Pi Agent 101|04|Tool Runtime
模型只提出行动,Pi 的 Tool Runtime 负责校验、执行、观测和结果回填。
模型不能真的碰你的电脑。
它可以说:“我想读这个文件。”它可以说:“我想运行这个测试命令。”它也可以说:“我想把这几行代码替换掉。”但真正读文件、跑 shell、改代码的,是本地 Tool Runtime。
这层边界非常关键。没有它,tool calling 只是模型输出的一段 JSON。有了它,agent 才变成一个受控的本地执行系统。
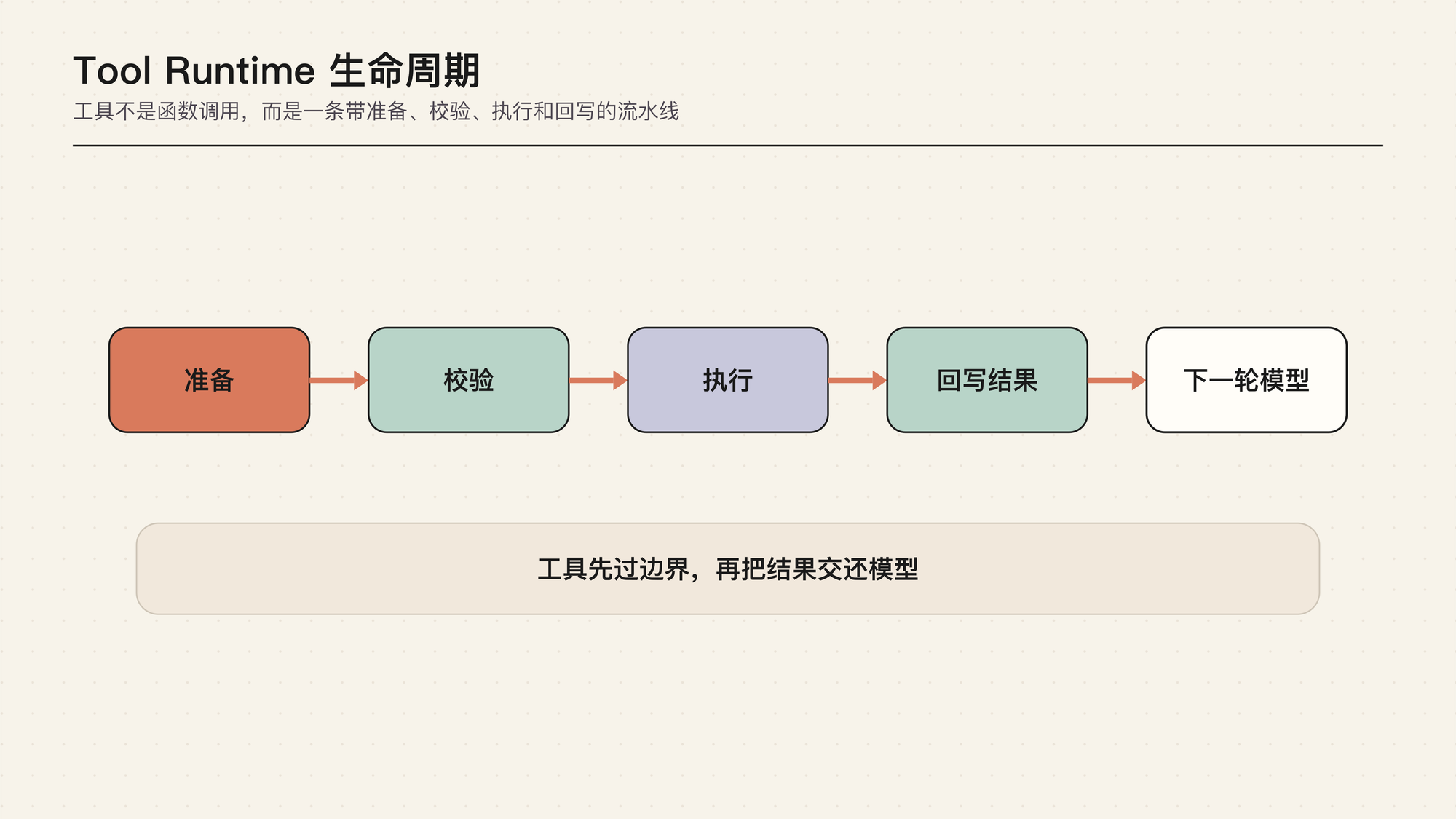
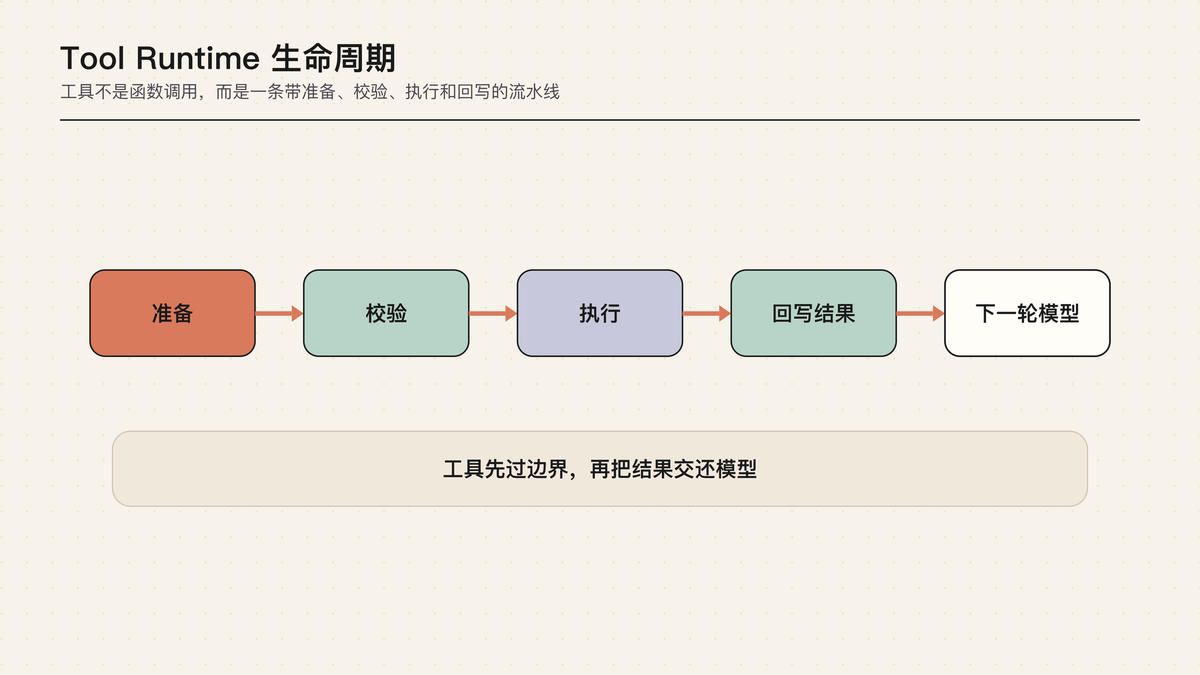
这张生命周期图的重点是:tool call 不是函数调用的同义词。模型只提出“想做什么”,runtime 才负责把这个意图变成真实动作。中间至少要经过参数校验、工具查找、权限判断、执行模式选择、实际执行、结果包装、事件展示和上下文回填。
如果少了这些层,工具很容易变成黑盒:执行了什么不知道,失败为什么不知道,对文件系统造成了什么影响也不知道。
本文结构
工具让 Agent 能影响真实世界:读文件、写文件、运行命令、查询信息。也正因为工具有真实副作用,运行时不能把模型的工具请求直接放行。它需要检查工具是否存在、参数是否合理、是否被策略允许、能否取消,以及失败后如何告诉模型。
这一篇按工具调用的生命周期展开:先看默认工具为什么少,再看一次 tool call 如何经过校验、执行、事件展示和结果回填,最后讨论并发、失败和权限边界。
阅读目标
- 为什么 Pi 默认只给 read、bash、edit、write 四个工具
- 一次 tool call 怎么变成 tool result message
- 工具定义、执行后端、hook、并发策略为什么要分开
主流 Agent 产品里的工具层
Claude Code、Codex CLI、Cursor 和 OpenClaw 都不是让模型直接“拥有能力”。模型提出行动,runtime 决定能不能执行、怎么执行、怎么记录。
Claude Code 里,模型可以请求读文件、改文件、跑 Bash,但本地 runtime 要决定怎么执行、怎么展示、怎么记录。Cursor 里,模型看起来在 IDE 里改代码,本质上也是工具边界在工作。OpenClaw 更明显:发送消息、调用外部服务、处理媒体,都可以包装成工具,但不能让模型绕过 runtime 直接执行。
为什么默认工具很少

这张图说明:工具越少越容易控制;默认工具覆盖 coding agent 的基础动作。
Pi 默认给模型的不是一大堆工具,而是四个:read、bash、edit、write。
这四个工具已经覆盖 coding agent 的基础动作:读文件、运行命令、精确修改文件,必要时完整写入文件。grep、find、ls 也可以存在,但不一定要默认全部打开。
这种克制有几个实际原因。
第一,模型会分心。工具列表越长,模型越容易在“该用哪个工具”上犯错。
第二,prompt 会膨胀。每个工具都要解释参数、行为和边界,工具越多,系统提示越重。
第三,安全边界会变模糊。读文件、写文件、跑命令、发消息、联网请求,这些动作风险不同。工具越多,runtime 越需要清楚地知道哪些动作能自动执行,哪些需要审批,哪些必须被拦住。
Coding agent 的默认行动面应该小而清楚。
一次工具调用的路径

这张图说明:模型只提出工具请求,runtime 才负责校验、执行和回填。
一次工具调用通常会经过这些步骤。
- assistant message 里出现 tool call
- runtime 查找工具定义
- 准备参数,并用 schema 校验
- beforeToolCall hook 有机会阻断或修改
- tool.execute 真正执行,并通过 onUpdate 发出进度
- afterToolCall hook 有机会改写结果
- runtime 生成 toolResult message,写回上下文
这里有两条线要分开看。
事件线服务 UI 和可观测性。工具开始了、输出了几行、结束了,这些都可以实时展示。
消息线服务下一轮模型。工具结果必须变成模型能读懂的 tool result,否则模型不知道刚才那一步发生了什么。
修测试时工具怎么参与
用户说“修复这个失败测试”。模型第一步可能不是改代码,而是调用 read 看测试文件,调用 bash 跑一次失败用例,再根据报错调用 edit 修改实现。
这里每一步都要经过 Tool Runtime。bash 不能无限跑,edit 不能把同一个文件并发改乱,工具输出也不能只显示在终端里就结束;它必须被包装成 tool result 回到模型上下文。否则模型下一轮就不知道刚才测试到底失败在哪里。
并发取决于副作用

这张图说明:能不能并发取决于副作用,不是取决于模型一次叫了几个工具。
Pi 支持并发执行工具,但不是无脑并发。
如果某个工具声明需要顺序执行,整个 batch 会顺序执行。文件写入类操作还会通过按文件排队的方式避免同一文件被并发修改。比如两个编辑动作同时碰到同一个文件,第二个不会抢在第一个修改尚未落盘时动手,而是排队等待前一个修改完成后再基于最新文件内容执行。
这说明 Tool Runtime 要知道工具的副作用。读文件可以比较自由,写文件就要小心;两个工具可以先后在 UI 上展示,但写回模型上下文时仍然要保持合适顺序。
工具失败怎么处理

这张图说明:工具失败不一定终止任务,而是变成模型下一轮能理解的事实。
Tool Runtime 不能只服务 happy path。模型返回不存在的工具名、参数 JSON 格式不对、schema 校验失败、bash 超时、edit 找不到精确匹配,这些都会发生。Pi 这类 runtime 不会假装错误不存在,而是把错误包装成 tool result 或 runtime event:UI 能展示失败,session 能记录失败,模型下一轮也能看到“刚才那一步为什么没成功”。
对“修复失败测试”来说,这很重要。一次 bash 超时不应该让整个 session 消失;一次 edit 失败也不应该静默跳过。好的工具边界会把失败变成可恢复的信息,让 loop 决定是换一种命令、重新读文件,还是向用户说明需要介入。
设计边界
自己做 harness 时,工具不要只是一个裸函数。它至少要有 schema、执行模式、上下文、权限/确认策略、错误包装和结果回填规则。越早把这些边界想清楚,后面越不容易把 policy 写散。
工具层保护什么

这张图说明:工具层保护的不是抽象接口,而是真实文件、命令和用户信任。
工具层保护的是用户的工作环境。读文件、改文件、跑命令、发网络请求,都发生在模型之外。模型可以建议,但不能直接碰文件系统。Runtime 必须知道哪些工具只读,哪些工具有副作用,哪些工具可以并行,哪些工具必须顺序执行。
这也是为什么工具结果要结构化。一次失败的测试,不能只回填“命令失败”。模型下一轮需要知道命令是什么、退出码是什么、关键 stderr 是什么、是否超时、是否被用户取消。UI 也需要展示这些信息,方便用户判断 agent 是走在正确路径上,还是已经偏了。
失败要能恢复
工具失败不是异常情况,而是 agent 工作的一部分。文件不存在、测试失败、命令超时、编辑冲突、权限不足,都应该变成下一轮可用的信息。
如果工具层只抛异常,agent 会中断;如果工具层吞掉错误,模型会误以为动作成功。更好的设计是把失败包装成明确的 tool result,让 loop 决定下一步:换路径、重读上下文、请求用户确认,或者诚实地停止。
设计取舍
默认工具。Pi 默认只开放 read、bash、edit、write。默认行动面越小,模型越不容易在工具选择上走偏,权限边界也更清楚。
搜索工具。grep、find、ls 这类能力可以作为增强工具存在,但不一定要默认进入模型上下文。工具列表太长,会污染 prompt,也会增加选择错误。
并发。Pi 可以并行执行工具,但写回上下文时要保持稳定顺序。UI 可以按完成顺序显示,模型上下文不能乱。
文件修改。同一个文件的写入必须串行化。per-file mutation queue 的意义,就是避免两个 edit 同时修改同一份内容。
Hook。before/after tool call 让策略留在 runtime 边界上,而不是散落到每个工具实现里。
OpenClaw 的对应问题
这一篇对应工具适配和本地执行边界。OpenClaw 可以把回复、消息发送、文件处理或外部服务动作包装成工具,但模型只是提出调用。真正要不要执行、怎么执行、结果怎么写回 transcript,仍然是 runtime 的责任。
实现里的工具边界
Pi 的工具不是裸函数。一个工具在真正执行前,要先经历工具查找、参数准备、schema 校验、扩展 hook、执行模式判断和取消信号检查。执行中可以不断发 update,执行后还要经过结果包装和 after hook,最后变成 tool result message 回到模型上下文。
工具还有来源和启用状态。内置工具、SDK 自定义工具、扩展注册工具都会进入工具定义集合,但模型当前能用哪些工具,还要经过 active tools 过滤。工具变化后,Pi 会重建系统提示词,让模型看到的工具说明和 runtime 真实可用能力保持一致。
并发也不是随便开。某些工具可以并行,某些有副作用的工具必须顺序执行。即使并行执行,Pi 也会尽量保持回填给模型的 tool result 顺序稳定。这样 UI 可以实时显示完成顺序,模型看到的结果却不会乱。
工具失败不等于任务中断
真实任务里,工具失败非常常见:文件不存在、参数不合法、命令超时、权限不足、扩展阻止执行、编辑冲突。Pi 的工具层倾向于把这些失败包装成 tool result,让模型下一轮看到失败事实,而不是让整个 agent 直接崩掉。
这对“修复失败测试”很关键。测试失败不是异常,而是下一步分析的依据;命令超时也不是系统崩溃,而是需要换策略;edit 失败意味着模型可能需要重新读文件再修改。
所以 Tool Runtime 的价值是:模型提出行动,本地 runtime 负责安全执行、记录过程、把失败也变成可继续推理的事实。
如何判断
第一,这个工具有没有副作用。读文件和写文件不应该共享同一套执行策略;发消息、删文件、调用外部服务更需要明确权限边界。
第二,这个工具结果能不能被模型继续使用。结果如果只是原始 stdout,模型可能抓不到重点;结果如果过度摘要,关键错误又会丢失。
第三,这个工具失败后系统能不能恢复。失败应该进入上下文和 UI,而不是只成为异常日志。
一句话总结
模型提出行动,本地 runtime 负责校验、执行和回填结果。
小结
模型说“我想跑测试”,不等于它真的能碰你的机器。中间必须有一层 runtime:先检查,再执行,再把结果写回去。少了这一层,tool calling 很快就会从“帮我干活”变成“模型随便动手”。