LoopLens:看见 Claude Code 和 Codex 如何运行
LoopLens 是一个本地调试工作台,用来把 Claude Code 和 Codex 一次运行里的模型请求、工具调用、hooks、网络流量、token 与 compact 边界串起来看。

用 Claude Code 或 Codex 做开发时,最容易让人困惑的不是它们最后答了什么,而是中间到底发生了什么。
你在终端里输入一个需求。接下来,工具开始读文件、查上下文、调用命令、访问 MCP、请求模型、等待权限,有时候还会压缩上下文。几分钟后,它给出一个结果。结果对了,当然很好;结果不对,问题就来了。
它是没有读到关键文件?是模型判断错了?是工具调用被权限挡住了?是某个请求失败了?还是上下文太长,compact 之后把重要信息丢掉了?
只看终端 transcript,很多时候只能猜。
LoopLens 做的事情很朴素:把 Claude Code 和 Codex 一次运行里的这些证据收集起来,按 Agent Loop 的方式重新排好,让你能一步一步看。
为什么需要一个这样的工具
传统调试里,我们习惯看日志、看请求、看错误栈。服务端出了问题,顺着 trace 往下查,通常能找到一个比较明确的位置。
Agent CLI 不太一样。
一次运行里同时有模型判断、工具调用、本地文件状态、网络请求、hook 事件、token 消耗和上下文压缩。它们不是彼此独立的日志,而是互相影响的一条链。
比如,一个 tool call 没有执行,可能不是模型没想到,而是权限阶段拦住了。一个回答突然变差,可能不是模型能力问题,而是 compact 之后上下文换了。一个 run 看起来慢,可能不是网络慢,而是某一步塞进了过大的 tool result。
这些问题都需要把事件放回同一条时间线里看。
LoopLens 的出发点就在这里。它不把网络包当作终点,也不把 transcript 当作全部。它关心的是:这个证据出现在 Agent Loop 的哪个位置。
它看见的是一次运行
LoopLens 打开后,你可以从桌面应用里启动 Claude Code 或 Codex。每次启动都会创建一个新的 run 边界。这样做的好处是,后面看到的 capture、hooks、session 信息都属于这一次运行,而不是混在一堆历史噪音里。
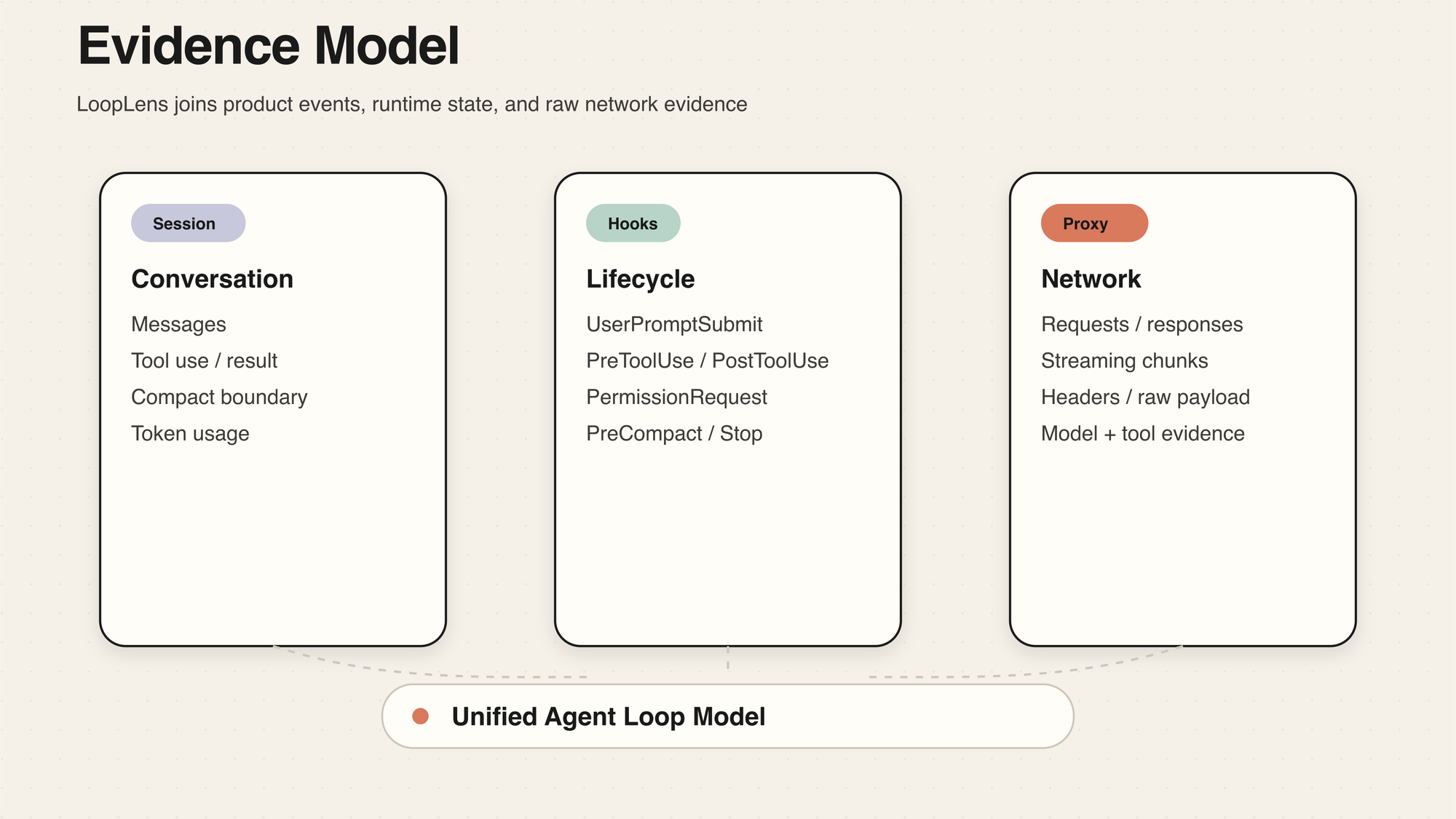
一次 run 里,LoopLens 会尽量把几类东西放到一起:
- Claude session sidecar 里的对话和工具结构;
- Claude Code 或 Codex 产生的 hook 事件;
- 本地代理捕获到的请求、响应和 streaming chunks;
- UI 里重建出来的 turn、step、tokens、diagnostics。
这些东西单独看都不难,真正麻烦的是它们分散在不同地方。LoopLens 的价值,不是把每个 JSON 原样铺开,而是把它们重新组织成一条可读的运行过程。
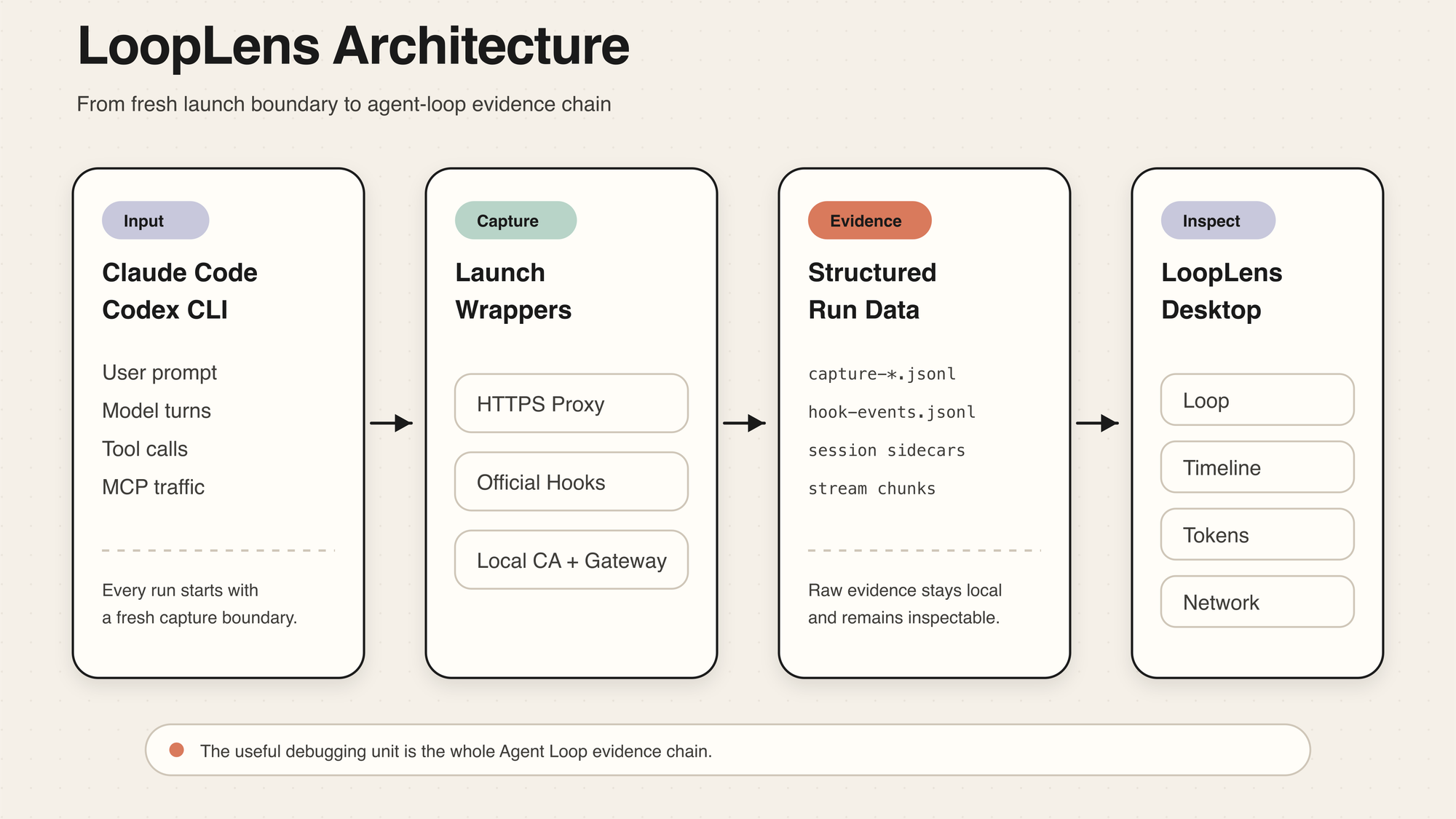
从启动到重建
LoopLens 大致可以分成三层。
第一层是启动。桌面应用里的 Open Claude Code 和 Open Codex 不只是快捷按钮。它们会给这次运行建立一个新的 capture 文件,并通过本地 wrapper 配置代理、CA 和相关环境。这样每次调试都有清晰边界。
第二层是捕获。native proxy 负责记录经过本地代理的请求、响应、streaming chunk、headers 和 raw payload,同时对常见敏感字段做保守脱敏。hooks 则补上网络层看不到的生命周期信息,比如 UserPromptSubmit、PreToolUse、PostToolUse、PreCompact、PostCompact、PermissionRequest、SessionStart、Stop。
第三层是重建。桌面端读取 capture、session sidecar 和 hook events,把它们转成统一的 Agent Loop Model。你看到的不再是一堆文件,而是 User Prompt、Model Step、Tool Batch、Tool、MCP、Skill、Tool Result、Permission、Compact、Network Flow 和 Final Result。
这也是它和普通抓包器的区别。抓包器告诉你请求发生了什么;LoopLens 还想告诉你,这个请求在一次 Agent 运行里扮演了什么角色。
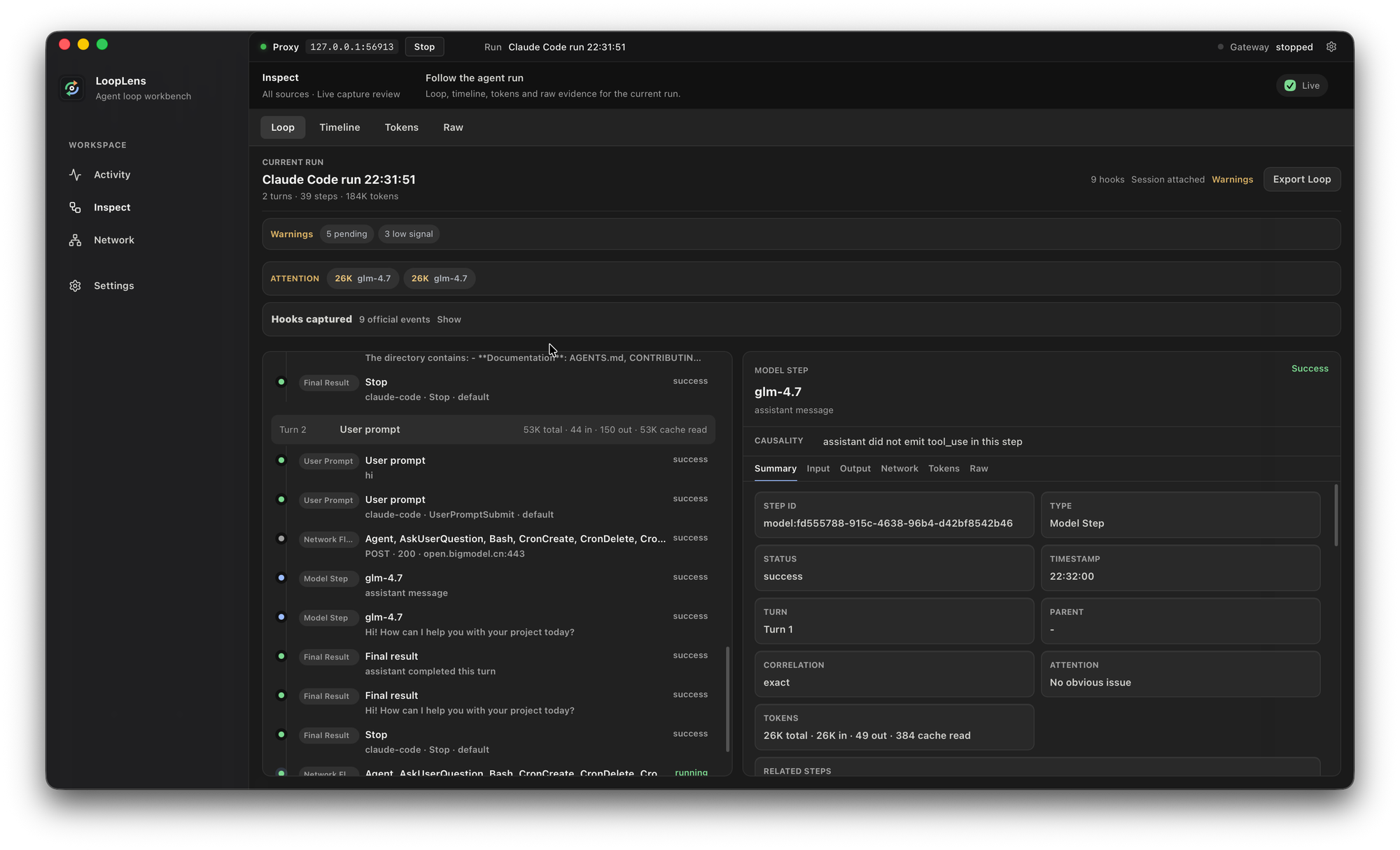
Inspect 视图怎么看
Inspect 视图像一个工作台。
左边是 run 和 step 序列,中间可以切 Loop、Timeline、Tokens、Raw,右边是当前 step 的详细信息。一个 model step 不只是模型输出,还能看到 token、状态、关联步骤和对应网络证据。一个 tool step 也不只是工具名称,它可以和 hook、tool result、MCP 或请求响应连起来。
调试时,你可以先顺着 Loop 看一遍。
哪一步开始偏了?模型有没有发出 tool_use?tool_use 有没有真的执行?工具结果有没有回到下一轮上下文?网络请求有没有失败?token 是在哪一步涨起来的?compact 前后,运行状态有没有明显变化?
这些问题放在一起,才像是在看一次 Agent 运行。分开看,就很容易变成事后脑补。
网络证据仍然要保留
抽象时间线很重要,但不能只剩抽象。
很多时候,问题就在底层 payload 里。请求体少了字段,响应被截断,streaming chunk 顺序异常,token usage 和 UI 显示对不上,或者某个 host 产生了你没预期到的流量。
LoopLens 的 Network Inspector 保留了这条退路。你可以看请求、响应、chunks、headers、raw body,也可以按 model、status、category、host、provider、method、mcp、tool、tokens 等字段搜索。
这点很实用。高层时间线帮你定位“哪一步值得看”,网络证据帮你确认“那一步实际发生了什么”。
hooks 补上生命周期
只看网络,会漏掉很多 Agent 生命周期事件。
比如,模型请求成功了,不代表工具真的执行了;工具准备执行,也可能在权限阶段被拦住;上下文快满了,也可能触发 compact;一次 session 什么时候开始、什么时候停止,也不一定能从 HTTP 请求里看清楚。
hooks 的作用就是把这些节点显式记录下来。
当 hook events、capture 文件和 session 信息放到一起,调试粒度会细很多。你不只是知道“有一个请求成功了”,还可以知道它前后有没有进入工具阶段,有没有权限请求,有没有 compact,有没有 stop。
对于调试 Claude Code 和 Codex,这些信息比单纯看网络更接近真实边界。
token 和 compact 不是事后统计
Agent CLI 的很多问题,最后都会落到上下文上。
一次任务为什么突然变贵?哪一步消耗了最多 token?cache 有没有真正发挥作用?tool result 是不是把大量低价值内容塞回了上下文?compact 是不是发生在一个不合适的位置?
如果这些信息只在事后看一个总数,很难帮你调试。LoopLens 把 token usage、cache read/write、输入输出 token、compact 相关事件尽量放到 turn 和 step 上。这样你看到的不是“这次一共花了多少”,而是“它是怎么一步步花掉的”。
在 Agent 系统里,token 不是账单字段。它会改变上下文,进而改变后面的行为。
一个自然的调试流程
用 LoopLens 调一次 run,大概会是这样的节奏。
先从桌面应用启动 Claude Code 或 Codex,让这次运行有一个干净边界。任务跑起来以后,proxy、hooks 和 session sidecar 会各自记录证据。
如果结果不对,先不要急着翻 raw JSON。先看 Inspect 里的 Loop,找到第一个不对劲的 step。然后切到 Timeline 或 Tokens,看事件顺序和上下文压力。必要时再进入 Network Inspector,看那一步对应的 request、response 或 streaming chunk。
到这里,问题通常会变得清楚一些:它更像是 prompt 问题、工具问题、权限问题、网络问题,还是 context / compact 问题。
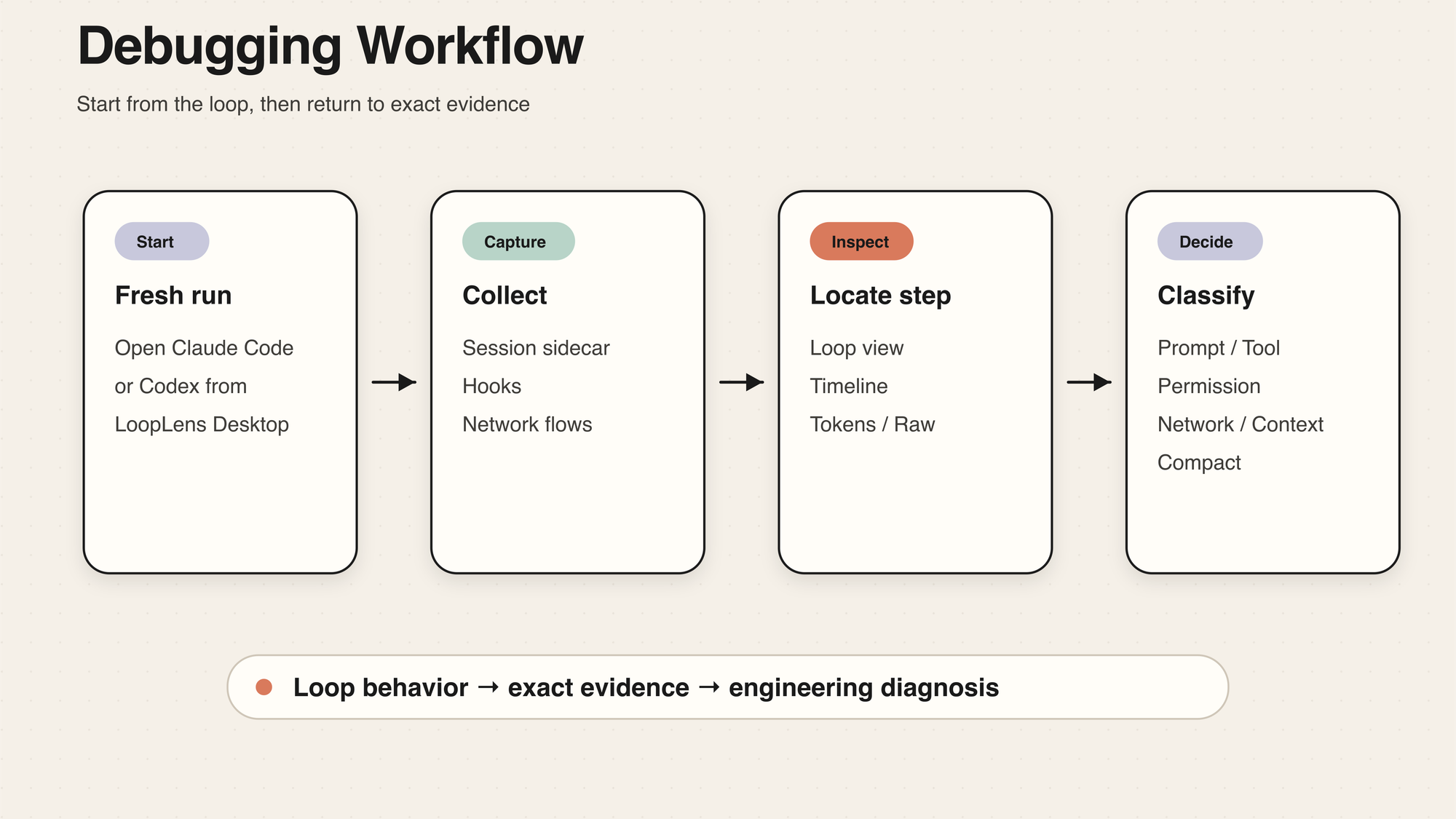
这个流程的重点不是“把所有东西都看一遍”。恰恰相反,它是先用高层时间线缩小范围,再回到底层证据确认。
本地优先,也要小心
LoopLens 是本地工具。capture、hooks、CA、gateway settings 等运行时状态都在本机。项目也明确把这些目录排除在 git 之外。
但本地不等于没有风险。
Capture 文件可能包含 prompt、响应、工具输入、本地路径、headers、metadata,甚至包含模型或工具间接带出的敏感内容。LoopLens 会对常见 secret-bearing headers 和 JSON 字段做保守脱敏,但使用者仍然应该把 capture 当作敏感调试材料处理。
所以它更适合被理解成开发者自己的调试工作台,而不是一个可以随便上传共享的日志平台。你明确把 Claude Code 或 Codex 的运行路由进来,它才记录;需要完整网络证据时,再启用 HTTPS proxy 和本地 CA 信任流程。
谁会需要它
如果你只是想看普通 HTTP 请求,LoopLens 不是最通用的工具。
但如果你经常使用 Claude Code 或 Codex,尤其是已经开始把它们用于真实开发任务,LoopLens 会很有用。它能帮你判断一次失败到底来自 prompt、工具、权限、网络、上下文,还是模型本身。
如果你在做 Agent Runtime、Agent 产品或开发者工具,它也值得一看。因为它把很多抽象概念放到了一个具体产品里:Agent Loop、Tool Runtime、Session、Context、Hook、MCP、Token、Compact,以及这些东西如何在一次运行中互相影响。
它不是为了证明 Agent 有多神奇。它更像一个提醒:当工具开始替你做多步工作时,你需要一种办法看见中间过程。
小结
Claude Code 和 Codex 这类工具越强,终端里的那段对话就越不够用。
结果只是最后一页。真正决定结果的,是中间那些模型判断、工具调用、权限选择、网络请求、上下文变化和 compact 边界。
LoopLens 做的是把这些东西重新串起来。它把一次本地 Agent 运行,从“只能事后猜”,变成“可以沿着证据一步步看”。
这就是它的价值。
参考资料
- LoopLens GitHub Repository: https://github.com/llm-101/LoopLens
- LoopLens Releases: https://github.com/llm-101/LoopLens/releases/latest
- Claude Code Documentation: https://docs.anthropic.com/en/docs/claude-code
- OpenAI Codex: https://openai.com/codex/