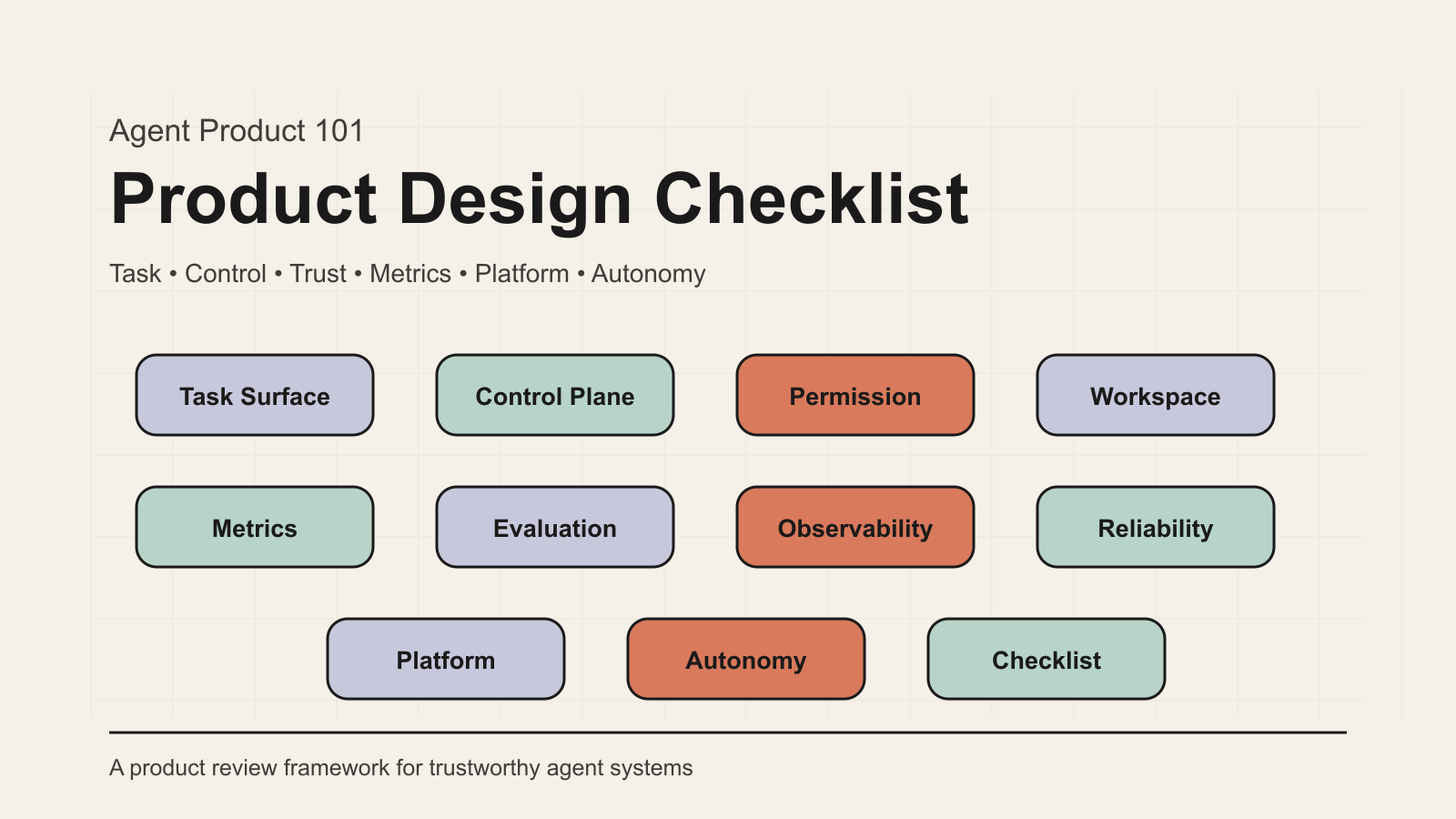
核心结论
Agent 产品设计的核心不是“让模型更聪明”,而是让用户能把真实任务交给系统,并在任务执行过程中看见边界、控制风险、恢复失败、验收结果。
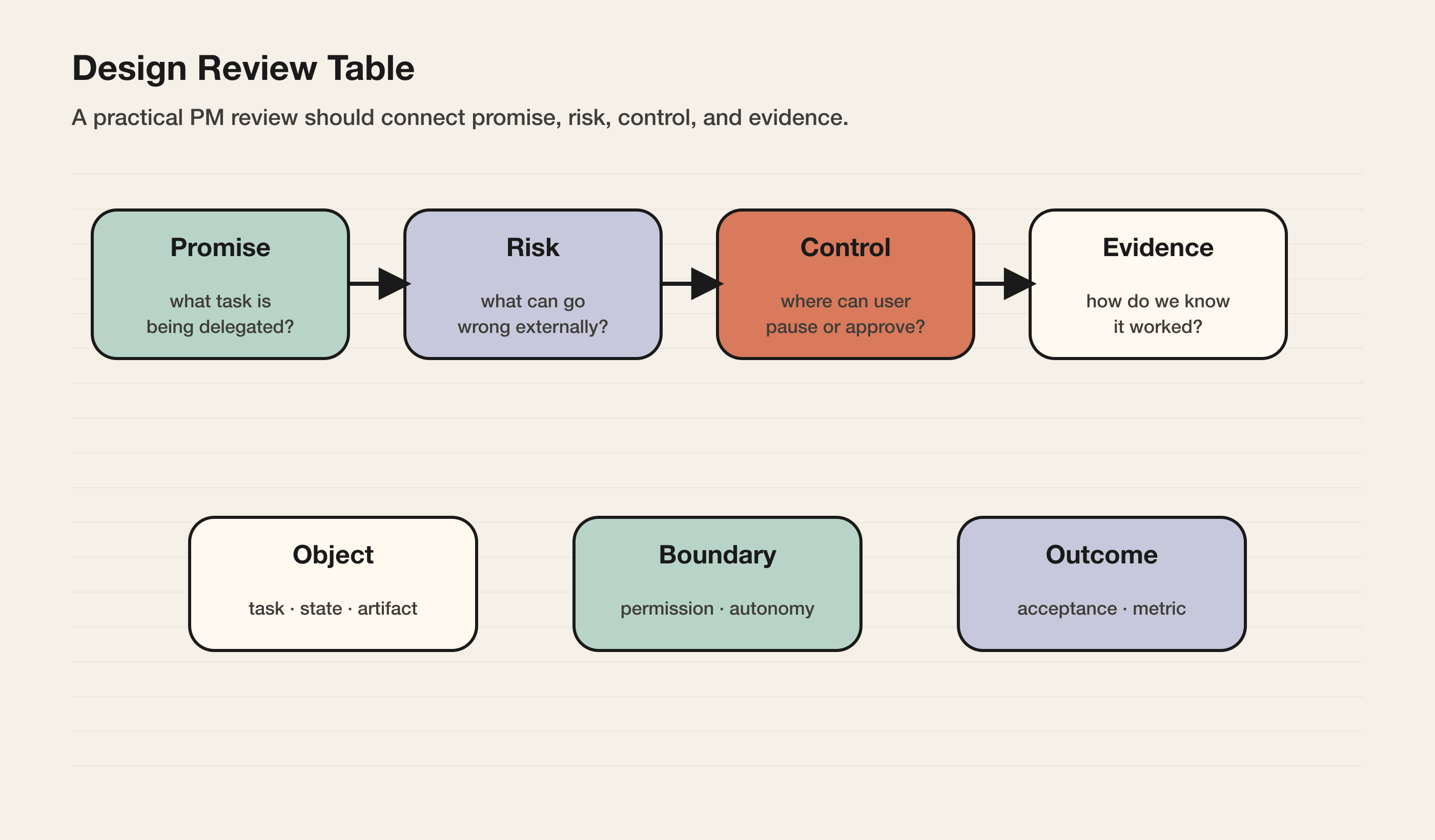
这张总表把 Agent Product 101 的全部文章压缩成一个产品评审框架。它不是为了给团队多加一套文档,而是为了回答一个更直接的问题:这个 Agent 到底是不是一个可以被用户托付任务的产品?
如果一个 Agent 产品无法回答下面这些问题,它大概率还停留在 demo、聊天框或功能集合,而不是一个可交付、可控制、可信任、可运营的产品系统。
如何使用这张总表
不要把它当成一次性 checklist。更好的用法是把它放进 Agent 产品的三个阶段:
| 阶段 | 使用方式 | 核心问题 |
|---|---|---|
| 立项阶段 | 判断产品承诺和任务边界 | 用户到底要委托什么任务? |
| 设计阶段 | 检查任务入口、控制点、权限、工作空间、失败路径 | 用户如何控制和验收? |
| 上线阶段 | 用指标、评估、可观测性和可靠性持续验证 | 这个 Agent 是否真的稳定交付? |
一个简单的使用方式是:每个维度用 0–2 分打分。
| 分数 | 含义 |
|---|---|
| 0 | 没有明确设计,只靠模型或 prompt 硬撑 |
| 1 | 有局部机制,但边界、状态或验收不完整 |
| 2 | 有清晰对象、流程、控制点、恢复路径和衡量方式 |
如果一个 Agent 产品在 Task Surface、Permission Model、Workspace、Reliability 上都是 0 或 1,就不应该贸然提高自主等级。
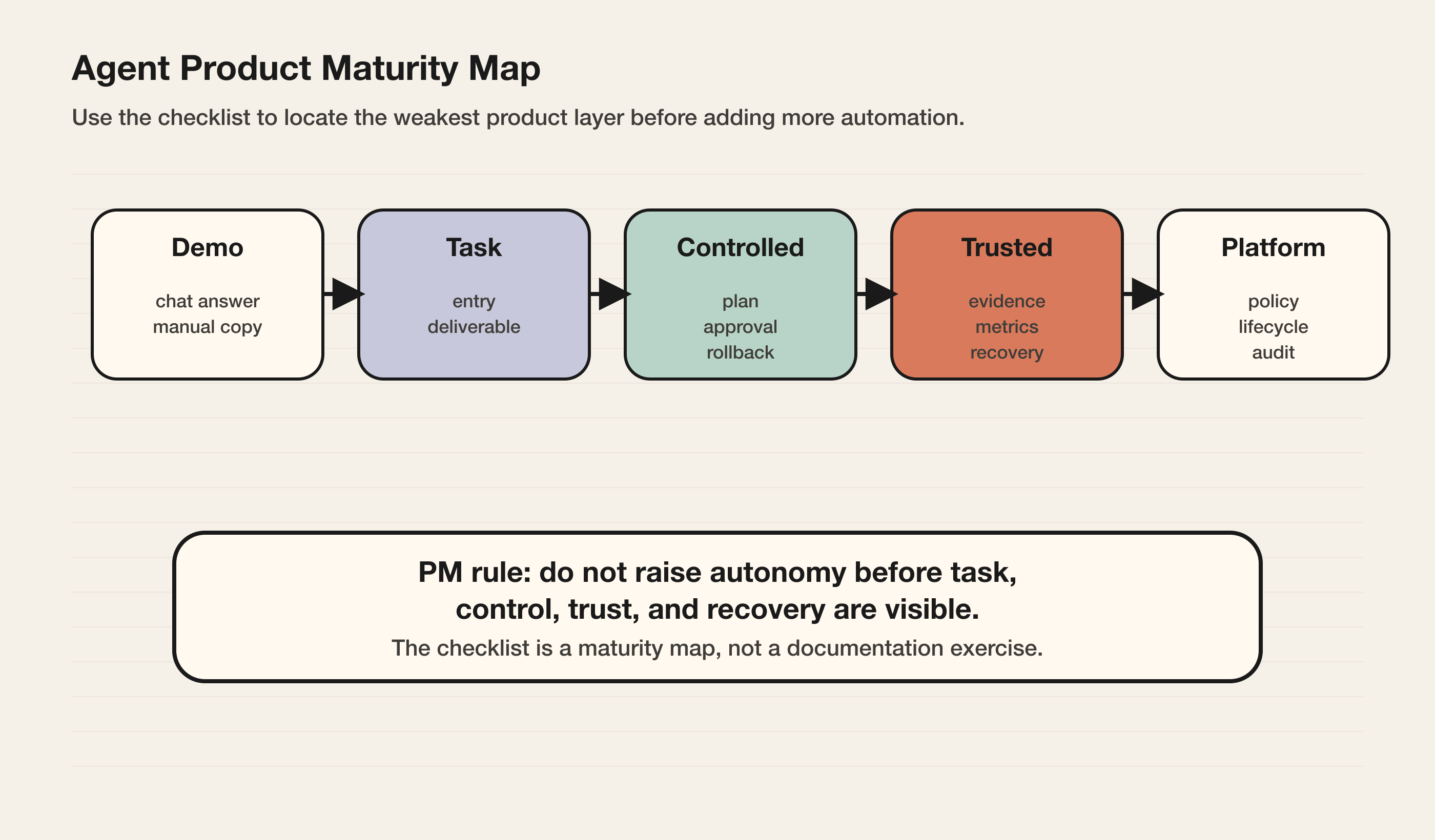
总览:Agent 产品成熟度地图
| 维度 | 低成熟度表现 | 高成熟度表现 |
|---|---|---|
| 产品承诺 | 只说能聊天、能生成、能自动 | 明确任务、交付物和验收方式 |
| 任务入口 | 万能输入框承接所有事情 | 不同入口对应不同上下文和结果 |
| 控制层 | 只有开始和停止 | 有计划、预览、确认、接管、回滚 |
| 人类节点 | 人工介入是异常 | 人类确认、审批、纠错是流程一部分 |
| 权限 | 一个总开关 | 按任务、系统、动作、时间授权 |
| 工作空间 | 状态散在聊天记录 | 有稳定 task object 和 artifact |
| 长任务 | spinner 等待 | queued、running、blocked、done 等状态 |
| 信任 | 用户只能相信 Agent | 用户能看证据、风险和责任边界 |
| 指标 | 看调用量和消息数 | 看任务完成、接受、恢复、复用 |
| 评估 | 离线问答 benchmark | 基于真实任务和失败样本回归 |
| 可观测性 | 只能查后台日志 | 用户、PM、工程、admin 各有视图 |
| 可靠性 | 失败后重来 | checkpoint、retry、rollback、handoff |
| 平台 | 每个 Agent 单独配置 | builder、connector、runtime、policy 复用 |
| 自主等级 | 追求更自动 | 按风险、可逆性和证据定义边界 |
00 Agent Product:产品承诺是否成立
要检查的问题:
- 这个产品承诺用户能完成什么真实任务,而不是只回答什么问题?
- 最终交付物是什么:答案、草稿、文件、diff、PR、preview、deployment、ticket update,还是业务记录?
- 用户如何判断任务完成了,而不是只看到模型说“完成了”?
- 这个产品更像 personal agent、app builder、developer agent、workflow agent,还是 enterprise agent platform?
产品判断表:
| 如果你的产品说 | PM 应追问 |
|---|---|
| “帮用户提高效率” | 提高哪类任务的效率?节省哪一步? |
| “自动完成工作” | 自动到什么程度?哪里必须停? |
| “连接多个工具” | 连接后产生什么可验收结果? |
| “像员工一样工作” | 谁授权、谁验收、谁负责? |
红旗:产品介绍只说“智能”“自动”“多工具”,但说不清任务对象、交付物和验收方式。
01 Task Surface:任务从哪里进入
要检查的问题:
- 用户是从 prompt、project、issue、thread、ticket、CRM record 还是 workflow 把任务交给 Agent?
- 这个入口是否天然携带任务上下文、权限边界和交付目标?
- 用户提交任务后,系统是否生成了明确的 task object,而不仅是一条聊天消息?
- 不同入口是否对应不同的验收方式?
真实案例:GitHub Copilot coding agent 从 issue 或开发流程进入,比“空白聊天框”更容易知道任务背景、代码上下文和交付物。Slack 中的 Agent 从 thread 或 channel 进入,则天然拥有团队上下文和协作对象。
红旗:所有任务都从一个万能输入框进入,产品无法区分“问一句话”和“委托一件事”。
02 Control Plane:用户如何控制 Agent
要检查的问题:
- 用户能否看见 Agent 的计划,而不是只看到最终回答?
- 高风险动作前是否有 preview、diff、approval 或 takeover?
- 用户是否能暂停、修改、接管或回滚任务?
- 控制点是否根据风险出现,而不是每一步都打断用户?
产品原则:控制层不是为了降低自动化,而是为了让用户敢于委托。低风险步骤可以自动推进,高风险步骤必须让用户重新取得控制权。
红旗:产品只有“开始”和“停止”,没有计划、预览、差异、审批、接管和回滚。
03 Human-in-the-Loop:人何时回到流程
要检查的问题:
- 哪些节点必须由人确认、纠错、审批或接管?
- requester、reviewer、approver、admin 的角色是否区分清楚?
- 人类反馈之后,Agent 是否能继续任务,而不是重新开始?
- 人类节点是否进入日志、指标和责任归属?
产品判断表:
| 人类节点 | 适合场景 | 设计重点 |
|---|---|---|
| Clarify 澄清 | 目标不清、输入缺失 | 让用户补关键变量 |
| Review 审查 | 结果可判断但需确认 | 展示证据和差异 |
| Approve 审批 | 高风险或组织规则要求 | 记录审批人与依据 |
| Takeover 接管 | Agent 卡住或风险升高 | 保留上下文和当前状态 |
红旗:把人工介入当成失败兜底,而不是流程中的正常节点。
04 Permission Model:授权不是弹窗
要检查的问题:
- Agent 能读取哪些数据、执行哪些动作、写入哪些系统?
- 哪些权限是一次性、任务级、会过期、可撤回的?
- 高风险动作是否绑定审批、证据和审计记录?
- 权限不足时,产品是否能解释原因并给出恢复路径?
设计原则:授权应该跟任务、动作和风险绑定,而不是一个粗暴的“允许 Agent 操作”。
红旗:用一个“是否允许 Agent 操作”的总开关覆盖所有数据访问、工具调用和外部副作用。
05 Workspace:任务需要一个工作空间
要检查的问题:
- Agent 的意图、文件、工具结果、日志、预览、凭证边界和交付物放在哪里?
- 用户离开后回来,是否能理解当前状态并继续?
- Workspace 是否能支持协作、接管、恢复和验收?
- 它最终交付的是 preview、PR、report、ticket update、deployment 还是业务记录?
真实案例:Replit Agent 的项目、预览、部署和 checkpoint 共同构成工作空间;开发者 Agent 的 repo、branch、diff、terminal 和 PR 共同构成工作空间。
红旗:任务状态只存在聊天记录里,用户无法回到一个稳定的任务对象继续工作。
06 Long-Running Tasks:把任务变成可管理对象
要检查的问题:
- 长任务是否有 queued、running、waiting、blocked、failed、done 等明确状态?
- 用户是否知道任务卡在哪里、需要谁输入、下一步是什么?
- 是否支持取消、重试、恢复、checkpoint 和部分成果保留?
- 通知是否围绕决策点和交付点,而不是过程噪音?
产品原则:长任务不是“让用户等更久”,而是把等待过程变成可查看、可中断、可恢复、可通知的任务对象。
红旗:长任务只表现为一个无限 spinner,失败后只能重新开始。
07 Trust UX:让用户敢于委托
要检查的问题:
- 用户是否能在行动前看到计划,在行动后看到证据?
- 产品是否解释了风险,而不是只弹出“是否确认”?
- 用户是否能 preview、diff、takeover、rollback?
- 用户是否知道模型建议、系统执行、人类批准分别承担什么责任?
产品判断表:
| 信任问题 | 好设计 |
|---|---|
| 用户怕 Agent 乱做 | 展示下一步动作和权限边界 |
| 用户怕看不懂结果 | 提供 preview、diff、引用、测试结果 |
| 用户怕错了没法撤 | 提供 checkpoint、rollback、undo |
| 用户怕责任不清 | 展示谁授权、谁审批、谁执行 |
红旗:界面看起来很自动,但用户无法判断 Agent 为什么这样做、下一步要做什么、错了怎么撤回。
08 Product Metrics:衡量任务结果
要检查的问题:
- 指标是否围绕任务结果,而不只是 DAU、消息数、token 或调用次数?
- 是否区分 task started、task completed、accepted outcome 和 workflow handoff?
- 是否记录澄清率、阻塞率、恢复率、人工介入质量和重复委托率?
- 指标是否能解释用户为什么继续或停止委托?
建议指标:
| 指标 | 意义 |
|---|---|
| Task completion rate | Agent 是否完成任务 |
| Outcome acceptance rate | 用户是否接受结果 |
| Handoff rate | 何时需要人接管 |
| Recovery success rate | 失败后能否恢复 |
| Repeat delegation rate | 用户是否愿意继续委托 |
红旗:团队只看调用量和留存,却不知道任务是否被用户接受、是否进入真实工作流。
09 Evaluation:评估真实产品表现
要检查的问题:
- eval 是否来自真实任务,而不只是离线问答题?
- 是否评估工具调用、权限决策、人类节点、失败恢复和最终交付物?
- 失败样本是否进入回归集?
- eval 是否成为发布门槛和产品改进机制?
产品原则:Agent eval 应该评估“任务是否被正确完成”,而不只是“答案是否看起来合理”。
红旗:产品宣称通过 benchmark,但真实任务里的工具错误、权限错误和恢复失败没有被评估。
10 Observability:看见 Agent 如何工作
要检查的问题:
- 系统是否能串起 message、tool call、state change、approval、artifact 和 error?
- 用户、工程师、管理员、产品团队是否有不同粒度的视图?
- 出错时是否能定位是意图理解、上下文、权限、工具还是外部系统问题?
- trace 是否连接到 eval、指标和审计?
产品原则:不同角色需要不同可观测性。用户要看计划和证据;工程要看 trace;管理员要看权限和审计;PM 要看失败分布和转化漏斗。
红旗:出了问题只能看最终回答或后台日志,无法复盘 Agent 的真实执行过程。
11 Reliability:让失败可恢复
要检查的问题:
- 产品是否限制了高风险动作的 blast radius?
- 是否有 checkpoint、retry、rollback、idempotency、fallback 和 human takeover?
- 失败时是否给出可执行恢复路径,而不是只显示错误?
- 是否用 acceptance checks 判断任务真的完成?
产品判断表:
| 失败场景 | 好的产品反应 |
|---|---|
| 权限不足 | 说明缺什么权限,提供授权或降级路径 |
| 工具失败 | 显示失败工具,安全重试或切换方案 |
| 结果不合格 | 回到 checkpoint,继续修复或交给人 |
| 风险升高 | 降低自主度,请求确认或审批 |
红旗:Agent 做错后没有回滚、没有部分成果、没有恢复路径,只能让用户重新委托。
12 Platform:从单个 Agent 到系统能力
要检查的问题:
- 组织如何创建、测试、部署、监控、治理和下线 Agent?
- builder、runtime、connector、identity、policy、monitoring、evaluation 是否是共享能力?
- 谁能创建 Agent、连接哪些系统、发布到哪里、由谁审批?
- 平台是否有版本、环境、回滚、审计和生命周期管理?
产品原则:平台化不是 Agent 数量变多,而是共享能力变强。每新增一个 Agent,边际治理成本不应该线性增加。
红旗:团队能做出很多 Agent demo,但每个 Agent 都单独配置权限、工具、日志、发布和治理。
13 Autonomy Levels:定义可托付边界
要检查的问题:
- 自主等级是否按任务风险、可逆性、权限范围和恢复能力定义,而不是按模型聪明程度定义?
- 每一级是否明确任务范围、人类节点、证据要求和责任归属?
- 同一个 Agent 在不同任务上是否可以有不同自主等级?
- 更高自主是否真的带来价值,还是只是增加风险?
产品原则:成熟的 Agent 产品不是所有任务都全自动,而是低风险少打扰,高风险有控制,失败时能恢复,结果可验收。
红旗:产品把“更自主”当成升级方向,却没有定义任务范围、权限边界、人类节点和失败恢复。
总体判断表
| 如果你的产品现在是这样 | 更可能处于什么阶段 | 下一步优先补什么 |
|---|---|---|
| 只有聊天入口和回答 | Demo / Assistant | Task Surface、交付物、验收方式 |
| 能调用工具但没有状态容器 | Tool-using Agent | Workspace、权限边界、trace |
| 能跑长任务但用户看不见过程 | Background automation | Control Plane、Observability、通知 |
| 能自动完成低风险任务 | Early Agent Product | Metrics、Evaluation、Recovery |
| 能进入团队流程和企业系统 | Managed Agent Product | Platform、Policy、Audit、Lifecycle |
| 想提高自主等级 | Risk-sensitive Product | Autonomy Contract、Reliability、Human-in-the-Loop |
评审会议怎么用
建议把这张总表用于一次 60–90 分钟的 Agent 产品评审。
| 时间 | 内容 | 产出 |
|---|---|---|
| 10 分钟 | 说明目标用户、任务和交付物 | 产品承诺一句话 |
| 20 分钟 | 评审任务入口、控制层、权限、工作空间 | 关键设计缺口 |
| 20 分钟 | 评审可靠性、可观测性、评估和指标 | 上线前风险清单 |
| 20 分钟 | 评审平台化和自主等级 | 是否允许扩大范围 |
| 10 分钟 | 打分和排序 | Top 3 改进项 |
最重要的是不要只给总分。要找出“卡住委托”的短板。例如:产品可能模型表现很好,但没有 workspace;也可能 demo 很顺,但没有 recovery;也可能业务价值很高,但权限和审计不足。

一句话总表
一个成熟的 Agent 产品,不是能回答更多问题,而是能让用户把更真实、更高价值的任务交给它,并在整个过程中保持可理解、可控制、可恢复、可验收。
真正的产品化不是把用户从流程里拿掉,而是让用户在合适的位置出现:低风险任务少打扰,高风险任务有控制,失败时能恢复,结果能被验收。