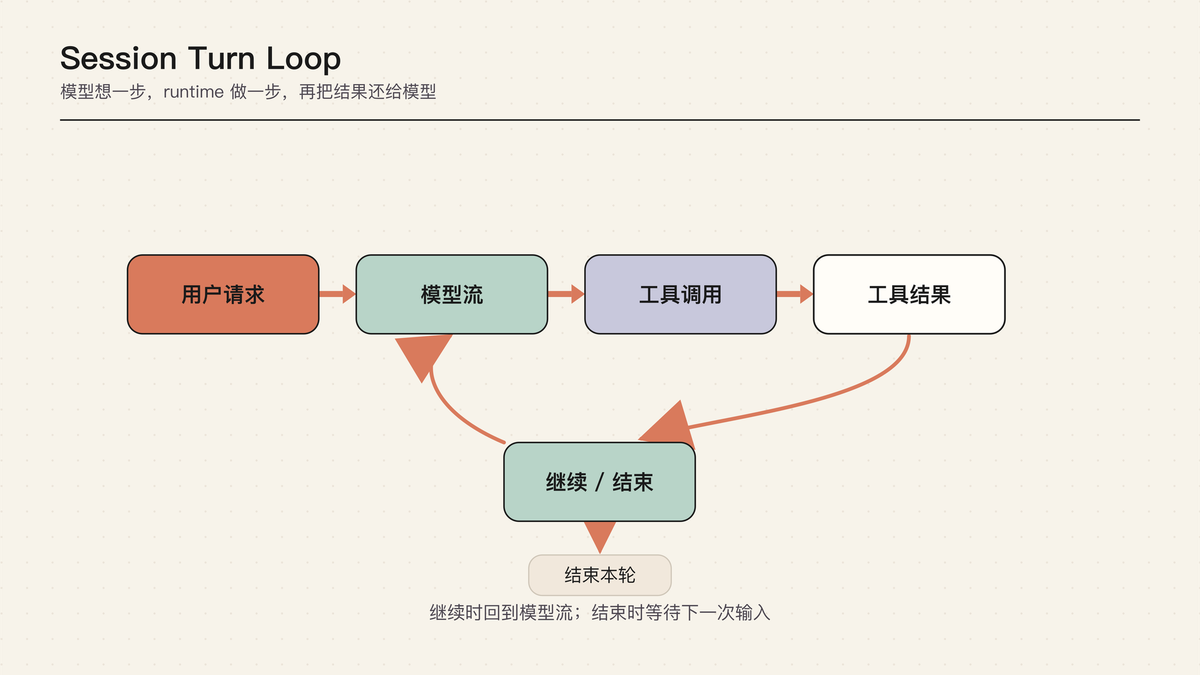
Agent Loop 可以先理解成一句话:模型想一步,runtime 做一步,再把结果告诉模型。
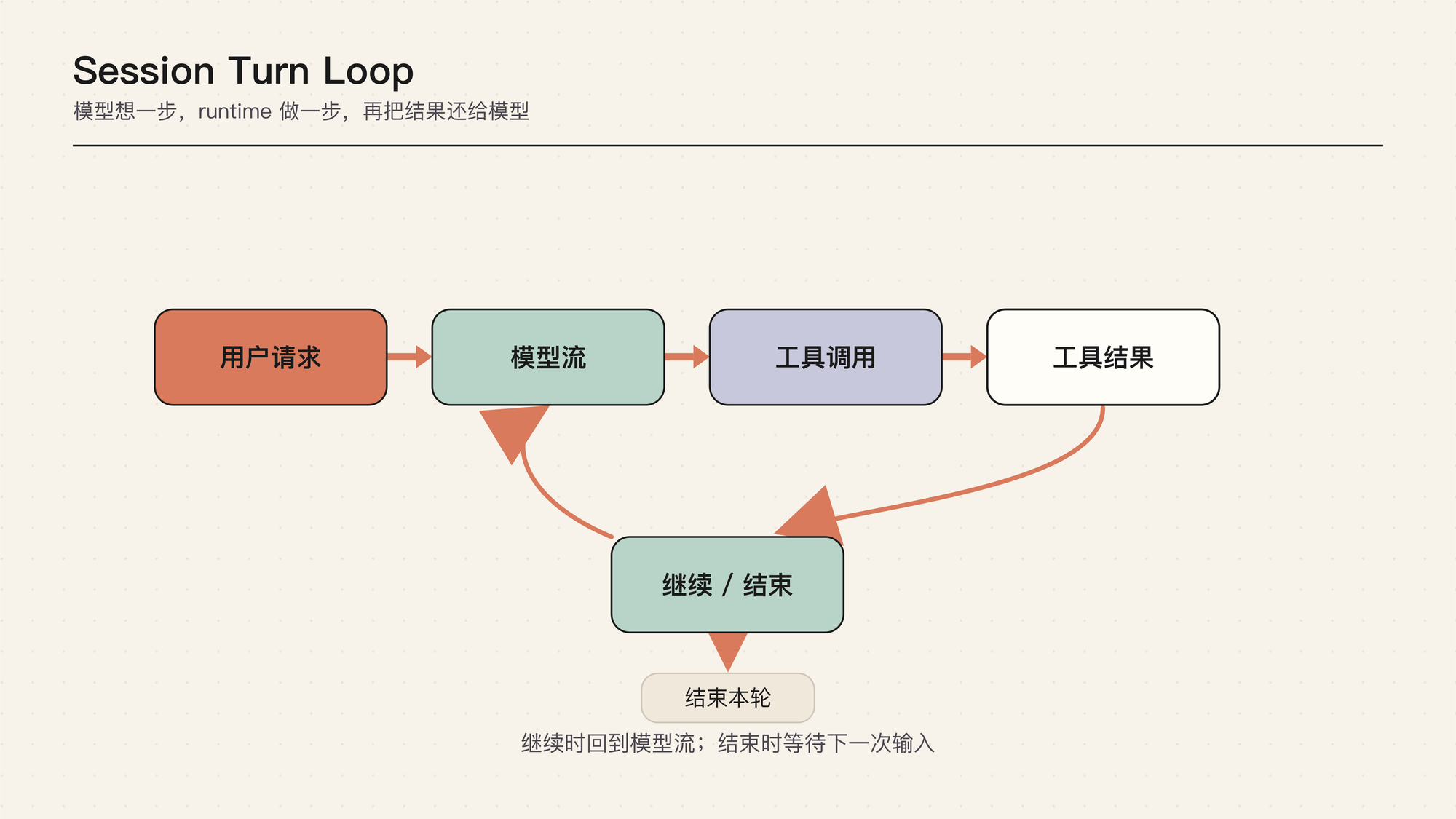
这张图要表达的是控制权的来回切换。用户不是把一个任务一次性丢给模型;模型每一轮只提出下一步,runtime 执行这一步,再把结果变成下一轮事实。一次“修复失败测试”可能经历读文件、跑测试、分析错误、编辑代码、再跑测试、总结结果。
Loop 的核心不是 while 循环本身,而是每个交接点的协议:什么时候开始 turn,什么时候结束 turn,tool result 什么时候回填,用户插话什么时候生效,abort 在哪里被观察到。
本文结构
Turn 可以理解成 Agent 做事的一个节拍:模型说下一步,系统执行工具,把结果交回来,再决定是否继续。一次用户请求可能包含很多个 turn。只要任务还没完成,或者工具结果需要模型继续判断,循环就会继续。
这一篇先讲 turn 为什么存在,再看事件流、用户插话、停止条件和长任务里的故障点。
阅读目标
- 为什么 coding agent 需要 loop,而不是一次 ask(prompt)
- streaming assistant message 为什么有临时态和最终态
- steering 和 follow-up 这两种运行中输入有什么区别
主流 Agent 产品里的 Turn Loop
Claude Code、Codex CLI、Cursor 的 agent 模式,本质上都在跑类似 loop。模型输出文本只是其中一种事件;更关键的是 tool call、tool result、下一轮模型调用。
区别在于产品外观。Claude Code 把这条 loop 展示在终端里,Cursor 把它塞进 IDE 工作流,OpenClaw 可以从 channel 或 gateway 触发 embedded agent。但底层都要回答同一个问题:模型提出下一步后,谁来执行?执行结果怎么回到模型?什么时候停?用户中途插话怎么处理?
一次回答不等于任务结束

这张图说明:一次用户请求可能包含多轮 turn;模型和工具轮流推进。
Pi 的 loop 大致是这样跑的:启动 agent,开始一个 turn,接收模型流,检查模型有没有提出 tool call。如果有,runtime 执行工具,把 tool result 写回上下文,再进入下一轮。直到没有工具调用,也没有排队输入,agent 才结束。
这就是 coding agent 和聊天机器人的差别。聊天机器人给你一个回答;coding agent 在回答、行动、观察之间来回切换。
在 Pi 里,这一切都被组织成事件。事件既给 UI 渲染,也给 RPC/SDK 输出,还能进入 session 记录。
事件流如何进入界面

这张图说明:界面不是猜状态,而是订阅 runtime 事件。
Pi 的事件可以先分成三类。
- agent / turn events:标记一次 agent run 和单个 turn 的边界
- message events:标记 user、assistant、toolResult 的开始、更新、结束
- tool events:标记工具执行开始、流式更新、结束
Assistant streaming 用的是三段式:message_start 创建临时消息,message_update 不断更新 partial message,message_end 固化最终消息。
这解释了为什么终端里能看到模型一点点输出,但 session 最后保存的仍然是一条完整 assistant message。UI 需要流动,历史需要稳定。
用户中途插话

这张图说明:中途插话必须有明确插入位置,否则上下文顺序会乱。
Pi 支持用户在 agent 工作时继续输入,但它不会随便把新输入插进当前模型流里。
Steering message 会在当前 assistant turn 和工具执行完成后进入。它适合“这一轮做完后,稍微调整方向”。
Follow-up message 会等 agent 原本要停下时再进入。它适合“你先把当前任务做完,之后再做这件事”。
这个区别很小,但很重要。如果用户输入可以随时插进任何位置,tool call 和 tool result 的配对关系就很容易被破坏。对 agent runtime 来说,顺序本身就是安全边界。
Loop 的停止条件

这张图说明:停止不是随便停,而是确认没有工具、队列和恢复动作。
还有一条错误路径要单独看:用户按 Escape 或外部调用 abort 时,Pi 不应该粗暴杀掉整个进程。更合理的做法是把 AbortSignal 传进 provider stream 和 tool execution。下一次模型流读取、bash 输出等待或工具执行前,runtime 都有机会检查 signal,停止当前 turn,并把取消状态写成事件。
这也是为什么 abort 属于 Agent core 的能力,而不是 TUI 快捷键的小细节。TUI 只是发出取消意图,真正决定在哪里安全停下来的,是 loop、provider adapter 和 tool runtime。
设计边界
自己做 harness 时,先把 loop 的停顿点设计清楚:模型什么时候交出控制权,工具结果什么时候回填,用户插话什么时候进入,abort 在哪里安全生效。没有这些边界,长任务很快会变成不可预测的异步泥球。
Turn 是产品体验的基本单位
Turn 不只是内部技术概念。它直接决定用户看到的节奏。一个好的 TUI 会让用户知道:模型正在生成、工具正在执行、结果已经回填、下一轮即将开始。一个差的实现只会让用户看到一大段滚动日志,不知道系统是在思考、卡住,还是已经失败。
对产品来说,turn 还是权限和确认的边界。比如模型想执行有副作用的命令,runtime 可以在 tool execution 前暂停,让用户确认;用户按下取消,也通常要等到安全点才能真正停止。
长任务里最容易坏的地方

这张图说明:长任务最怕状态不清;这些风险都要在 loop 边界处理。
第一,模型输出和工具执行没有清晰分界,导致 UI 不知道该显示“模型正在说话”还是“工具正在运行”。第二,工具结果没有结构化回填,下一轮模型只能看到一团文本。第三,用户插话直接追加到 messages 末尾,破坏正在进行的 tool protocol。第四,abort 只停了 UI,没有停 provider stream 或工具执行。
Pi 的意义在于把这些边界显式化。读懂 turn loop,后面看 Tool Runtime、Session Tree 和 Observability 才不会散。
设计取舍
Streaming。UI 需要实时变化,session 需要稳定记录。Pi 用 partial message 支持界面流式刷新,再用 final message 固化历史。
工具结果。Tool call 是中间态,不是任务结束。工具结果写回 context 后,loop 才能进入下一轮判断。
用户追加输入。Steering 和 follow-up 分别对应不同插入时机,避免破坏当前 tool call 的协议完整性。
事件消费。UI、RPC、SDK 可以共享 runtime 事件,但事件格式不能绑定到单一界面。
OpenClaw 的对应问题
OpenClaw 的 channel 看起来只收到一条消息,但 embedded agent run 下面可能是多轮模型调用、工具执行和事件回填。Channel 看到的是一次任务,runtime 处理的是一串 turn。
实现里的循环结构
Pi 的 loop 不是简单的“一次用户输入,一次模型回答”。底层循环可以理解成两层:内层处理当前任务里的模型输出、工具调用和 steer 消息;外层处理 follow-up,也就是 agent 本来要停下来了,但用户或系统排了下一件事。
一个 turn 通常包含四个阶段:模型开始流式生成,runtime 收到 assistant message,发现其中是否有工具调用,执行工具并把 tool result 写回上下文。只要工具结果还需要模型继续判断,下一轮 turn 就会开始。
Pi 还在产品层加了一圈后处理。一次底层 agent run 结束后,AgentSession 会检查是否遇到可重试错误,是否因为上下文溢出需要压缩,是否压缩后要 continue。也就是说,用户看到的一次任务,背后可能包含多次底层 run。
Turn Loop 与产品体验
Turn 是 UI、权限、取消和恢复的基本节拍。用户看到“模型正在生成”“工具正在执行”“测试失败”“准备下一轮”,这些状态都来自 loop 里的事件。
如果 turn 边界不清,产品会出现几个坏体验:工具执行和模型输出混在一起,用户不知道是否能中断;工具结果没有稳定回填,模型下一轮重复犯错;运行中插话没有明确位置,导致上下文顺序混乱;错误重试和上下文压缩悄悄发生,用户无法复盘。
好的 turn loop 会把任务过程整理成一条可读的工作流,而不是一团异步日志。
如何判断
第一,当前控制权在谁手里:模型、工具、runtime,还是用户。控制权不清楚,UI 就无法准确展示状态。
第二,下一轮模型会看到什么。工具结果、用户插话、压缩摘要和错误信息,都要在合适的 turn 边界进入上下文。
第三,任务为什么停止。是模型自然结束,还是工具要求终止,还是用户 abort,还是上下文溢出后需要压缩重试。不同停止原因,对用户解释和后续恢复都不一样。
一句话总结
Coding agent 的一次回答,常常只是下一步行动的开始。
小结
Pi 的 Session Turn Loop 把 agent 看成一条持续推进的工作链,而不是 prompt 到 response 的函数调用。有了稳定的 turn 边界,工具结果知道在哪里回填,用户插话知道什么时候生效,取消和压缩也有了安全点。