核心结论
Agent 产品里的 Autonomy Levels,不应该回答“这个 Agent 是 L 几”。
它应该回答一个更具体的问题:在某一类任务里,产品允许 Agent 代表用户做哪些决定、执行哪些动作、承担多大的外部后果,并在什么条件下停下来。
一个有用的自主等级设计,至少要定义五件事:
- 授权范围:Agent 可以自己判断什么,不能判断什么。
- 动作边界:Agent 可以读、写、调用、发送、提交、部署到什么程度。
- 停顿点:哪些动作前必须展示计划、预览、diff、引用或审批页。
- 失败处理:失败后是重试、回滚、交给人,还是停止任务。
- 升级条件:什么信号出现时必须降低自主度或转人工。
这比“L1 到 L5”的标签重要得多。用户不关心 Agent 的等级,用户关心的是:它会不会替我乱做事;做错了能不能看见、撤回、追责;我什么时候需要介入。
读者收益
读完这一章,你应该能做三件事:
- 把“更自主”翻译成具体产品边界,而不是营销话术。
- 判断哪些任务可以提高自主度,哪些任务必须保守。
- 设计一套 PM、工程、法务、安全、业务 owner 都能讨论的授权框架。
自主等级的产品定义
在传统软件里,“自动化”通常意味着把一段确定流程交给系统执行。输入确定,流程确定,输出大体可预测。
Agent 的自主性更复杂。它不仅执行动作,还会在执行过程中理解上下文、选择工具、调整计划、处理异常,甚至决定是否继续推进任务。
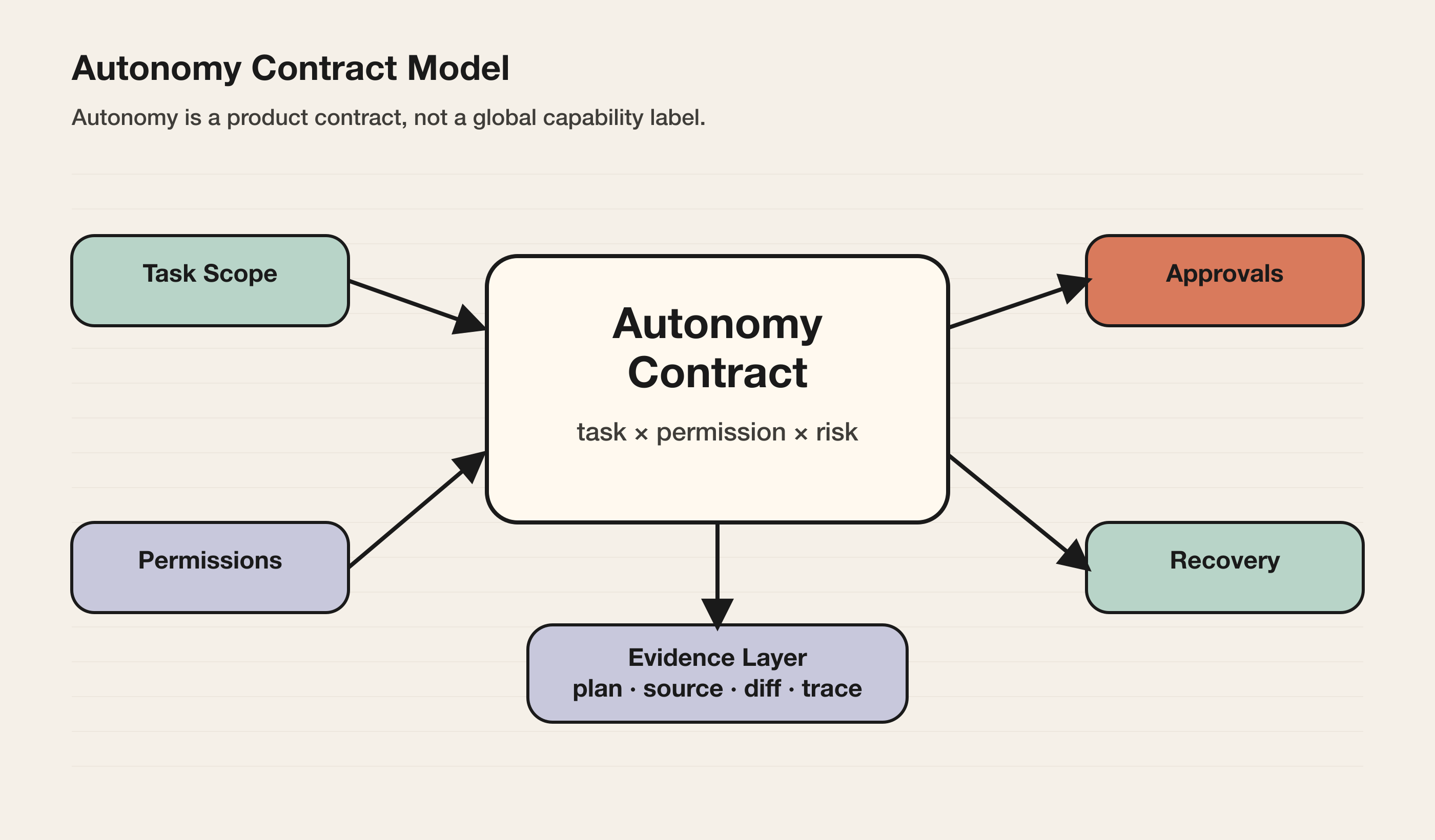
因此,Agent 的自主等级不是一个能力标签,而是一个产品约束:
| 组成 | PM 要回答的问题 |
|---|---|
| 任务范围 | 这个等级适用于哪些任务,不适用于哪些任务? |
| 权限范围 | Agent 能读什么、写什么、调用什么、影响什么? |
| 人类节点 | 哪些地方必须让用户、reviewer、approver 或 admin 介入? |
| 证据要求 | 继续执行前需要展示哪些计划、来源、diff、preview 或测试结果? |
| 恢复机制 | 出错后如何重试、回滚、接管、停止或升级? |
只要其中任何一项没有定义清楚,“更自主”就不是产品进步,而是风险被隐藏到模型后面。
不要按 Agent 分级,要按任务分级
同一个 Agent,在不同任务里应该有不同自主边界。
以一个开发者 Agent 为例:
| 任务 | 合理自主度 | 产品边界 |
|---|---|---|
| 阅读代码并解释模块 | 高 | 只读,无外部副作用 |
| 定位 bug 并提出修复方案 | 高 | 需要引用文件、测试结果或日志 |
| 修改代码并生成 diff | 中高 | 可以写文件,但必须展示 diff |
| 运行测试并修复失败 | 中高 | 可以执行命令,但需要记录命令和输出 |
| 创建 PR | 中 | 需要用户授权或明确策略 |
| merge 到主分支 | 低 | 需要 review、CI、权限策略 |
| 自动部署生产 | 很低 | 需要审批、回滚、审计和发布策略 |
如果一个产品只说“我们的 coding agent 是 L4”,这句话几乎没有信息量。真正有信息量的是:它在哪些任务上可以自动推进,在哪些动作前必须停下,哪些失败会触发人类接管。
消费级个人 Agent 也是一样。整理购物清单、总结网页、规划旅行路线,可以有较高自主度;登录账户、提交订单、付款、发送正式邮件、修改日历邀请,就必须降低自主度。关键差异不在于模型是否能做,而在于动作是否代表用户产生外部后果。
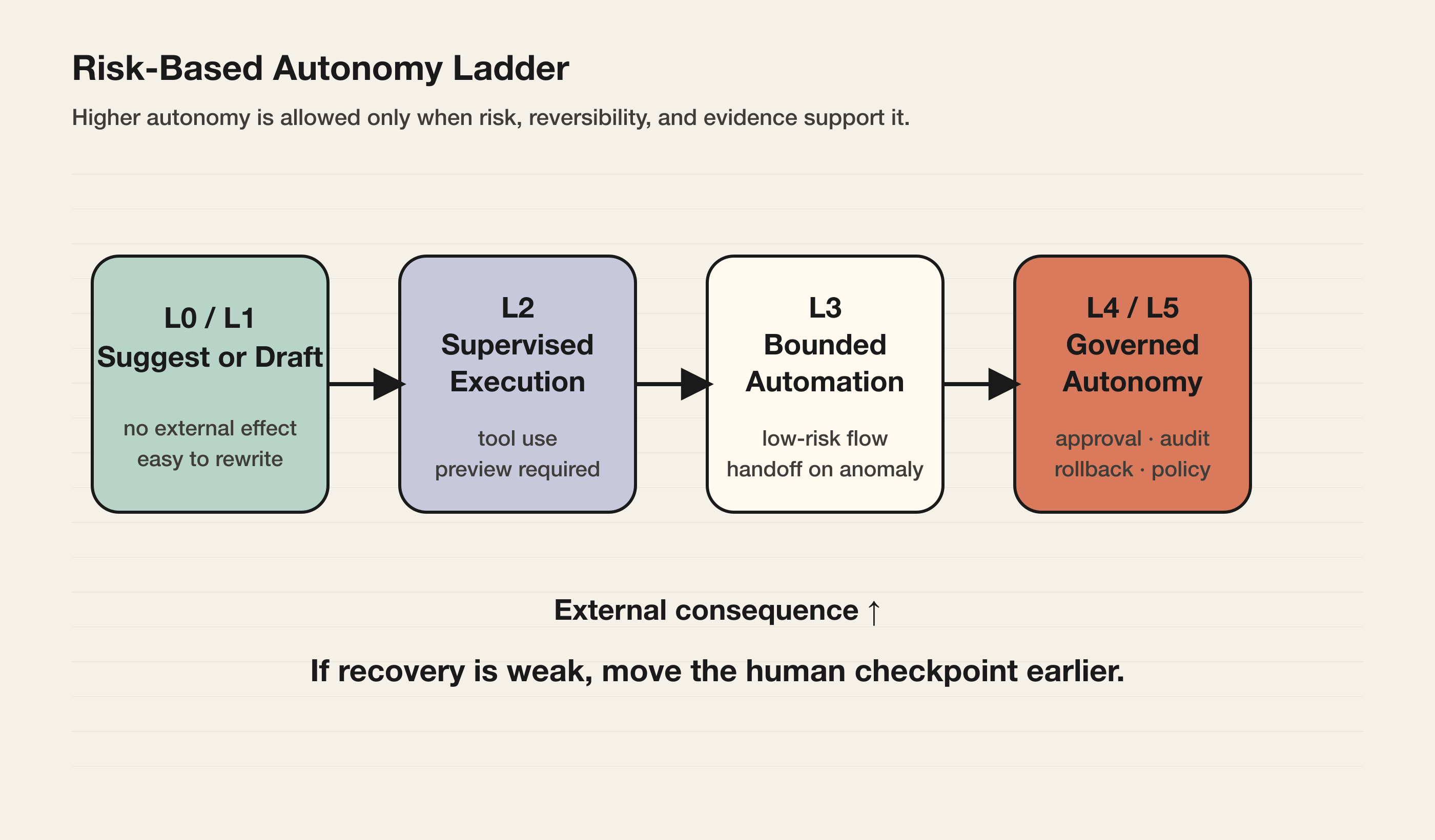
一个可用的五级模型
下面这张表不是行业标准,而是帮助产品团队讨论边界的工作表。
| 等级 | 产品含义 | Agent 可以做什么 | 必须保留的人类节点 |
|---|---|---|---|
| L0 建议 | 只给判断,不执行 | 分析、解释、推荐、排序 | 用户自己执行所有动作 |
| L1 草稿 | 产出候选物 | 写草稿、生成计划、生成代码建议 | 用户选择、修改、复制、提交 |
| L2 受监督执行 | 可以操作工具,但关键动作前停下 | 读写文件、跑测试、拉取信息、生成预览 | 写入外部系统、发送、发布、付款前确认 |
| L3 有边界自动化 | 在明确范围内自动完成低风险流程 | 批量整理、自动分类、低风险修复、内部流转 | 异常、高风险、低置信度时升级 |
| L4 目标驱动流程 | 能跨系统推进完整任务 | 分解任务、调工具、追踪状态、处理常见异常 | 审批、审计、回滚、策略控制常驻 |
| L5 高风险自治 | 长时间独立规划和执行 | 在受控环境中自主达成目标 | 只适合强治理、强隔离、强责任制度的场景 |
这张表最容易被误用的地方,是把 L5 当成目标。
在大多数产品里,成熟状态不是“尽快做到 L5”,而是让不同任务停在合适等级:低风险任务少打扰,高风险任务可控制,长任务可观察,失败路径可恢复。
一个稳定的 L2 产品,往往比一个虚假的 L4 产品更有价值。
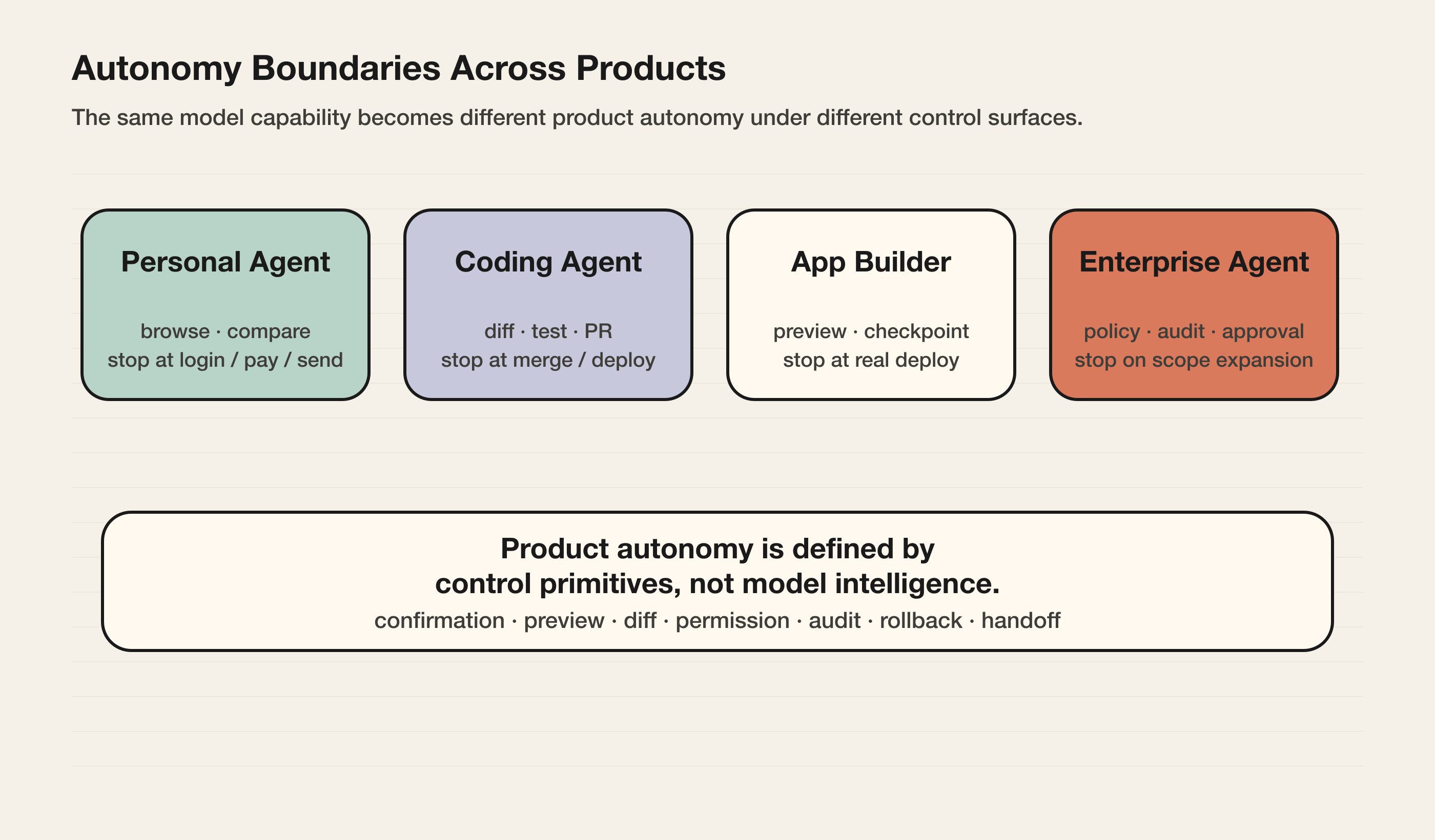
真实产品里的边界
ChatGPT Agent:敏感动作必须停下
个人 Agent 的难点不是“能不能打开网页”,而是“什么时候不能代表用户继续”。
浏览、搜索、整理、比较,本身风险较低。登录账户、提交表单、发送消息、付款、预约、下单,则会把 Agent 的行为变成用户行为。
所以这类产品需要把停顿点设计成一等对象:
- 操作前展示即将执行的动作。
- 对登录、支付、发送、提交等动作强制确认。
- 允许用户接管浏览器或修改输入。
- 对失败、卡住、权限不足给出明确状态。
这里的产品问题不是“模型是否足够聪明”,而是用户是否能在关键动作前重新取得控制权。
Claude Code / Codex / Cursor:自主性建立在工程护栏上
开发者 Agent 看起来更容易提高自主度,因为软件工程天然有一些可观察、可恢复的控制面:
- diff 让修改可审查;
- test 让结果部分可验证;
- git 让错误可回滚;
- branch / PR 让协作流程可接入;
- sandbox / permission 让命令和文件访问可约束;
- CI 让提交前检查可自动化。
这解释了为什么 coding agent 的核心产品形态不是“更会聊天”,而是围绕 diff、test、terminal、PR、review、权限和上下文组织展开。
但这些护栏也定义了边界:自动生成 patch 可以,自动 merge 通常不行;自动跑测试可以,自动改生产数据库通常不行;自动开 PR 可以,自动发布要看组织策略。
v0 / Lovable / Replit:App Builder 的边界在 preview 和 deploy
App Builder 的价值是把用户意图变成可运行的应用,而不是只给出代码解释。
它可以自动生成页面、改 UI、创建项目结构、接入简单状态、启动预览环境。这里的关键控制点是 preview:用户必须能看到系统做出了什么。
真正需要降级自主度的地方,是 deploy 之后的外部后果:
- 是否绑定真实域名;
- 是否连接真实数据库;
- 是否处理用户数据;
- 是否接入支付、登录、邮件或第三方 API;
- 是否让外部用户访问。
因此,App Builder 的自主等级不应该只看“生成了多少代码”,而要看 preview、checkpoint、rollback、environment、deploy decision 是否完整。
Copilot Studio / Agentforce:企业自主性由治理定义
企业 Agent 的自主边界通常不是模型能力决定的,而是身份、数据、权限和审计决定的。
一个销售 Agent 是否能更新 CRM,不取决于它能不能理解客户状态,而取决于:
- 当前用户是否有权限;
- 数据来源是否可信;
- 更新字段是否属于低风险字段;
- 是否需要 manager approval;
- 是否写入 audit log;
- 错误更新后如何恢复;
- 客户影响是否可控。
企业 Agent 平台的核心能力因此不是单个聊天框,而是 identity、connector、policy、approval、audit、monitoring、lifecycle。没有这些机制,所谓高自主只是把组织风险交给一个不可治理的界面。
设计自主等级时,先做风险分层
产品团队可以先把任务按三个轴拆开。
外部后果
任务是否会影响系统外部的人、钱、数据或生产环境?
| 外部后果 | 例子 | 自主策略 |
|---|---|---|
| 无外部后果 | 总结、解释、草稿、推荐 | 可以较高自主 |
| 轻微外部后果 | 创建内部草稿、更新个人待办、整理标签 | 可自动,但需可撤销 |
| 明显外部后果 | 发送邮件、修改客户记录、提交 PR、部署预览 | 需要证据和确认 |
| 高风险外部后果 | 付款、删除数据、签合同、生产发布、法律承诺 | 默认人工审批 |
外部后果越强,自主等级越应该保守。
可逆性
做错以后,恢复成本有多高?
| 可逆性 | 例子 | 产品要求 |
|---|---|---|
| 易恢复 | 重写文本、撤销本地修改 | 可自动重试 |
| 可恢复但有成本 | revert commit、关闭 PR、恢复历史版本 | 需要 checkpoint |
| 难恢复 | 邮件已发送、客户收到错误信息 | 需要确认和审计 |
| 几乎不可恢复 | 付款完成、合同签署、数据永久删除 | 不应自动执行 |
可逆性越低,越需要审批、证据和人工节点。
证据质量
Agent 是否能给出足够证据,让用户判断它是否该继续?
- 计划:它准备怎么做。
- 来源:它依据哪些输入、文档、网页、记录。
- 过程:它调用了哪些工具,得到什么结果。
- 结果:它生成了什么 diff、preview、草稿或变更摘要。
- 失败:它在哪里失败,为什么失败,下一步建议是什么。
没有证据的自主性,本质上是黑箱自动化。
Autonomy Contract:把等级写成产品对象
一个产品化的自主等级,不应该只是 UI 上的一个开关。更好的做法是把它写成任务合同。这个合同不需要以代码形式存在,但至少应该在产品文档、策略配置或后台中明确以下内容:
| 合同字段 | 应回答的问题 |
|---|---|
| 任务类型 | 适用于代码修改、客户邮件、CRM 更新、应用部署,还是其他任务? |
| 适用范围 | 允许访问哪些系统、处理哪些对象、排除哪些动作? |
| 权限范围 | 能读什么、写什么、执行什么、产生什么外部影响? |
| 审批要求 | 哪些动作需要谁确认,确认前要展示哪些证据? |
| 运行策略 | 最长运行多久,失败几次后停止,低置信度如何处理? |
| 可观测性 | 是否展示计划、工具过程、中间状态、审计记录? |
| 恢复方式 | 是否支持重试、回滚、接管、停止、升级? |
这个合同迫使团队回答产品问题,而不是停留在形容词:
- Agent 可以在哪些系统里行动?
- 哪些动作永远不允许自动执行?
- 什么证据足以让用户确认?
- 什么失败会触发 handoff?
- 用户、reviewer、admin 分别负责什么?
如果这些字段写不出来,说明产品还没有真正定义自主等级。
从 L2 升到 L3,需要满足什么条件
很多产品最危险的跃迁,不是从 L0 到 L1,而是从“受监督执行”到“有边界自动化”。
因为 L2 仍然依赖用户在关键点确认;L3 则意味着 Agent 可以在一段范围内连续推进任务。
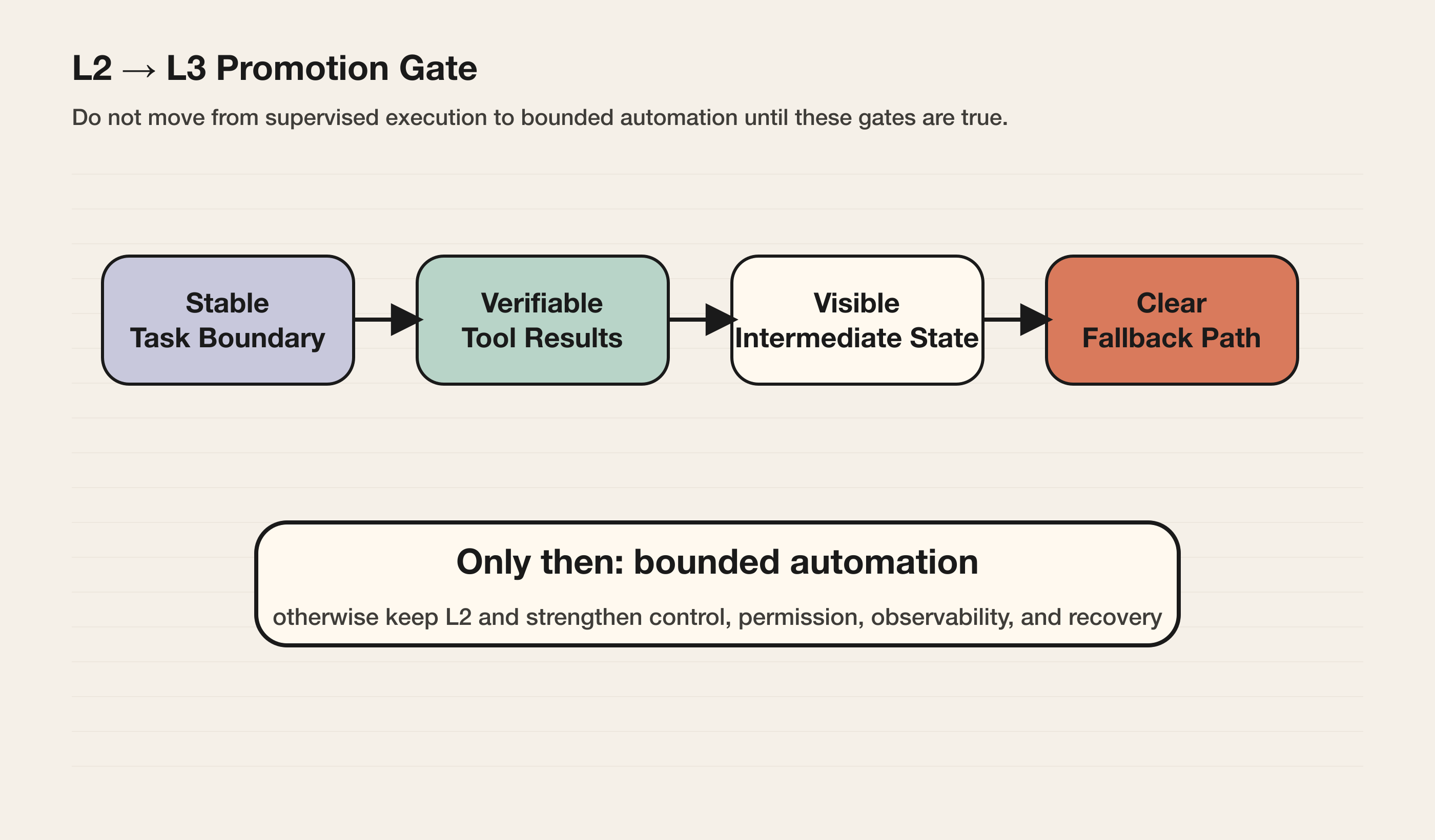
从 L2 升到 L3,至少要满足以下条件:
- 任务边界稳定:输入、输出、成功标准可以被明确描述。
- 低风险步骤可识别:系统知道哪些动作可以自动做,哪些不行。
- 工具结果可验证:Agent 调用工具后,能判断结果是否符合预期。
- 中间状态可见:用户能看到任务进展,而不是只看到 spinner。
- 失败路径清楚:超时、权限不足、低置信度、工具失败都有处理方式。
- 回滚能力存在:至少能撤销内部写入、关闭草稿、恢复版本或停止流程。
- 指标可监控:成功率、人工接管率、错误率、用户撤销率必须可追踪。
如果这些条件不存在,产品不应该提高自主等级。更合理的做法是继续强化控制层、权限层、可观测性和恢复路径。
产品界面应该暴露什么
自主等级不能只藏在后端策略里。用户需要在界面上理解当前任务处于什么边界内。
一个可用的界面通常要暴露五类信息:
- 当前目标:Agent 正在完成什么任务。
- 当前权限:它能读什么、写什么、调用什么。
- 下一步动作:它准备做什么,是否会产生外部后果。
- 需要确认的点:哪些动作会停下来等人。
- 退出路径:用户如何暂停、接管、回滚或终止。
这也是为什么 Agent 产品需要 Control Plane,而不是只有 chat thread。自主度越高,控制面越重要。
常见错误
把等级当营销语言
“全自动 Agent”“L5 Agent”“自主完成一切任务”通常没有产品意义。它们没有说明任务范围、权限范围、失败处理和责任边界。
用一个总开关控制所有任务
“允许自动执行”这种总开关过于粗糙。总结文档和发送合同不应该共享同一个自主设置。
自主等级应该按任务类型、权限范围和风险等级组合定义。
只加确认弹窗
确认弹窗不是完整的人类节点。
一个有效确认必须包含:用户确认的具体动作、动作依据、预期结果、风险提示、可撤销性、拒绝后的路径。否则它只是把责任转嫁给用户。
没有降级机制
真正成熟的 Agent 产品,不只知道什么时候自动推进,也知道什么时候停止。
典型降级信号包括:工具结果冲突、输入不完整、权限不足、低置信度、测试失败、外部系统异常、用户长时间未响应、动作影响范围扩大。
检查清单
设计 Autonomy Levels 时,可以直接检查这些问题:
- 是否按任务类型定义自主等级,而不是按 Agent 名字定义?
- 每类任务的 allowed decisions 和 allowed actions 是否明确?
- 哪些动作会产生外部后果?这些动作是否默认停下?
- 用户确认前能看到哪些证据:plan、source、diff、preview、test、audit log?
- 失败后是 retry、rollback、handoff、ask user,还是 stop?
- 是否有暂停、接管、撤销、终止任务的入口?
- 是否记录成功率、接管率、撤销率、失败原因和高风险动作拦截率?
- 从低等级升到高等级时,是否有可验证的产品条件,而不是只因为模型升级?
小结
Autonomy Levels 的价值,不是给 Agent 贴一个更高级的标签,而是把用户委托给 Agent 的权力写清楚。
成熟的 Agent 产品不会追求所有任务都全自动。它会把低风险、可恢复、证据充分的任务自动化;把高风险、不可逆、外部后果强的任务放进确认、审批、审计和回滚机制里。
换句话说,自主等级不是产品宣传语,而是 Agent 产品的授权系统。