Pi Agent 101|02|Message Flow
Pi 用 AgentMessage 保存运行时事实,真正调用模型前才整理成 LLM 能看懂的消息。
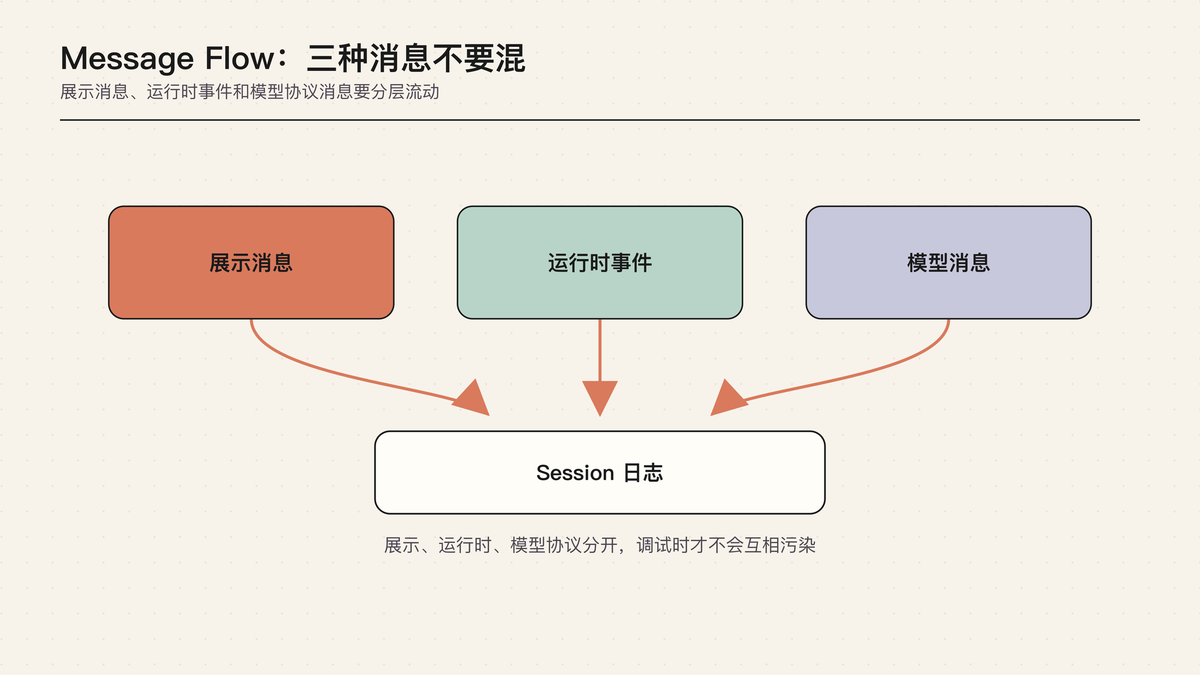
Agent 系统里最容易混的词,可能就是“消息”。
先看一个具体场景:用户手动跑了一条 npm test,终端输出了三百行失败日志。这算不算消息?要不要保存?要不要给模型看?如果给模型看,是给全部日志,还是只给最后的错误摘要?
这就是 Message Flow 要解决的问题。用户说的话是消息,模型生成的回答是消息,工具执行结果是消息,bash 执行记录也像消息。历史压缩后的摘要、分支摘要、扩展插入的 UI 状态,也都像消息。
但它们不能被当成同一种东西。更重要的是,它们不能都直接变成 LLM message。否则模型上下文很快会被日志、UI 状态和内部事件塞满,还可能看到它根本不该看到的内容。
Pi 的做法是把运行时内部的消息,和真正发给模型的消息分开。内部先用更宽的 AgentMessage 保存事实;等到 provider 调用前,再把这些事实整理成 LLM 能理解的 message。
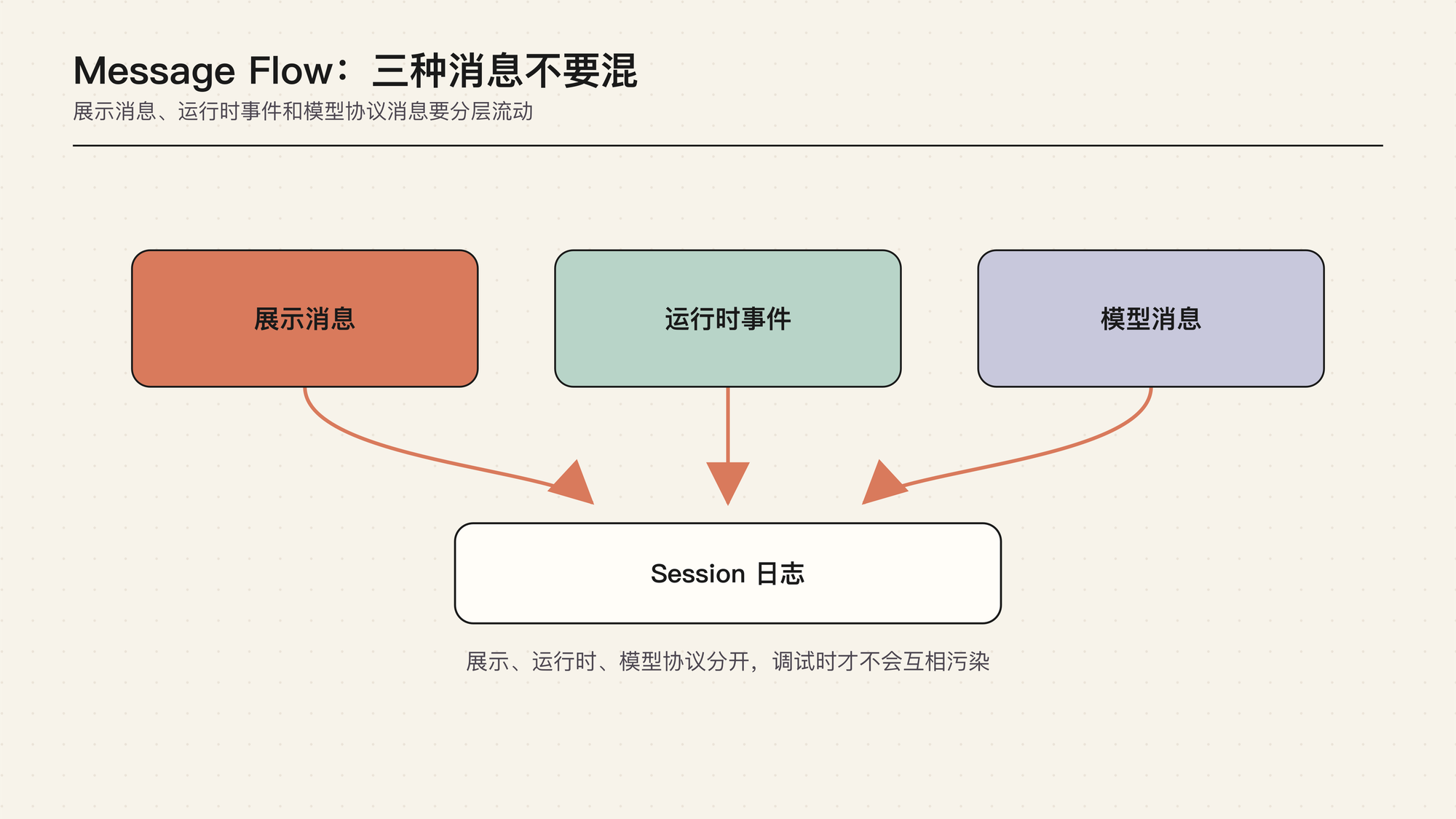
这张图强调三层分离。Runtime facts 保存用户输入、assistant 输出、tool call、tool result、bash 记录、压缩摘要和 UI 事件。Model view 是模型下一轮真正看见的上下文。UI / transcript view 用来展示和复盘过程,但它不等于模型上下文。
如果这三层混在一起,最常见的问题是:UI-only 信息误进 prompt,tool result 被当普通文本处理,压缩摘要覆盖了可审计历史,或者 provider schema 反过来限制了 runtime 能记录什么。
本文结构
消息流讲的是:同一件事,在系统内部、模型眼里、用户界面上,可能长得不一样。用户看到的是对话和工具卡片;系统保存的是带类型的运行记录;模型收到的是被整理后的上下文。理解这一点,就不会把“聊天记录”误认为 Agent 的全部状态。
下面按问题展开:先拆开“消息”这个词,再看 Pi 如何保存内部事实、如何构造模型视图,以及这些边界对 UI、压缩、恢复和导出有什么影响。
阅读目标
- 为什么 session 里保存的东西,不等于模型这一轮看到的东西
- 为什么 bashExecution、branchSummary、compactionSummary 需要自己的语义
- OpenClaw 里 channel message、agent message、tool result、outbound action 为什么不能混成一类
主流 Agent 产品里的消息流
Claude Code、Codex CLI、Cursor 和 OpenClaw 都有同一个问题:用户看到的是对话,系统内部保存的却是一条运行轨迹。
你看到的是一段对话,但产品内部保存的不是单纯聊天记录。它还要保存工具调用、工具结果、命令输出、文件 diff、错误、权限状态、压缩摘要和 UI 事件。模型下一轮真正看到的,只是这些事实里被挑出来的一部分。
这也解释了一个常见现象:终端里出现过的信息,模型下一轮不一定记得;compact 之后,一些细节消失了,任务却还能继续。原因很简单:产品保存的是运行事实,模型看到的是整理过的当前上下文。
消息不是同一种东西

这张图说明:同一件事会被投影成不同视图;不要把 UI 上的聊天气泡误认为全部上下文。
LLM provider 通常只理解少数几类消息:user、assistant、tool result,最多再加 system 或 developer。可是 coding agent 运行时要保存的事实远不止这些。
比如:
- 用户输入了什么目标
- 模型说了什么
- 模型提出了哪些 tool call
- 工具返回了什么结果
- 用户手动跑过什么 bash 命令
- 哪段历史已经被压缩
- 当前分支从哪里开始
- 扩展系统插入了什么 custom message
- 哪些 UI 状态只应该展示给人看
这些东西都属于一次 agent 运行,但不是每一条都适合原样塞进模型上下文。
如果不拆开,问题会很快出现。UI 需要的语义会丢失,session 里的事实会被压成 provider schema,模型也可能看到不该看到的内部事件。
Pi 的消息边界

这张图说明:内部消息先保存事实,真正调用模型前才整理成模型能理解的上下文。
Pi 的边界可以概括成一句话:session 和 runtime 保存 AgentMessage,真正调用 provider 前,才通过 transformContext() 和 convertToLlm() 生成模型能理解的消息。
AgentMessage 是内部运行记录,可以比模型协议更丰富。
convertToLlm() 是出口检查。它决定哪些内部消息进入模型,哪些只留在 session,哪些改写成 user message,哪些直接过滤。
举个例子:compactionSummary 在 session 里是一条结构化记录;但给模型看时,它可以变成一条普通的上下文摘要。bashExecution 可能要展示在 TUI 里,也可能被配置为不进入模型上下文。UI-only 的 custom message 则可以完全过滤。
修测试时发生了什么

这张图说明:文件内容和测试输出不是普通聊天,它们要被整理成下一轮可用事实。
用户说:“修复这个失败测试。”
接下来,session 里可能会出现很多事实:用户目标、模型分析、read 工具返回的文件内容、bash 工具返回的测试失败输出、edit 工具产生的 diff、压缩摘要、分支摘要、扩展插入的状态消息。
这些事实都需要被记录。否则你之后没法复盘,也没法恢复 session。
但模型下一轮不一定要看到所有事实的原始形态。它可能只需要看到目标、最近的测试输出、相关文件片段和一段压缩摘要。换句话说:session 保存完整事实,context builder 决定模型这一轮能看到什么。
设计边界
自己做 harness 时,不要先从 provider message 设计起。先区分三类东西:runtime 内部保存的事实、模型这一轮可见的上下文、UI/日志需要展示的事件。三者可以互相投影,但不要混成同一个数组。
不只是消息类型清单
Message Flow 的难点不在“有哪些 message role”,而在同一个事实会被投影成不同形态。一次 bash 执行,在 session 里是完整事件,在 UI 里是可折叠日志,在模型上下文里可能只剩最后几行错误,在导出的 HTML 里又需要保留命令、退出码和时间线。
这也是 agent 和聊天机器人的分水岭。聊天机器人主要维护对话;coding agent 维护工作过程。工作过程中有很多事实不适合直接塞给模型,但必须被保存、展示、压缩或审计。
判断一个消息系统
看一个 agent 框架时,可以先问三个问题:它内部保存的事实是不是比 provider message 更丰富?它有没有明确的 context builder,把 session facts 转成 model view?它有没有区分 UI 事件、审计事件和模型消息?
如果答案是否定的,这个系统短期也许能跑 demo,但长任务、多工具、可恢复和可观测都会变得脆弱。
设计取舍

这张图说明:消息系统要同时服务模型、用户、持久化和安全边界。
内部消息。Pi 倾向于保留更丰富的 AgentMessage,而不是让 provider schema 反过来限制 runtime。
上下文构造。Pi 在最后一刻才把 session facts 转成 model view。这样可以保留完整历史,也可以按当前任务过滤上下文。
自定义消息。扩展可以注入 custom message,但这些消息必须有明确的可见性策略:给模型、给 UI、给 session,还是只用于内部控制。
UI-only 内容。界面事件不等于模型上下文。UI 需要过程可读性,模型需要下一步行动所需的事实,两者不能混在一起。
OpenClaw 的对应问题
OpenClaw 里也会遇到同样的问题:channel message、agent message、tool result、outbound action、session event,都可能被口头叫成“消息”。如果先用 Pi 的 Message Flow 建立边界,再看 OpenClaw 的消息发送和 transcript 记录,会清楚很多。
实现里的消息边界

这张图说明:保留内部事实,出口再转换,这是避免上下文混乱的核心。
Pi 内部保存的消息,比模型 provider 能理解的消息更丰富。用户消息、assistant 消息、tool result 只是其中一部分。运行过程中还会出现 bash 执行记录、压缩摘要、分支摘要、扩展注入的 custom message,以及只给 UI 或 session 使用的事件。
关键点在于,Pi 不会一开始就把所有东西压成 provider message。它先用内部消息承载运行事实,直到真正调用模型前,才把当前上下文转换成模型能理解的 view。这样 session 可以保留更多事实,UI 可以展示更多过程,而模型只看到这一轮需要看的内容。
例如 bash 输出在 session 里可以保留完整信息,但进入模型上下文时可能只保留命令、关键输出、退出码、是否截断。压缩摘要在 session 里是一条特殊记录,进入模型时则变成“此前对话摘要”。分支摘要也是类似:它不是普通聊天,而是在用户离开旧分支后,对旧路径的一段说明。
Message Flow 解决什么
Message Flow 解决的是“同一个事实给谁看”的问题。模型需要的是下一步行动所需的上下文;UI 需要的是过程可读性;session 需要的是可恢复和可审计;导出页面需要的是复盘证据。
如果没有这层分离,系统很容易出错:UI-only 的内容误进 prompt,过长日志挤爆上下文,工具结果丢失结构,或者压缩后无法解释模型为什么这样继续。
所以这篇文章的重点不是消息类型,而是投影关系:session 保存事实,context builder 选择模型视图,UI/导出负责解释过程。
如何判断
第一,看到一条运行记录时,先判断它是事实、视图还是事件。事实要能恢复工作过程,视图要能喂给模型,事件要能展示给用户。
第二,看到一次上下文构造时,检查它有没有过滤规则。不是所有 session facts 都应该进入模型,尤其是 UI-only 信息、过长日志、被压缩前的重复上下文和与当前任务无关的历史。
第三,看到一次导出或分享时,检查它能不能还原关键过程。只导出模型回答不够;只导出完整原始日志又太吵。好的 transcript 应该让读者知道 agent 为什么走到这个结果。
一句话总结
Session 保存事实,context builder 决定模型这一轮能看到什么。
小结
Agent 的“记忆”不是模型 message 数组。更准确地说,session 保存运行时事实,context builder 生成模型视图,provider adapter 只处理最后的协议格式。这个边界越清楚,agent 越容易扩展、压缩、恢复和调试。