很多 Agent demo 讲工具调用时,会把重点放在 function calling:模型输出一个工具名和参数,程序执行函数,再把结果发回模型。
这个解释能帮助人理解第一步,但它很容易误导人。真实系统里的工具不是一组随便暴露给模型的函数。工具会读文件、写文件、启动进程、访问网络、打开浏览器、发送消息,甚至修改外部系统。只要工具有副作用,问题就不再是“怎么调用函数”,而是“谁允许它调用、它能调用什么、失败后怎么返回、结果怎样进入上下文”。
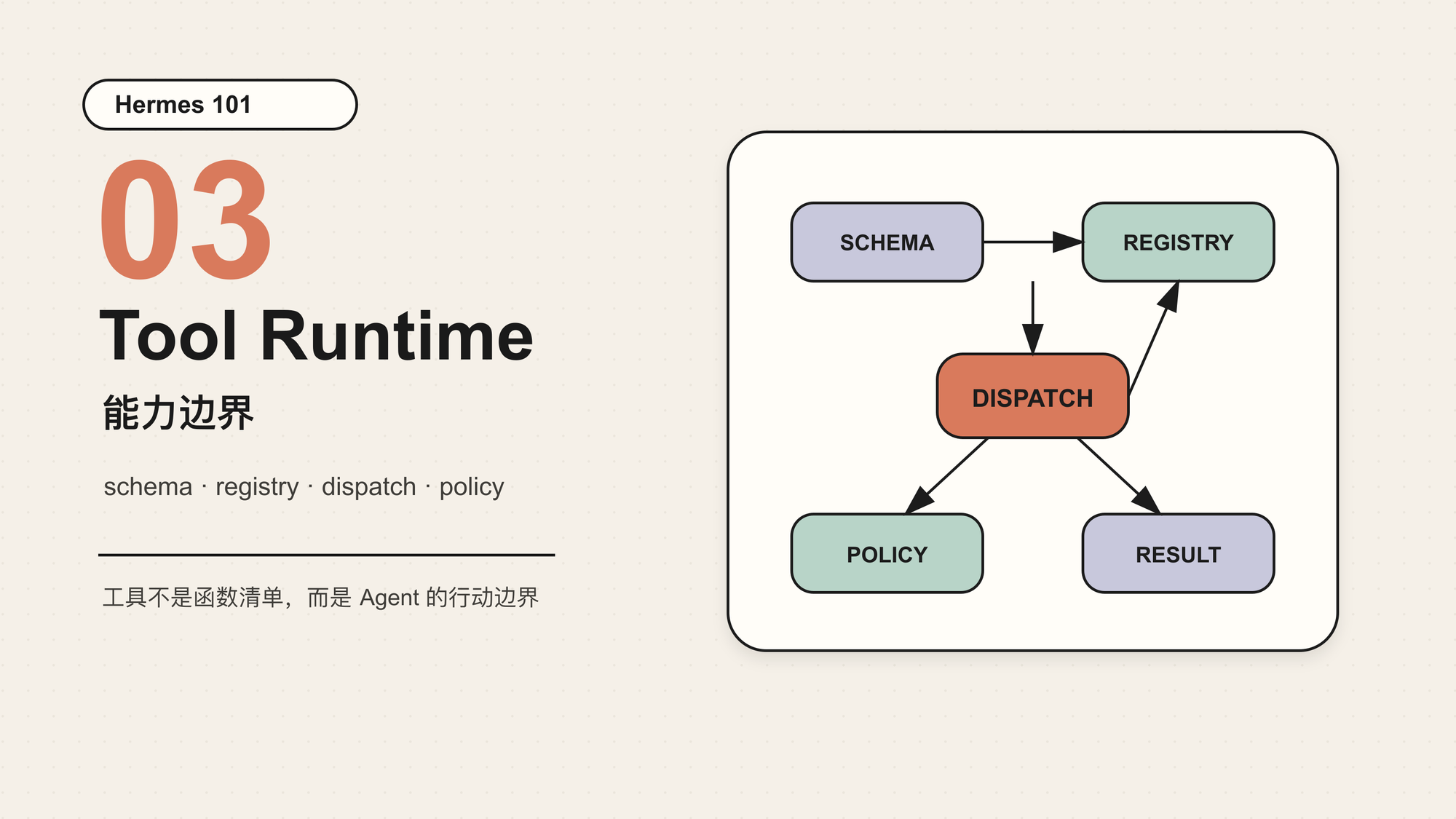
这就是 Tool Runtime 要解决的问题。
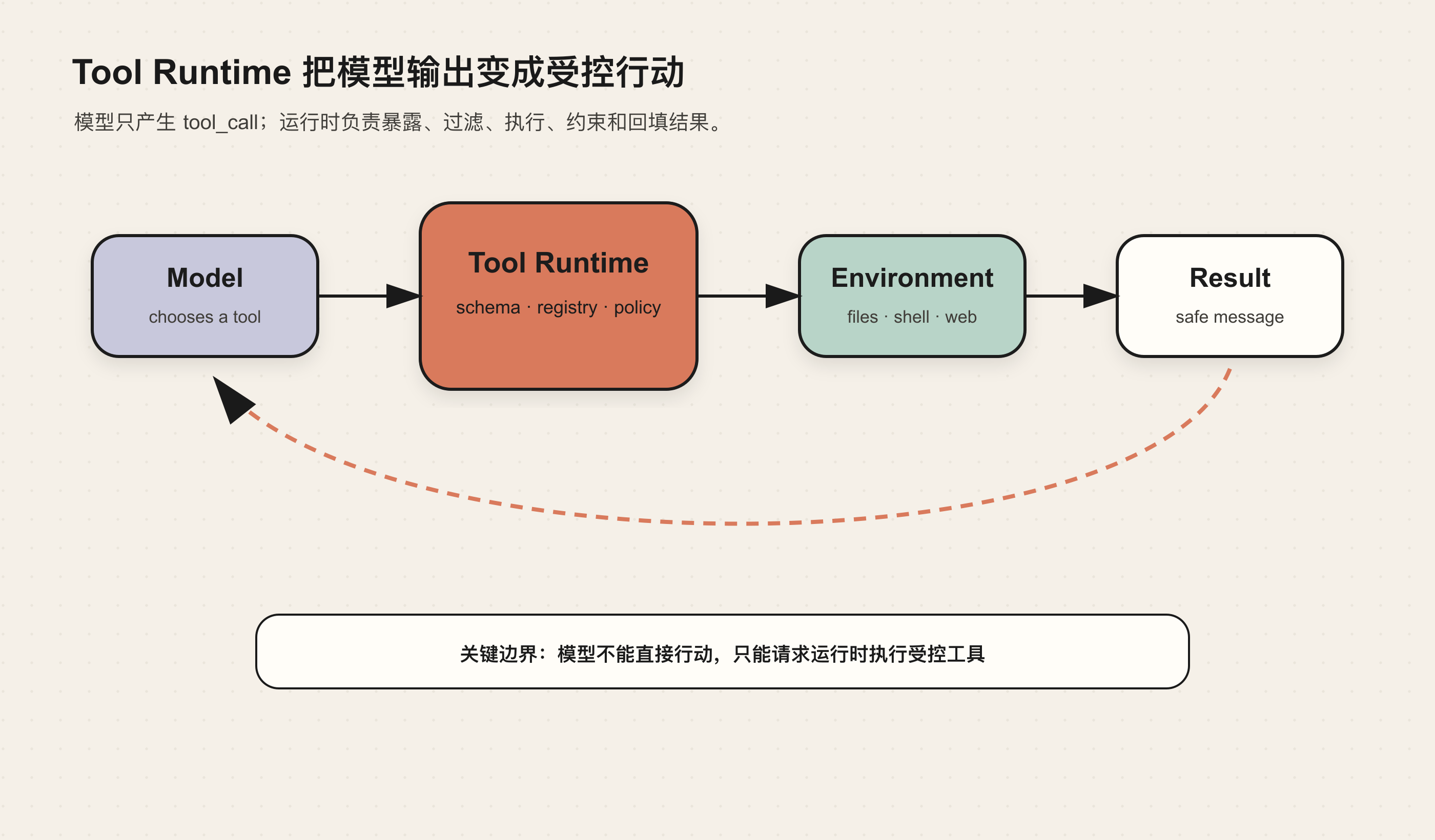
在 Hermes 里,工具系统不是 Agent Loop 的附属功能,而是 Agent 的能力边界。模型只能提出 tool_call;真正的执行、过滤、审批、并发、错误封装和结果回填,都发生在运行时里。
读完本文,你应该能回答
- 为什么“注册了工具”不等于“模型能看到工具”?
- Tool Runtime 需要处理哪些执行、权限、结果和错误边界?
- 如何按入口、任务和子 Agent 收窄工具集合?
- mini-agent-harness 怎样实现一个最小但安全的工具层?
本篇在系列中的位置
前一篇解释了 Agent Loop 如何推进任务,本篇聚焦 loop 中最危险也最有价值的一段:执行工具。下一篇会看这些工具结果和对话历史如何被 Session Tree 保存、恢复和分叉。
贯穿案例
贯穿这个系列,可以一直带着同一个任务来读:用户说“帮我修复这个 repo 里的 failing tests”。不同章节会回答同一个任务在运行时的不同问题:入口怎样进入、上下文怎样准备、模型怎样决定下一步、工具怎样执行、状态怎样保存、失败后怎样恢复。
工具不是函数清单
如果只看最小实现,工具系统可以非常简单:
type Tool = {
name: string
description: string
parameters: JSONSchema
handler: (args: unknown) => Promise<string>
}
模型看到 schema,选择一个工具,运行时调用 handler。这个结构适合 demo,但真实 Agent 很快会遇到几个问题。
第一,工具不一定可用。浏览器工具可能缺少 Playwright,图片生成可能缺少 API key,Home Assistant 可能没有 token,某个 MCP server 可能还没连上。
第二,不同入口不应该看到同一组工具。CLI 可以开放本地 terminal 和 file;cron job 不应该递归创建 cron job;子 Agent 只应该拿到完成任务所需的最小工具集;某些消息平台不应该暴露高风险能力。
第三,工具描述本身会影响模型行为。schema 里如果提到一个当前不可用的工具,模型可能会继续调用它。工具结果如果太长,会污染上下文;如果太短,又会丢失决策依据。
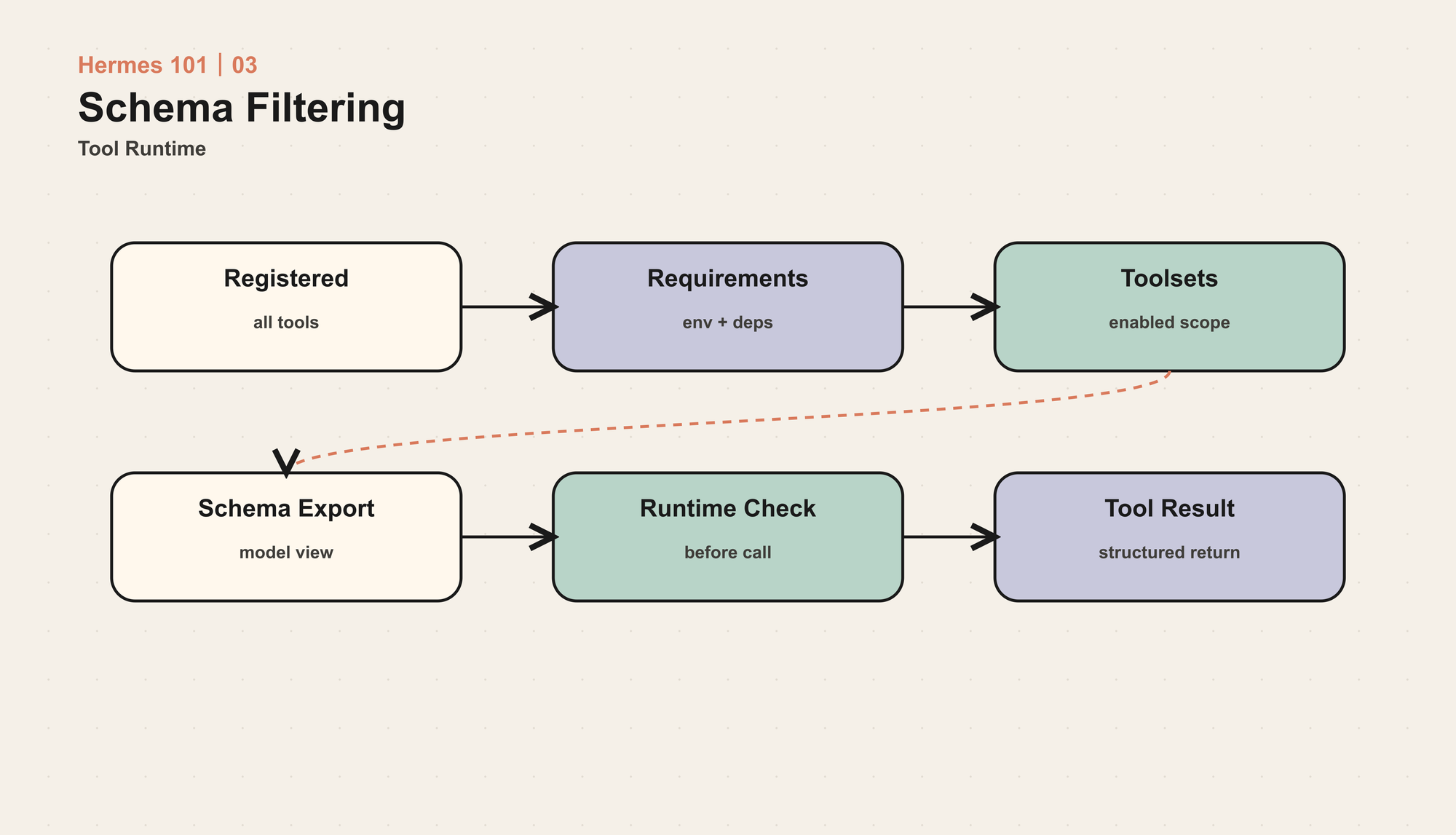
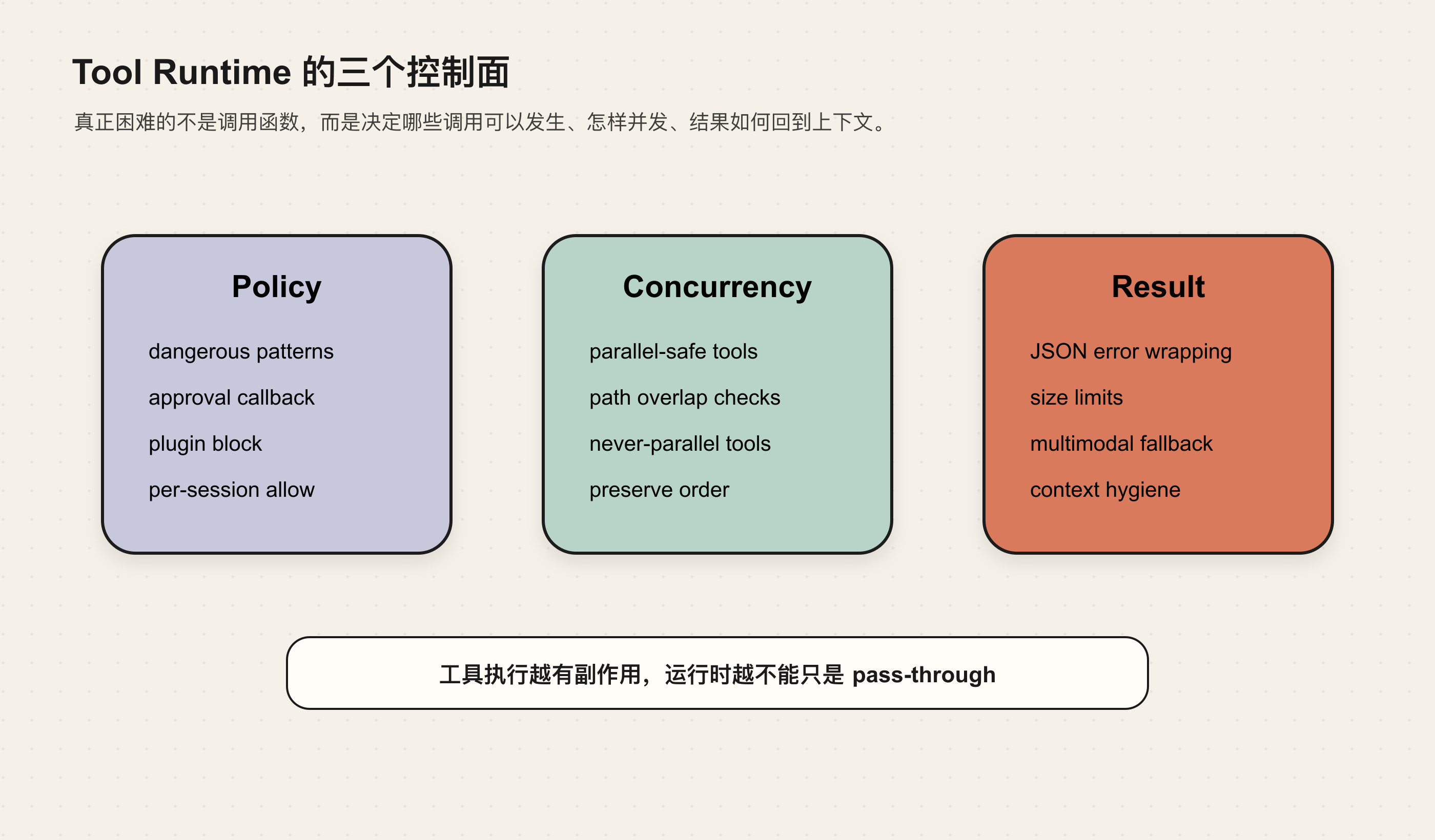
所以 Tool Runtime 的第一层职责不是执行,而是 决定本轮模型能看到哪些工具。
Tool Lifecycle 表
用 failing tests 任务看,一个工具从“存在”到“结果进入模型”至少经历这些阶段。
| 阶段 | Runtime 做什么 | 读者要注意什么 |
|---|---|---|
| Register | 工具声明 schema、handler、toolset、可用性检查 | 注册只是进入候选池 |
| Filter | 按平台、任务、子 Agent、配置过滤工具 | 模型不应该看到不可用能力 |
| Expose | 把工具转成 provider 接受的 function schema | 描述会影响模型选择 |
| Approve | 对高风险命令或外部副作用做审批 | 工具调用不是普通函数调用 |
| Execute | 在受控环境里运行 handler | cwd、env、超时、并发都重要 |
| Normalize | 裁剪、封装错误、补充 metadata | 结果必须适合进入上下文 |
| Append | 作为 tool result 回填 messages | 必须保持 tool_call_id 配对 |
所以 Tool Runtime 的真正边界是:模型只能提出行动意图,运行时决定这个意图能不能执行、怎样执行、执行结果怎样回到协议里。
Hermes 怎样暴露工具
Hermes 的工具暴露有一个清晰路径:
- 每个工具文件在 import 时调用
registry.register()。 tools/registry.py保存工具的 schema、handler、toolset、可用性检查和元信息。model_tools.py负责发现工具模块,按 toolset 过滤,再生成模型 API 需要的 OpenAI-format function schema。- Agent Loop 在调用模型时,把过滤后的 schema 传给 provider。
这个设计的重点是:注册的工具,不等于模型能看到的工具。
一个工具注册时,至少包含这些信息:
type ToolEntry = {
name: string
toolset: string
schema: FunctionSchema
handler: ToolHandler
checkFn?: () => boolean
requiresEnv?: string[]
isAsync?: boolean
maxResultSizeChars?: number
dynamicSchemaOverrides?: () => Partial<FunctionSchema>
}
这里有几个细节值得注意。
checkFn 不是 UI 装饰。它决定工具是否进入模型可见的 schema。检查失败时,工具会被过滤掉,而不是暴露给模型后再在执行时失败。
toolset 不是简单分类。它是能力治理的入口。Hermes 可以通过 enabled_toolsets 和 disabled_toolsets 控制不同运行场景下的工具集合。组合 toolset 会展开成具体工具名,最后再交给 registry 生成 schema。
dynamicSchemaOverrides 解决的是“静态 schema 会过期”的问题。比如 delegation 的限制、execute_code 能调用哪些沙箱工具、Discord bot 当前有哪些权限,都可能取决于运行时配置。Hermes 会在生成 schema 时动态调整这些描述,避免模型看到错误能力。
从 registry 到模型 schema
Hermes 不是把 registry 里的 schema 原样发给模型。它会经过几层过滤。
第一层是 toolset 解析。如果显式传入 enabled_toolsets,只包含这些 toolsets 展开的工具。如果传入 disabled_toolsets,则在全集基础上扣掉对应工具。
第二层是可用性检查。registry.get_definitions() 会执行每个工具的 checkFn。检查失败的工具不会进入模型 schema。这个结果还有短 TTL 缓存,避免长生命周期进程在每轮对话里重复探测外部环境。
第三层是动态 schema 修正。Hermes 会根据真实可用工具重建一些 schema。例如 execute_code 的描述只列出当前实际可在沙箱内调用的工具;当 web_search 不可用时,browser_navigate 的描述不会继续建议模型优先使用 web 工具。
第四层是 schema sanitization。不同 provider 对 JSON Schema 的容忍度不同,尤其是本地 OpenAI-compatible server 或 llama.cpp 这类后端。Hermes 会对 schema 做兼容性清理,降低 provider 因 schema 形状不支持而拒绝请求的概率。
这套流程看起来繁琐,但它解决的是一个很实际的问题:模型只能对自己看到的工具做计划。如果工具表不准确,后面的 Agent Loop 再强也会被带偏。
一次 tool_call 怎样执行
模型返回 tool call 之后,Hermes 不会直接调用函数。执行路径大致是这样的:
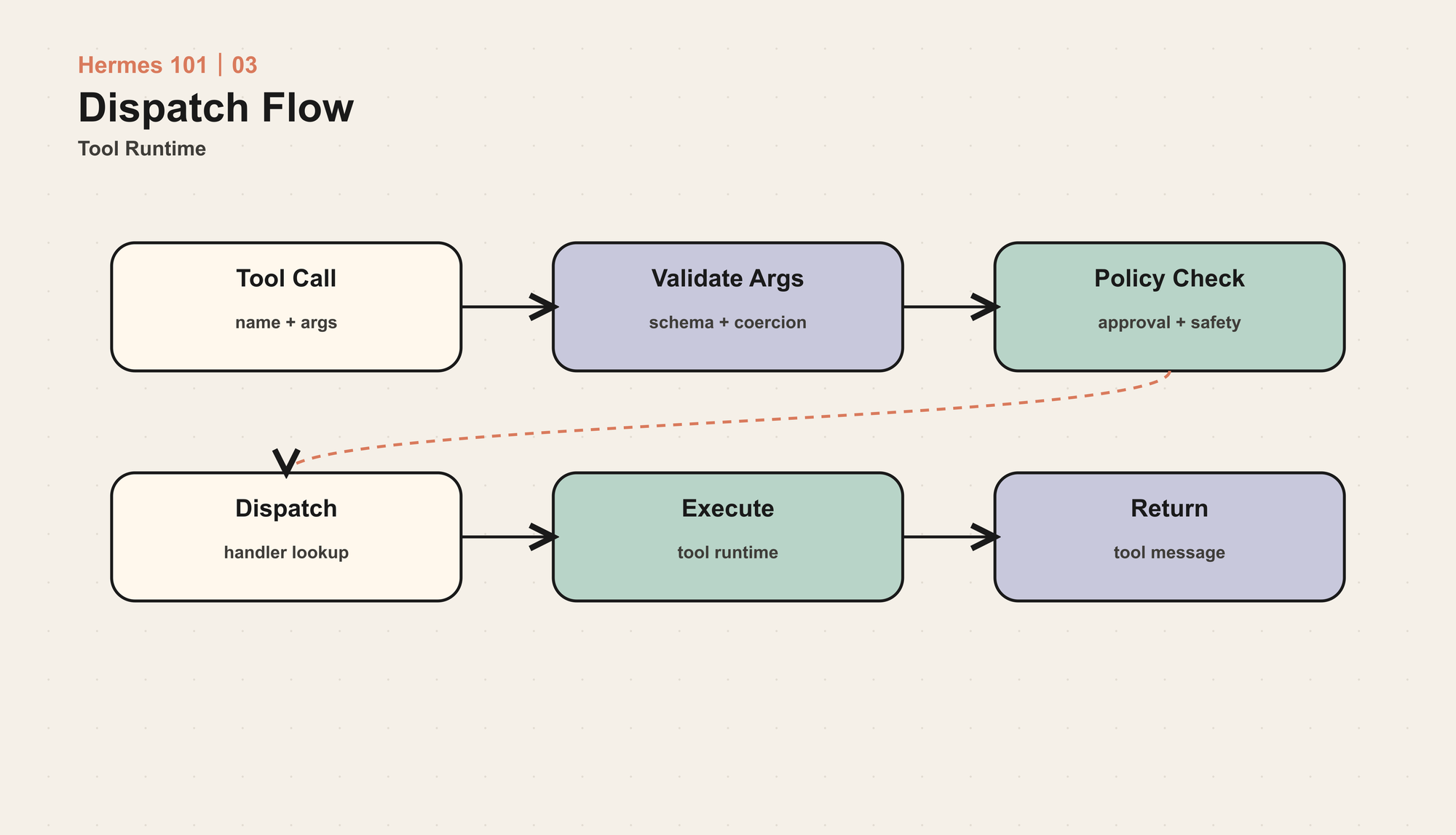
第一步是参数修正。
模型经常会把数字写成字符串,把布尔值写成 "true",或者把数组参数写成单个字符串。Hermes 会用工具注册时的 JSON Schema 对参数做保守修正:能安全转换就转换,不能转换就保留原值,让工具自己处理或返回错误。
第二步是 agent-level tool 截获。
有些工具不能直接走普通 registry,因为它们会碰到 Agent 自己的运行时状态。典型例子是 todo、memory、session_search、delegate_task。这些工具的 schema 会注册给模型看,但真正执行时由 Agent Loop 接管。
原因很简单:memory 不是外部 API,它会写长期记忆;delegate_task 不是普通函数,它会创建子 Agent;session_search 需要查询当前会话数据库并避免混入不该混入的上下文。这些能力属于 Agent 控制面,不只是执行环境。
第三步是插件 hook。
Hermes 支持 pre_tool_call 和 post_tool_call 这类生命周期 hook。插件可以观察工具调用,也可以在执行前阻止某些调用。这样工具系统不只是内置能力集合,也能成为扩展点。
第四步才是 registry dispatch。
普通工具会进入 registry.dispatch(),根据工具名找到 ToolEntry,再调用对应 handler。同步工具直接执行,异步工具通过 _run_async() 桥接到当前运行环境可用的 event loop。
最后,工具结果被封装成字符串返回给 Agent Loop,再以 tool message 的形式回到 messages。对模型来说,这不是日志,而是下一轮推理的一部分。
安全边界在工具层出现
工具越接近真实系统,安全问题越具体。
一个只返回天气的工具,风险很低。一个能执行 shell 命令的工具,风险完全不同。它可能删除文件、改写配置、停止服务、访问凭据目录,或者执行远端脚本。
Hermes 的 terminal tool 因此接入了危险命令审批系统。审批系统会检测一组危险模式,比如递归删除、格式化磁盘、覆盖系统配置、破坏数据库、停止服务、curl | sh 这类远端执行、fork bomb、进程 kill 等。
命中后,CLI 可以弹出交互式审批;Gateway 可以把审批请求发到消息平台;某些低风险误命中也可以交给辅助模型做 smart approval。审批状态按 session 保存,也可以写入永久 allowlist。
这里的重点不是“能不能拦住所有危险命令”。更重要的是架构位置:安全边界必须在 Tool Runtime 里,而不是只写在 prompt 里。
Prompt 可以提醒模型不要做危险操作,但只要工具真的开放,模型就可能犯错。运行时必须有自己的检查和审批。
并发不是简单加速
模型一次可能返回多个 tool calls。最简单的执行方式是顺序执行,但这会浪费时间。比如多个 web_search、多个 read_file、多个 session_search 彼此独立,完全可以并发。
Hermes 的 Agent Loop 有并发判断逻辑。它不会因为有多个 tool calls 就直接并发,而是先检查几件事:
- 工具是否属于 never-parallel 列表。
- 参数是否能解析成对象。
- 文件类工具是否作用在重叠路径上。
- 工具是否属于明确的 parallel-safe 集合。
- 回填结果时是否能保持原始 tool_call 顺序。
这不是单纯的性能优化,而是语义保护。
两个工具同时写同一个文件,结果不可预测。一个工具在等用户澄清,另一个工具继续改系统,用户看到的状态会混乱。多个工具按完成时间写回 messages,而不是按原始 tool_call 顺序写回,也可能破坏 provider 的 tool_call / tool_result 对齐关系。
所以更准确地说,Tool Runtime 需要做的是 受控并发:能并发时并发,不确定时保守。
工具结果也是上下文工程
很多人设计工具时,只关注输入 schema,忽略输出。
但对 Agent 来说,工具结果会进入 messages,成为下一轮模型调用的上下文。这个结果太长,会挤占上下文窗口;太杂,会污染模型注意力;太短,又可能让模型无法判断下一步。
Hermes 在工具层和 Agent Loop 层都处理这个问题。
一方面,工具可以声明 max_result_size_chars。不同工具的结果体量不一样,execute_code 这类工具可以返回更大的结构化输出,普通工具则应尽量裁剪。
另一方面,dispatch 会把异常封装成 JSON 错误,而不是让程序崩掉。工具失败后,模型仍然能读到一个结构化失败结果,并决定下一步是重试、换方法,还是向用户解释阻塞点。
还有一类更复杂的情况是 multimodal tool result。比如截图、图片或桌面控制返回的不是普通文本。Hermes 会保留 multipart 内容,同时提供文本摘要或 fallback,让不支持多模态 tool message 的 provider 仍然能继续对话。
这说明工具结果不是 stdout 的搬运。它是 上下文工程的一部分。
MCP 和插件怎样进入同一层
Hermes 的工具系统不是只服务内置工具。
内置工具通过 tools/*.py 自注册。MCP 工具来自外部 MCP server。插件也可以注册自己的工具。它们来源不同,但进入 Agent Loop 前都要落到同一个问题上:怎样变成模型能理解的 schema,怎样被 toolset 控制,怎样被 dispatch,怎样返回结果。
这也是 Tool Runtime 的价值。它给不同来源的能力一个统一入口。
MCP 解决的是外部工具和资源怎样连接到 Agent。插件解决的是系统怎样被扩展。Tool Runtime 则负责把这些能力放进同一套运行时控制面:可见性、可用性、执行、审批、并发、结果回填。
没有这个统一层,工具系统很容易变成一堆特殊分支。每个入口、每个平台、每个插件都单独处理工具调用,Agent Loop 很快会失控。
mini-agent-harness 应该怎样实现工具层
如果要在 mini-agent-harness 里实现这一层,不需要一开始复制 Hermes 的所有复杂度。更好的做法是保留关键边界。
第一版可以这样设计:
type ToolEntry<TArgs = unknown> = {
name: string
toolset: string
description: string
parameters: JSONSchema
handler: (args: TArgs, ctx: ToolContext) => Promise<ToolResult>
check?: () => boolean
sideEffect?: "none" | "read" | "write" | "external"
}
type ToolRuntime = {
register(entry: ToolEntry): void
schemas(enabledToolsets: string[]): FunctionSchema[]
dispatch(call: ToolCall, ctx: ToolContext): Promise<ToolMessage>
}
然后把复杂度按顺序加上去:
- 先支持 tool registry 和 schema generation。
- 再支持 toolset filtering。
- 再支持 check function,把不可用工具从 schema 里拿掉。
- 再支持 dispatch error wrapping。
- 再支持危险工具 approval。
- 最后再支持并发策略、插件 hook、MCP 动态工具和结果压缩。
不要一开始追求工具数量。学习框架最应该暴露的是边界:模型看见什么、能调用什么、运行时允许什么、结果怎样回到上下文。
结论
Tool Runtime 是 Agent 系统里最容易被低估的一层。
从模型视角看,工具只是一个 schema 列表。从系统视角看,工具层决定了 Agent 的真实行动能力:它能读哪里、写哪里、访问什么服务、触发什么副作用、怎样处理失败、怎样避免越权。
Hermes 的实现给出的答案很明确:工具不是 prompt 里的能力描述,而是运行时里的受控接口。
一个可靠的 Tool Runtime 至少要回答这些问题:
- 哪些工具被注册?
- 本轮模型能看到哪些工具?
- 工具是否真的可用?
- schema 是否和当前运行时状态一致?
- tool_call 参数怎样修正?
- 哪些工具必须由 Agent Loop 自己处理?
- 哪些调用需要审批?
- 哪些工具可以并发?
- 工具失败怎样返回给模型?
- 工具结果怎样进入上下文而不污染上下文?
Agent Engineering 的核心变化也在这里:我们不再只是给模型接函数,而是在设计一层把模型意图转成真实行动的运行时边界。
参考资料
- Hermes Agent README: https://github.com/NousResearch/hermes-agent
- Hermes Agent Tools Runtime: https://hermes-agent.nousresearch.com/docs/developer-guide/tools-runtime
- Hermes Agent Toolsets Reference: https://hermes-agent.nousresearch.com/docs/reference/toolsets-reference
- Hermes Agent Built-in Tools Reference: https://hermes-agent.nousresearch.com/docs/reference/tools-reference
- Hermes Agent Agent Loop Internals: https://hermes-agent.nousresearch.com/docs/developer-guide/agent-loop
- Anthropic, Writing Effective Tools for AI Agents: https://www.anthropic.com/engineering/writing-tools-for-agents
- Anthropic, Effective Context Engineering for AI Agents: https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
- Model Context Protocol Specification: https://modelcontextprotocol.io/specification