Pi Agent 101|00|Reading Guide
写给 Agent Harness 入门者和 OpenClaw 读者的 Pi Agent 101 导读:先用最基础的概念看懂 agent 底盘,再进入 runtime、工具、会话、上下文和产品化。
如果你第一次听到 Agent Harness,可以先把它想成一个给大模型准备好的工作台。
模型本身只会生成文字。它可以说“我想读这个文件”“我想运行测试”“我认为下一步应该修改这里”,但它不会自己真的打开文件、执行命令、保存历史,也不会自己知道终端界面上应该显示什么。Harness 要做的事,就是把模型的想法接到真实工作环境里。
这也是很多人第一次理解 Agent 时容易卡住的地方。我们平时说“Agent 会自己做任务”,听起来像模型变聪明了。实际上,更准确的说法是:模型仍然是模型,真正让它能持续做事的,是一套围绕它搭起来的运行系统。这套系统要负责上下文、工具、会话、错误恢复、用户中断、界面展示和结果复盘。
Pi 适合拿来学习这件事。它不算巨型系统,但边界很完整。你能从它身上看到一个本地 coding agent 为什么不只是一个聊天窗口:它有运行循环,有工具执行,有会话历史,有模型适配,有终端 UI,也有扩展机制。对入门者来说,这比一上来研究一个大型商业产品更容易建立直觉。
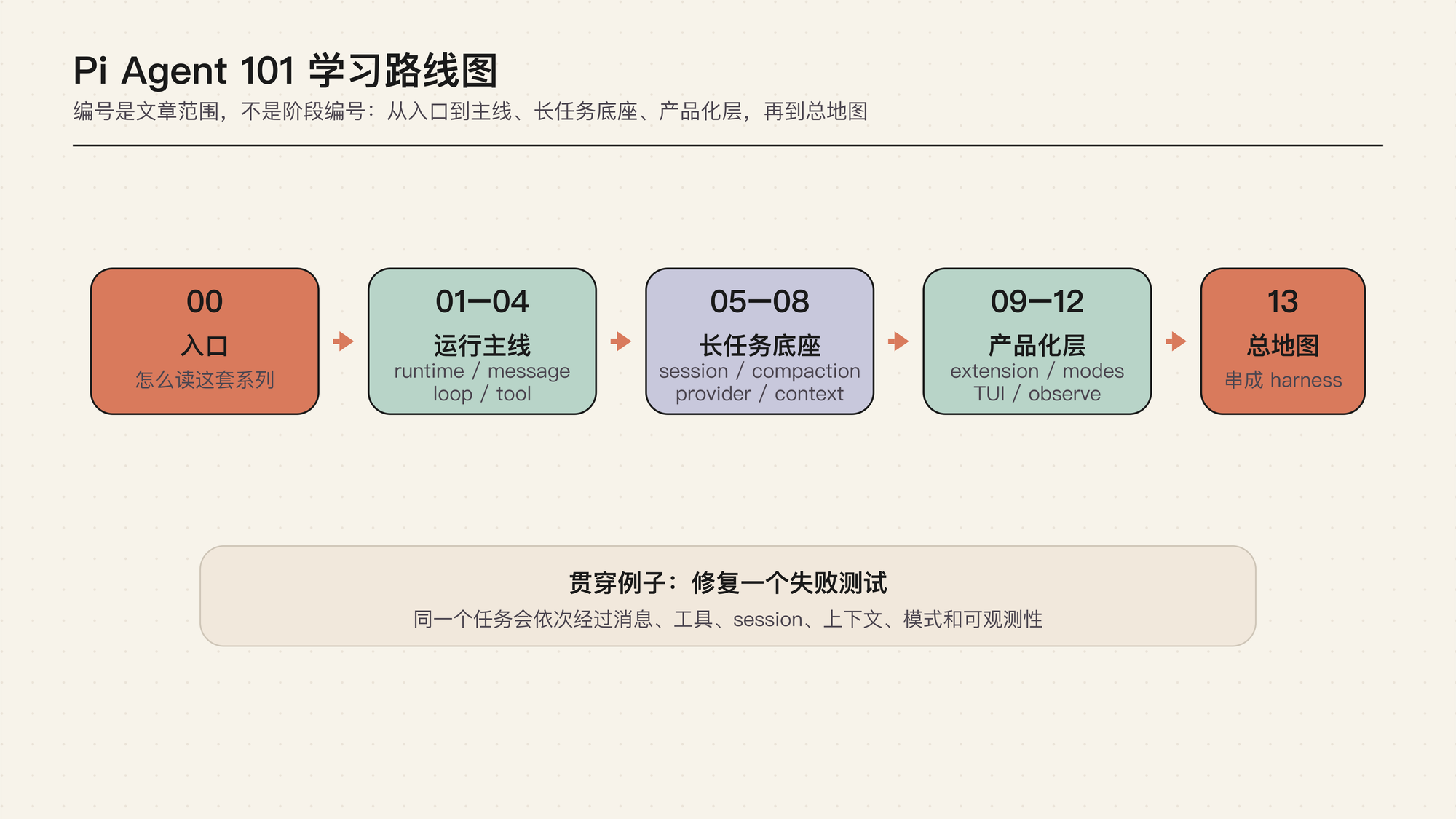
这张路线图不要当成普通目录看,而要当成学习路径看。前四篇先建立“agent 怎么跑”的直觉:Runtime 负责组织现场,Message Flow 说明哪些事实能进入模型,Session Turn Loop 解释任务为什么会一轮一轮推进,Tool Runtime 则回答模型提出行动之后谁真正执行。
中间四篇开始进入长任务:Session Tree 解决恢复和分支,Context Compaction 解决上下文变长,Provider Abstraction 解决模型厂商差异,Context Files and Skills 解决项目规则和可复用能力怎么进入 prompt。
最后五篇更接近产品化:Extension Runtime 让外部能力进来,Mode Adapters 让同一套 runtime 接到不同入口,Terminal UI Runtime 把事件变成界面,Observability and Sharing 让过程可复盘,最后的总地图把所有边界重新拼回一个 Agent Harness。
先从一个普通任务开始
假设你对一个 coding agent 说:“帮我修一下这个失败的测试。”
这句话很短,但对 agent 来说,它不是一个简单问答。它至少要完成几件事:
第一,它要知道当前项目在哪里,测试失败意味着什么,用户想要的是修复问题,而不是随便解释一段报错。
第二,它要决定先看什么信息。也许要读测试文件,也许要读被测试的实现,也许要先运行测试确认失败现场。
第三,它要请求工具。模型不能自己读文件,它只能产生“我要读文件”这样的意图。真正去文件系统读取内容的是本地运行时。
第四,它要把工具结果重新交给模型。模型看到文件内容或测试输出后,才能继续判断下一步该做什么。
第五,它可能要重复很多轮。读文件、分析、修改、运行测试、看失败、再修改,这不是一次回答能完成的。
第六,它要保存过程。否则任务中断后无法恢复,用户也无法知道它到底做过什么。
第七,如果任务很长,上下文会越来越大。运行时必须决定哪些历史保留原文,哪些历史压缩成摘要。
第八,用户需要看见过程。终端里不能只显示一大坨文本,而要展示模型在思考、工具在执行、测试输出是什么、哪里出错了。
这就是 Agent Harness 的意义。它不是让模型“更像人”,而是给模型配了一套可以持续工作的工程环境。

这张图说明:这张图把“修复一个失败测试”拆成五步。先有失败现场,agent 读取信息,然后尝试修改,再运行验证,最后留下可以复盘的过程。后面每篇文章都会围绕这条路径解释一个具体边界。
本文结构
如果你只有最基础的 LLM 知识,可以先记住一句话:Agent 不是“模型自动回答问题”,而是“模型、工具、上下文、会话历史和产品界面一起配合完成任务”。
这里面每个词都很重要。
模型负责生成下一步建议。它像任务里的“判断者”。
工具负责接触真实世界。它可以读文件、写文件、运行命令、查询外部信息。工具像“手”。
上下文负责告诉模型当前知道什么。它像一张临时工作纸,上面写着用户目标、项目规则、刚才读到的内容和工具返回的结果。
会话历史负责保存整个过程。它像工作日志,不只是聊天内容,还包括工具调用、测试输出、压缩摘要、分支尝试和错误记录。
产品界面负责让用户看见并介入。它可以是终端,也可以是网页、IDE、聊天窗口或 RPC 宿主。

这张图说明:这张图不是在讲技术实现,而是在帮你建立心智模型。不要把 Agent 看成一个黑盒模型,要把它看成几类责任的组合:模型判断、工具行动、上下文组织、会话保存、界面反馈。
这组文章写给谁
第一类读者,是想入门 Agent Harness 的同学。
你可能已经知道 LLM 可以调用工具,也见过模型输出结构化请求让系统去执行。但你还没完全看清:一个本地 agent 到底怎么把模型、工具、文件系统、会话记录和 UI 串起来。这组文章会尽量从基础概念讲起,不要求你先懂完整 agent 框架。
第二类读者,是正在看 OpenClaw 的同学。
OpenClaw 上层有很多产品能力,例如 channel、plugin、gateway、provider、media、voice、proxy、session export。第一次看这些能力时,很容易觉得它们是一堆分散模块。更好的入口,是先理解底下那层 agent 底盘:一次 agent run 如何开始,工具如何执行,transcript 如何形成,provider stream 如何进入统一事件,UI 如何展示过程。
第三类读者,是想自己做一个最小 coding agent 的工程师。
你不一定要复制 Pi 的实现。更重要的是借它回答一些早晚会遇到的问题:消息怎么存,工具怎么跑,session 怎么恢复,上下文怎么压缩,扩展怎么进来,UI 怎么跟着模型流动,出问题后怎么复盘。
第四类读者,是产品经理或技术负责人。
你可能不关心每个模块怎么写,但你需要判断一个 agent 产品是否真的有底盘。它是否能恢复任务?是否能解释过程?是否能处理工具失败?是否能在不同模型之间切换?是否能在终端、RPC、SDK、聊天入口之间复用同一套运行逻辑?这些都不是“模型选型”能单独解决的问题。
先给一张四圈地图

读这组文章时,可以先把 Agent Harness 想成四圈。
最里面是模型。它负责生成文本、计划和工具调用。它很重要,但它不是全部。
第二圈是 runtime。它负责把用户输入变成一次可运行的任务,把模型输出变成事件,把工具结果重新放回上下文,把一轮一轮的工作组织起来。
第三圈是状态和扩展。这里包括 session、compaction、skills、provider registry、extensions。它们决定 agent 能不能做长任务,能不能恢复,能不能适应不同项目和不同模型。
最外圈是产品界面。这里包括 TUI、RPC、SDK、导出、分享,以及 OpenClaw 里更上层的 channel、plugin、gateway、可观测和多媒体能力。
后面每一篇其实都在讲其中一圈,或者两圈之间的边界。先有这张地图,再读具体机制,就不容易把“模型能力”“runtime 能力”和“产品外壳”混在一起。

这张图说明:这张图把学习顺序拆成五段。先读入口和基础循环,再读长任务状态,然后看产品化能力,最后回到总地图。这样读,知识不会散成一堆术语。
不要一开始就追实现细节
很多工程师读这种系统时,会习惯马上问:“对应哪个文件?哪个函数?调用链在哪里?”
这种读法不是不对,但对入门者不友好。因为你还没建立边界之前,直接追实现细节,很容易只记住一堆名字,却不知道它们为什么存在。
这组文章建议你反过来读:先问“它解决什么问题”。
为什么需要 Agent Runtime?因为用户输入不能直接扔给模型,必须先组织现场。
为什么需要 Message Flow?因为系统内部事实、模型可见上下文、用户界面展示不是同一种东西。
为什么需要 Turn Loop?因为真实任务不是一问一答,而是一轮模型判断、一轮工具执行、再一轮模型判断。
为什么需要 Tool Runtime?因为模型提出行动,但真正执行行动的是本地环境,必须有校验、权限、错误包装和结果回填。
为什么需要 Session Tree?因为长任务常常要回退、分支、比较不同尝试。
为什么需要 Context Compaction?因为模型上下文不是无限的,长任务必须把旧过程整理成可继续工作的摘要。
为什么需要 Provider Abstraction?因为不同模型厂商接口不一样,不能让上层产品到处处理差异。
为什么需要 Context Files and Skills?因为 agent 必须知道当前项目规则和可复用任务方法。
为什么需要 Extension Runtime?因为产品不可能把所有能力都写死在核心里。
为什么需要 Mode Adapters?因为同一套 agent 底座要服务终端、脚本、RPC 和 SDK。
为什么需要 Terminal UI Runtime?因为长任务需要实时可见、可中断、可选择、可复盘的界面。
为什么需要 Observability and Sharing?因为 agent 的过程记录是调试、信任和改进的证据。

这张图说明:不要把这组文章读成“背名字、找文件、照抄实现”。如果只记实现细节,不理解边界,换到 Claude Code、Codex CLI、Cursor 或 OpenClaw 时还是会迷路。
应该怎么读
更好的读法,是每篇只抓三件事。
第一,这篇文章讲的是哪一个边界。
边界的意思是:谁负责什么,谁不该负责什么。比如工具执行不是模型负责;模型只提出请求,真正执行由 runtime 完成。再比如 session 不是 UI 滚动文本;它是可恢复、可分支、可压缩的历史结构。
第二,这个边界如果不存在,产品会出现什么问题。
如果没有清晰 Message Flow,日志、工具结果、压缩摘要和模型上下文会混在一起。结果可能是 prompt 变得臃肿,模型看到不该看的内容,或者用户界面无法解释 agent 做过什么。
如果没有 Tool Runtime,模型的工具调用会变得危险。它可能用错参数,失败后无法继续,或者并发修改同一个文件。
如果没有 Session Tree,用户回到历史点重试时只能覆盖旧记录,任务复盘会断掉。
第三,这个边界和“修复失败测试”这个例子有什么关系。
读到 Agent Runtime,就想:用户说“修测试”后,任务如何启动?
读到 Message Flow,就想:测试输出、文件内容、模型回答、UI 事件分别会去哪里?
读到 Tool Runtime,就想:读文件、改文件、跑测试是谁执行的?失败后如何继续?
读到 Context Compaction,就想:修了很久以后,前面的尝试如何压缩成仍然有用的现场说明?

这张图说明:这张图给出推荐读法。先问目的,再看边界,再看失败模式,最后才看如何迁移到别的产品或自己的系统。
产品对照速查
如果你已经接触过一些 agent 产品,可以用下面这组对照帮助理解。
Claude Code / Codex CLI:重点看终端里的 agent loop、tool runtime、session、compaction 和 TUI 事件。你在终端里看到的“模型正在做事”,背后通常就是这些边界在配合。
Cursor:重点看 IDE 里的上下文选择、文件编辑、工具执行和模型状态管理。IDE 产品的体验更图形化,但底层仍然要回答:模型看到哪些上下文,文件修改如何发生,结果如何回填。
OpenClaw:channel、plugin、gateway 是产品外壳;agent run、transcript、provider、trajectory 才是底层边界。先理解 Pi 的底盘,再看 OpenClaw 的上层能力,会更容易分清哪些是入口,哪些是核心运行机制。
自己做 Harness:先搭 runtime、context builder、tool runtime、session store、provider adapter,再加 UI。不要从“做一个漂亮聊天框”开始,否则很容易把真正的运行时问题藏到界面后面。
推荐阅读顺序
第一次读,抓住一件事:一条用户消息先进入调度系统,而不是直接进模型。你要看懂 runtime 如何准备现场、检查模型、加载工具、绑定会话,并启动一次 agent run。
第一次读,抓住一件事:运行时事实和模型可见消息不是一回事。一个系统可以保存很多事件,但模型每轮看到的只是整理后的上下文。
第一次读,抓住一件事:模型想一步,runtime 做一步,再把结果交回模型。一次用户请求可能包含多次 turn。
第一次读,抓住一件事:模型提出行动,本地 runtime 负责执行。工具执行要有校验、权限、取消、错误包装和结果回填。
第一次读,抓住一件事:session 更像可分支历史,不像聊天数组。用户可以从历史点重新尝试,而旧路径仍然保留。
第一次读,抓住一件事:历史太长时,先做摘要 checkpoint。压缩不是删除历史,而是改变模型下一轮看到的工作现场。
第一次读,抓住一件事:不同模型厂商要收口成统一事件流。这样上层 runtime 才不需要到处写厂商判断。
第一次读,抓住一件事:system prompt 来自当前工作环境。项目规则、技能手册、提示模板和工具说明都可能参与组装。
第一次读,抓住一件事:外部能力要安全进入 runtime。扩展可以注册能力,也可以参与事件,但必须受生命周期和上下文边界约束。
第一次读,抓住一件事:TUI、print、RPC、SDK 只是不同外壳。底层 agent runtime 不应该为每个入口复制一套。
第一次读,抓住一件事:终端是界面系统,不是简单输出文本。长任务需要实时状态、输入焦点、overlay、选择器和恢复能力。
第一次读,抓住一件事:agent 的过程记录和最终答案一样重要。没有过程证据,就很难调试、信任和改进 agent。
最后再读总地图,把前面所有边界重新拼起来。到这里,你应该能回答:一个 agent 从用户输入到工具执行、从上下文压缩到会话导出,完整链路到底有哪些环节。
这组文章怎么处理实现细节
这组文章背后会认真看 Pi 的实现,但正文不会写成实现细节笔记。读者不需要知道某个函数在哪个文件里,也不需要跟着一行行追实现。
更好的读法是:把 Pi 当成一个清晰的样板系统。我们从它的实现里抽出机制边界,再用更通俗的语言解释这些边界为什么存在、坏了会怎样、迁移到 Claude Code、Codex CLI、Cursor 或 OpenClaw 这类产品时应该怎么看。
所以你会看到图、运行路径、状态边界、失败模式和产品类比,而不是代码清单。
第一次读,只抓三件事
第一,agent harness 不是模型。
模型只负责生成下一段文本或工具调用;harness 负责把它放进真实工作流。一个好的模型可以让 agent 更聪明,但没有 harness,它仍然无法稳定完成长任务。
第二,session 不是聊天记录。
它要保存用户消息、模型输出、工具调用、工具结果、压缩摘要、分支和自定义事件。模型每一轮看到的,只是从这些事实里整理出来的一份上下文。
第三,工具不是模型能力。
工具是本地 runtime 的能力。模型只能提出“我要做什么”,真正执行、校验、记录和回填结果的是 runtime。
小结
Pi Agent 101 的目标,是帮你看懂一个最小但完整的 Agent Harness。读完之后,再看 OpenClaw 这类更大的系统时,你会更容易分清:哪些是产品能力,哪些是 plugin、channel、gateway 这样的外壳,哪些才是 agent 真正跑起来需要的底层机制。
如果你只记住一句话,就记住这句:Agent 的关键不只是模型会不会思考,而是有没有一套运行时把思考变成可执行、可恢复、可观察、可复盘的工作过程。