Pi Agent 101|01|Agent Runtime
一条用户消息进入 Pi 后,会先经过运行时调度,再进入模型、工具、会话、扩展和界面系统。
你在终端里输入一句话:帮我修一下这个失败测试。
如果这是普通聊天机器人,它可能会直接把这句话发给模型,然后等一段回答。但一个 coding agent 不能这么简单。它面对的不是一段孤立文本,而是一个正在运行的工程现场:当前目录是什么,模型是谁,历史消息在哪,工具能不能用,项目规则有没有加载,用户是否正在中途插话,工具结果要怎么回填,界面又该如何展示这一切。
这就是 Agent Runtime 要解决的问题。
Runtime 是模型外面的调度系统。模型生成下一步,runtime 负责把这一步放进真实环境里执行,再把执行后的事实交回模型。
在 Pi 里,这层 runtime 不是一个单独文件,而是一组边界清楚的组件:provider 抽象负责模型事件,agent core 负责 loop 和工具调用,coding agent session 负责产品环境,mode adapter 负责把同一个运行时接到 TUI、print、RPC 或 SDK。
本文结构
把 Agent 简化成“把问题发给大模型”,会漏掉真正困难的部分。运行时要保存任务状态,决定什么时候调用模型、什么时候执行工具、什么时候把工具结果交回模型,也要把过程同步给界面。
这篇按运行顺序展开:先看 runtime 为什么不能只是一次模型调用,再看 Pi 的四层边界、消息路径、状态拆分、Agent Core、Agent Loop 和 AgentSession。图不会集中堆在开头,而是放在机制第一次出现的地方。
为什么不能直接调用模型
很多人第一次写 agent,会从一个最小循环开始:把用户输入拼进 prompt,调用模型,如果模型返回 tool call,就执行工具,再把结果追加回 messages。这个最小版本能跑 demo,但很快会遇到几个问题。
第一,用户输入不是唯一上下文。真实 coding agent 还要带上 system prompt、项目规则、skills、当前工作目录、历史 session、压缩摘要、工具清单、模型配置和可能的图片输入。模型看到的是一份整理后的上下文,不是用户刚打的那一句话。
第二,模型输出不是最终动作。模型说“读这个文件”只是一个意图。谁去检查工具参数?谁决定这个工具能不能执行?谁把 stdout、stderr、错误码、文件 diff 写回上下文?这些都不是模型完成的,而是 host-side runtime 完成的。
第三,一次任务不是一次模型调用。模型可能先读文件,再跑测试,再编辑文件,再跑测试。每一次工具调用之后,runtime 都要把 tool result 变成下一轮模型可见的事实。也就是说,agent 的核心不是 request/response,而是 turn loop。
第四,产品需要恢复、分支和展示过程。CLI、TUI、RPC、SDK 看起来是不同入口,但它们不能各自复制一套 agent loop。否则 session、工具行为、压缩、错误处理和事件记录都会分叉。Pi 的做法是:入口可以不同,底层 runtime 尽量共用。
Agent Runtime 不是“调用模型的地方”。它把模型、工具、状态和产品界面组织成一个可以持续运行的系统。
主流 Agent 产品里的 Runtime
Claude Code、Codex CLI、Cursor 和 OpenClaw 都会遇到类似分层,只是名字不同。
Claude Code 不是把用户输入直接扔给 Claude。它要先读项目规则,组织上下文,决定工具权限,处理 Bash/Edit/Read 的结果,再把事件展示到终端。Codex CLI 也是一样:外面是 CLI/TUI,里面是 session、turn、tool runtime 和模型流。
Cursor 看起来更像 IDE,但底层问题也类似:用户一次请求要绑定工作区、文件、工具、模型和 UI 状态。OpenClaw 则把这个问题扩到 channel、plugin、gateway 和多种 provider 上。产品形态不同,底层都绕不开这件事:先有 runtime,模型才有地方工作。
OpenClaw 的 channel、plugin、gateway、media、voice 都在更外层。Agent 真正跑起来时,仍然要靠 runtime 处理模型、工具、消息、session 和 UI 事件。Pi 讲的是这层底座。
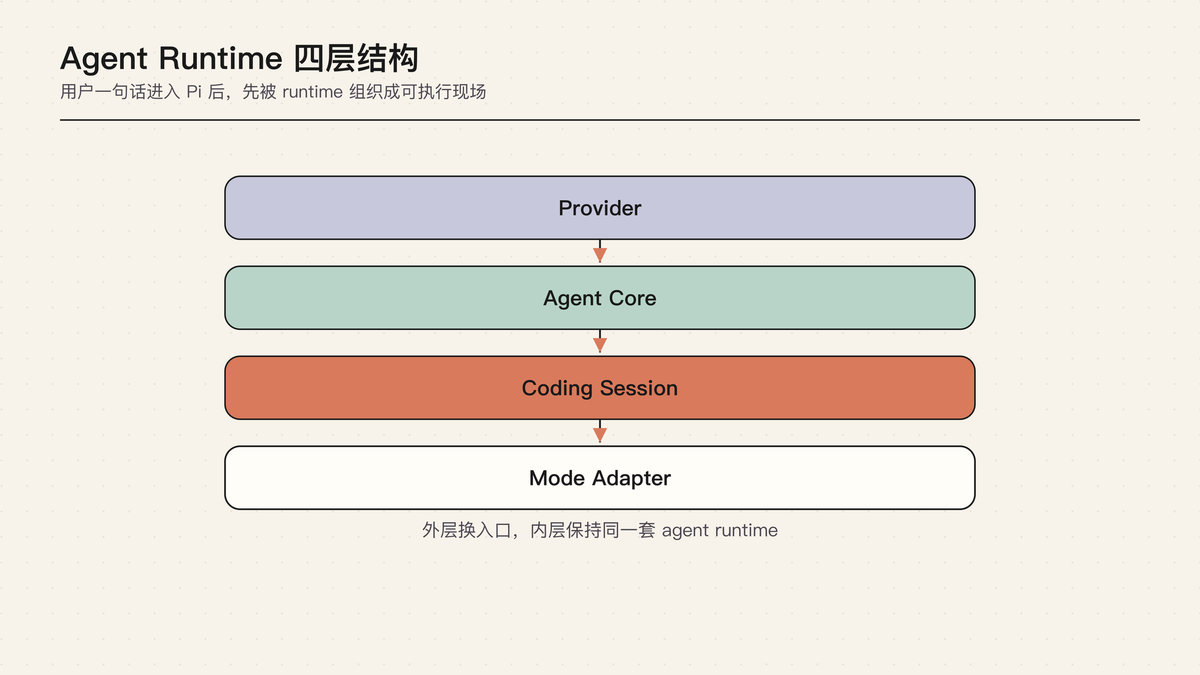
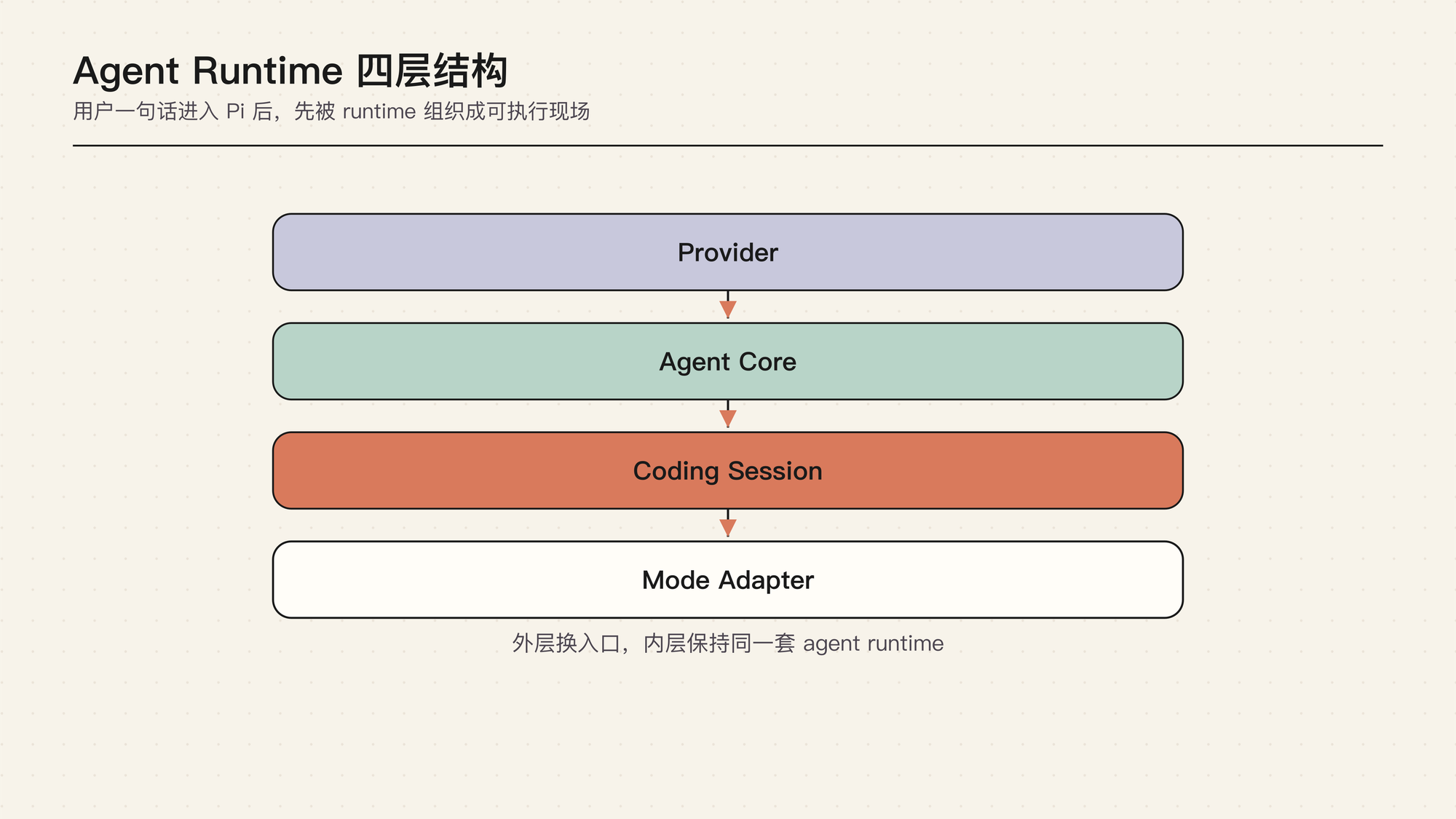
Pi Runtime 的四层边界
这张图不是部署架构,而是责任分工:上面处理模型差异,中间推进任务,下面接入项目环境和产品入口。

这张图说明:这张图应该和下面四层解释一起读。Provider layer 解决模型厂商差异,Agent core 解决通用循环,Coding Agent Session 解决本地工程现场,Mode adapter 解决不同入口。
Pi 的 runtime 可以分成四层。它们不是严格的部署层,而是 agent 产品里的责任边界。
Provider layer
这一层把不同模型厂商变成统一事件流。OpenAI、Anthropic、Google 或其他 provider 的 API 形态不一样,stream event、tool call、reasoning、usage、stop reason 也不完全一样。Pi 不希望上层到处处理厂商差异,所以先在模型层把它们归一化。
后面的 Provider Abstraction 文章会专门展开这一层。
Agent core
这一层管通用 agent loop:保存当前 messages,流式接收模型输出,执行工具,把 tool result 写回上下文,再决定是否进入下一轮。它知道模型、工具、消息和事件,但不应该知道 TUI 主题、项目配置、session 文件长什么样。
它对应的是通用 agent 能力,不绑定某个产品界面。
Coding Agent Session
这一层把通用 agent core 放进 coding agent 产品环境里。它知道当前工作目录、session manager、resource loader、model registry、默认工具、skills、extensions、compaction、bash 执行和 HTML export。也就是说,它不是纯 loop,而是“可以在本地工程里工作的 agent 产品运行时”。
它对应的是 coding agent 的产品运行环境。
Mode adapter
这一层把同一个 session runtime 接到不同入口:interactive、print、RPC、SDK。TUI 要实时渲染事件,print mode 要输出文本或 JSON,RPC mode 要把事件发给外部进程,SDK 要把 runtime 变成可嵌入接口。它们不应该各自发明一套 loop。
它对应的是不同入口和外壳。
这四层里,最容易忽略的是 Agent core 和 Coding Agent Session 的区别。Agent core 是发动机,AgentSession 是把发动机装进一辆能上路的车。前者推进任务,后者组织现场。
一条消息的运行路径

这张图说明:这张图对应本节的消息链路。用户输入先进入 Session 做产品层预检,再进入 Agent Core;模型和工具产生的事件最后回到 TUI、print、RPC 或 SDK。
还是那个例子:用户输入“修复这个失败测试”。
第一站不是模型,而是 AgentSession.prompt()。这一步先做产品层 preflight。
它会先判断这是不是 extension command。如果用户输入的是某个扩展注册的命令,runtime 可以直接交给扩展处理,而不是进入模型。接着,它会触发 extension input hook,允许扩展拦截或改写输入。然后它会展开 skill command 和 prompt template,把用户短输入变成更完整的任务说明。
如果 agent 正在 streaming,新的输入也不能随便插进去。Pi 会要求调用方明确选择 streaming behavior:是作为 steer 在下一轮前插入,还是作为 follow-up 等当前任务结束后再继续。这个设计很小,但很关键:它让“用户中途插话”有了明确进入时机,而不是随机打断上下文。
如果当前没有运行中的 agent,AgentSession 会继续检查模型和认证状态,必要时先处理 compaction,再构造真正要交给 agent core 的 user message。这里还会触发 before_agent_start hook,让扩展有机会追加 custom message 或临时修改 system prompt。
到这一步,通用 Agent.prompt() 才接管。Agent core 看到的已经不是原始用户输入,而是一组整理后的 messages、tools、model、system prompt、AbortSignal、steering/follow-up 队列和事件订阅者。
接下来进入 agent loop。Pi 的 loop 可以拆成两个循环。
内层循环处理“模型还在推进当前任务”的情况:流式接收 assistant message;如果模型产生 tool call,就执行工具;把 tool result 写入 messages;再开始下一轮模型调用。只要还有 tool call,任务就继续。
外层循环处理“agent 本来要停了,但还有 follow-up”的情况:如果用户排了后续消息,runtime 会把 follow-up 变成下一轮 pending message,继续跑同一个 agent。
最后,这一串事件会回到 mode adapter。interactive mode 渲染到终端,print mode 输出文本或 JSON,RPC mode 发给外部进程,SDK mode 交给调用方。同一套 runtime,可以被不同产品外壳复用。
Runtime 里的几类状态

这张图说明:这张图解释为什么不能只用一份 messages 理解 runtime。模型视图、运行状态、会话状态、扩展状态和界面事件各有用途,混在一起会让长任务难以恢复和复盘。
很多人会把 agent runtime 简化成一个 messages[]。Pi 实际维护的是几类状态。
模型可见状态:system prompt、user message、assistant message、tool result,以及经过 convertToLlm 后真正送入 provider 的消息。
运行时状态:当前是否 streaming、正在生成的 assistant message、pending tool calls、error message、AbortController、steering queue、follow-up queue。
产品会话状态:session id、session file、当前 cwd、分支历史、compaction entry、loaded skills、context files、extensions、model registry 和 settings。
界面事件状态:message_start、message_update、message_end、tool_execution_start、tool_execution_end、turn_start、turn_end、agent_end,以及 session_info_changed、compaction_start、compaction_end 这类产品事件。
这些状态不是同一回事。模型只需要看到被整理后的上下文;TUI 需要看到过程事件;session manager 需要能恢复和导出;extension runtime 需要在特定时机介入。Runtime 的价值,就在于把这些状态分开,又让它们在一条任务链路里协同。
Agent Core 的边界
从机制上看,通用 Agent 负责几件事。
第一,它持有 mutable state:system prompt、model、thinking level、tools、messages、streaming message、pending tool calls 和 error message。
第二,它提供运行入口:prompt() 开始一轮新任务,continue() 从当前 transcript 继续,steer() 把用户插话放进 steering queue,followUp() 把后续消息放进 follow-up queue,abort() 终止当前 run。
第三,它把具体 loop 委托给 runAgentLoop() 和 runAgentLoopContinue()。这意味着 Agent 本身是一个状态包装器,真正的 turn 推进逻辑在 agent-loop 里。
第四,它通过事件把内部过程暴露出去。上层 mode 不需要猜模型现在在干什么,只要订阅事件:message 开始了、文本 delta 来了、tool call 开始了、工具结果返回了、turn 结束了。
这个边界让 agent core 可以保持通用,不被 coding agent 的产品细节污染。做其他类型的 agent 时,也可以复用相似的 core loop,只换掉工具和产品 session。
Agent Loop 的运行过程

这张图说明:这张图对应 Agent core 的责任。它不关心界面长什么样,而是反复完成“准备上下文、接收模型流、执行工具、回填结果、进入下一轮”。
agent loop 最值得关注的,是它怎样把一次任务拆成多个 turn。
一轮开始时,runtime 先 emit agent_start 和 turn_start,把用户 prompt 写入上下文。然后它调用 streamAssistantResponse()。这一步才会把 AgentMessage 转成 provider 可接受的 Message,并调用模型 stream。
模型 stream 过程中,runtime 不只是等最终结果。它会不断处理 start、text_delta、thinking_delta、toolcall_delta、done、error 等事件,把 partial assistant message 更新到当前 context,并向外 emit message_update。TUI 能实时显示模型正在说什么,就是因为这里不是一次性返回字符串。
如果 assistant message 里有 tool call,runtime 会进入工具执行阶段。Pi 会先判断工具是否要求 sequential execution;如果没有,就可以并行执行多个 tool call。每个 tool call 都会经过参数校验、beforeToolCall hook、实际执行、afterToolCall hook、tool result message 生成。最后 tool result 被写回 currentContext.messages,下一轮模型才能看见工具执行结果。
每个 turn 结束后,runtime 还会调用 prepareNextTurn()。这是产品层插入 compaction、模型切换、thinking level 调整等逻辑的关键位置。然后它检查是否 should stop;如果不停止,就继续下一轮。
Pi 的 loop 不只是“模型返回工具调用 → 执行工具”。它是一个事件化、可插 hook、可中断、可继续、可记录的运行过程。
AgentSession 的产品能力

这张图说明:这张图说明 AgentSession 为什么不是多余的一层。通用 core 只能推进任务;要成为 coding agent,还要补上项目规则、工具注册、扩展、压缩、恢复和会话生命周期。
只有 Agent core,Pi 可以跑一个抽象 agent,但还不是一个 coding agent 产品。AgentSession 补上的是项目环境、工具、扩展、压缩和会话生命周期。
它会构造 system prompt。这个 prompt 不是硬编码的一段话,而是由 cwd、skills、context files、自定义 prompt、已启用工具、tool snippets、prompt guidelines 等信息共同生成。也就是说,用户在不同项目目录里启动 Pi,模型看到的“工作规则”可以不同。
它会管理工具。基础工具可能包括 read、bash、edit、write,但 AgentSession 还要处理 tool definition、extension 注册的工具、自定义 SDK 工具、工具 allowlist 和当前 active tools。模型只看到工具 schema;runtime 要维护工具从哪里来、怎么执行、怎么展示。
它会处理扩展。扩展可以注册 command、input hook、before_agent_start hook、before/after tool hook、UI context 和 shutdown handler。这让外部能力可以进入 runtime,但不是随便改全局状态,而是在明确生命周期点上介入。
它会处理 compaction。长任务里,历史上下文会越来越大。AgentSession 会在 prompt 前或 agent run 后检查是否需要压缩,把旧历史整理成 checkpoint,再让 agent continue。这个能力不属于通用 loop,却决定了长任务能不能继续跑。
它会处理 session lifecycle。new session 创建新的运行现场;fork/clone 从已有历史分出新路径;switch 切换当前工作现场;dispose 释放订阅、UI 和后台资源。session 不是聊天文件,而是一组 runtime resources 的生命周期。
设计边界
自己做 harness 时,先守住三个边界:Agent core 推进任务,ProductSession 组织运行环境,Mode adapter 处理输入和输出。TUI、RPC、SDK 可以很复杂,但它们不应该复制 agent loop。
设计取舍
Core 与产品层分离
Pi 把 agent 和 coding-agent 分开,代价是调用链看起来更长。好处是通用 loop 不需要认识所有产品概念。这个取舍很适合学习:你能清楚看到“agent 怎么跑”和“coding agent 怎么成为产品”是两件事。
多种入口共用 runtime
interactive、print、RPC、SDK 的用户体验不同,但它们尽量共用 AgentSession。这样可以避免每个入口都有自己的工具执行、session 写入和错误处理逻辑。对 OpenClaw 这类多 channel 系统来说,这一点尤其重要:channel 可以很多,agent runtime 最好只有一套。
用户插话要排队,而不是乱入
steering 和 follow-up 的区别,看起来只是两个 queue,但背后是运行时语义:用户现在说的话,是要影响下一轮模型判断,还是等当前任务自然结束后再开始?没有这个语义,长任务里的交互会变得不可预测。
session 是运行环境,不只是历史文件
session 切换时,Pi 需要重建 cwd-bound services,恢复资源、工具、上下文和事件订阅。也就是说,session 不只是 messages.jsonl,而是一整个运行现场。后面的 Session Tree 文章会展开这一点。
常见误区
误区一:Runtime 就是 CLI 入口。
不是。CLI 只是入口之一。真正的 runtime 在 CLI 后面,负责组织模型、工具、状态和事件。把 runtime 写死在 CLI 里,后面接 RPC、SDK、Web UI 或 channel gateway 时都会痛苦。
误区二:Agent core 越懂产品越好。
不一定。core 太懂产品,短期写起来方便,长期会变成泥球。Pi 的分层提醒我们:通用 loop 只处理通用问题,产品细节留给 session/runtime wrapper。
误区三:工具执行只是函数调用。
真实工具执行还包括参数校验、权限、执行模式、事件展示、错误包装、结果回填和中断处理。模型只发起 tool call,runtime 才是执行者。
误区四:TUI 只是打印日志。
TUI 接的是 runtime event stream。它要展示 streaming message、tool execution、queue update、compaction、错误和 session 状态。如果 runtime 事件设计不好,界面会很难做准。
小结
如果只记住一句话:Agent Runtime 是模型外面的调度系统;Agent core 负责推进任务,AgentSession 负责把任务放进真实产品环境。
读 Pi 的时候,可以按这条线追:用户输入先进入 AgentSession,经过 command、template、extension、auth、compaction 等 preflight;再进入 Agent core;Agent loop 负责模型流、工具执行和 turn 推进;最后事件回到 TUI、print、RPC 或 SDK。
这条线看懂之后,后面的 Message Flow、Session Turn Loop、Tool Runtime、Session Tree 和 OpenClaw embedded agent 都会顺很多。因为你已经知道:agent 产品的底层问题不是“怎么调用一次模型”,而是“怎么让模型在一个可恢复、可扩展、可观察的运行现场里持续工作”。
实现里的三层协作
仔细看 Pi 的实现,会发现 Agent Runtime 不是一个“调用模型的函数”,而是三层协作。最底层的 Agent 负责一次正在运行的循环:保存消息、模型、工具、streaming 状态、pending tool calls,以及用户运行中插入的 steer / follow-up 队列。它像发动机,只关心任务如何继续。
中间的 AgentSession 把这个发动机放进真实产品现场。它负责 prompt 预检、模型和认证检查、扩展 input hook、skill/template 展开、自动重试、自动压缩、工具注册、事件持久化、bash 输出延迟回填,以及 session 分支和导出。也就是说,它处理的是“这个 agent 在一个真实项目里怎么稳定工作”。
最外层还有 Session Runtime。它处理 new、resume、fork、switch 这类会话替换动作。切换会话时,Pi 不是简单换一个文件名,而是先通知扩展、关闭旧 session、让旧 UI 绑定失效、重建当前目录相关的服务,再把 UI 或 RPC 重新绑定到新 session。
很多 agent 产品一开始会把模型调用、工具执行、UI、session、配置读取都塞进一个入口函数里。短期能跑,后期一加 RPC、SDK、插件、历史恢复,就会到处复制逻辑。Pi 的做法更像搭底盘:核心循环、产品会话、会话运行时分别负责不同层级的问题。
如何阅读一个 Agent Runtime
看一个 agent 产品时,不要只问“它用哪个模型”。更关键的问题是:用户输入进入哪里,模型输出在哪里被执行,工具结果在哪里回填,session 在哪里持久化,UI 订阅的是最终文本还是运行事件,会话切换时旧状态会不会泄漏。
如果这些问题没有清楚答案,系统大概率只能处理短任务。一旦任务变成长链路,或者要接多个入口,运行时边界就会成为真正的瓶颈。