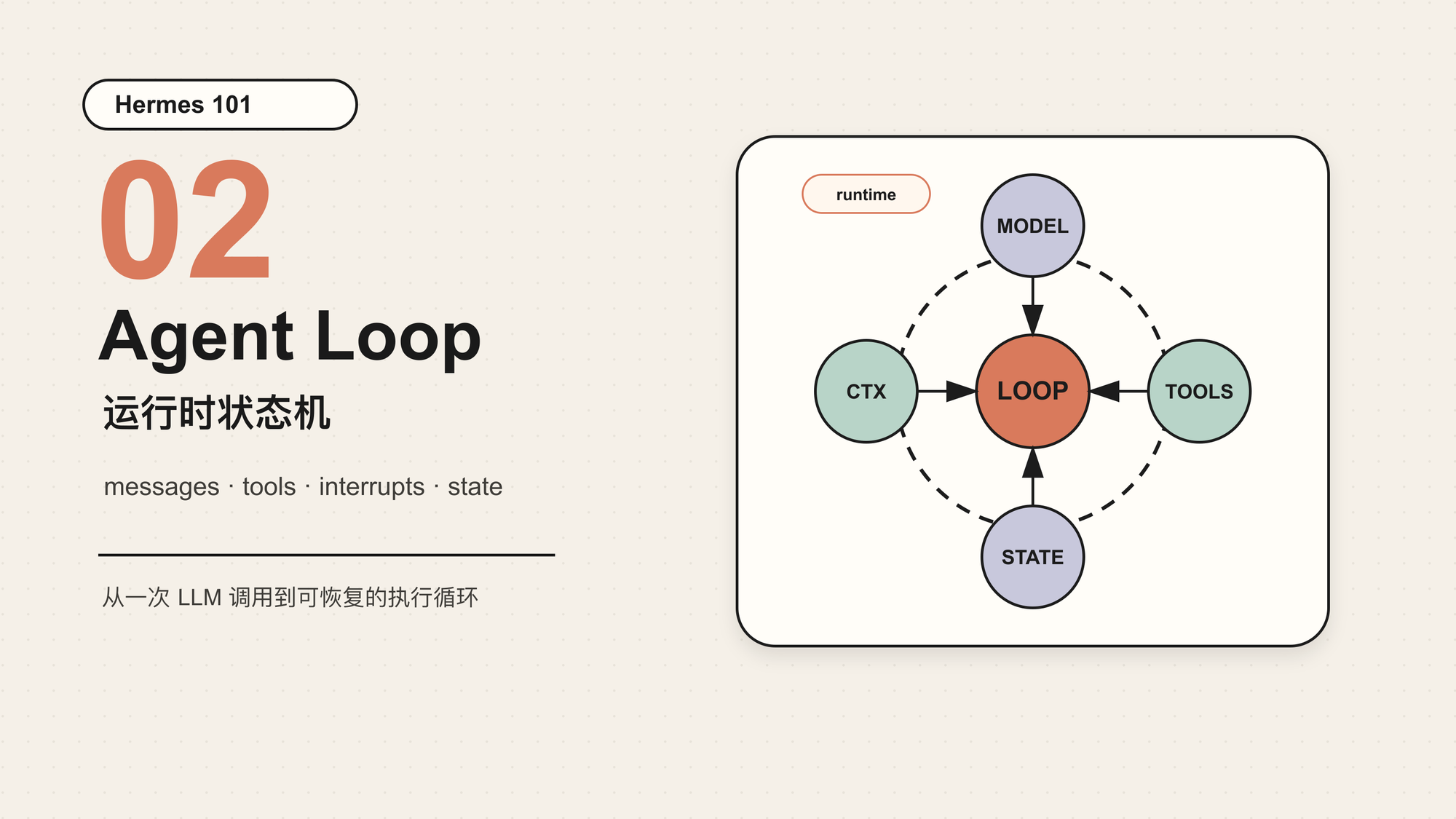
第一篇我们把 Hermes 看成一个 Agent Runtime。第二篇开始拆核心:Agent Loop。
很多人讲 Agent Loop 时,会把它简化成一段很短的伪代码:把用户消息发给模型;如果模型要调用工具,就执行工具;把工具结果发回模型;直到模型输出最终回答。这个模型没有错,但它太干净。真实系统里的 Agent Loop 更像一条运行时管线。它要处理消息格式、工具调用配对、并发工具、用户打断、上下文压缩、模型失败、预算耗尽、状态保存、平台回调,以及不同 provider 之间的协议差异。
Hermes 的 AIAgent 正好提供了一个完整样本。它仍然有一个“模型-工具-模型”的循环,但循环外面包了很多工程边界。少了这些边界,Agent 可以 demo;有了这些边界,Agent 才能长时间工作。
读完本文,你应该能回答
- 为什么 Agent Loop 不能只写成一个 while 循环?
- 一次用户请求在 Hermes 里会经历哪些运行时阶段?
- tool_call 与 tool_result 为什么必须严格配对?
- 什么时候应该压缩、重试、保存或终止循环?
本篇在系列中的位置
上一篇建立了 Agent Runtime 的总图,本篇进入核心执行路径:一次任务如何在模型调用和工具调用之间推进。下一篇会把 loop 里的“工具执行”单独拆出来,看 Tool Runtime 如何把模型意图变成受控行动。
贯穿案例
贯穿这个系列,可以一直带着同一个任务来读:用户说“帮我修复这个 repo 里的 failing tests”。不同章节会回答同一个任务在运行时的不同问题:入口怎样进入、上下文怎样准备、模型怎样决定下一步、工具怎样执行、状态怎样保存、失败后怎样恢复。
最小循环为什么不够
最小 Agent Loop 大概长这样:
while (true) {
const response = await model.call(messages, tools)
messages.push(response)
if (!response.toolCalls.length) {
return response.text
}
for (const call of response.toolCalls) {
const result = await tools.execute(call)
messages.push({ role: "tool", tool_call_id: call.id, content: result })
}
}
这段代码适合解释 function calling 的基本控制流,但它故意忽略了几个麻烦问题。
第一,模型返回的不是“指令”,而是一段协议消息。不同 provider 对消息顺序、工具调用字段、reasoning 字段、streaming delta 的要求不同。你的 loop 必须把它们折叠成一种内部格式,否则每个分支都会长出一套工具执行逻辑。
第二,工具调用不是普通函数调用。工具会读写文件、启动进程、访问网络、修改外部系统。它们需要权限、审批、进度回调、错误封装和结果裁剪。
第三,循环可能永远不结束。模型可能反复调用工具,工具可能返回无效 JSON,provider 可能报 429,用户可能中途发 /stop,上下文可能在第十轮后爆掉。Agent Loop 必须定义这些情况的控制流,而不是把它们留给“异常处理”。
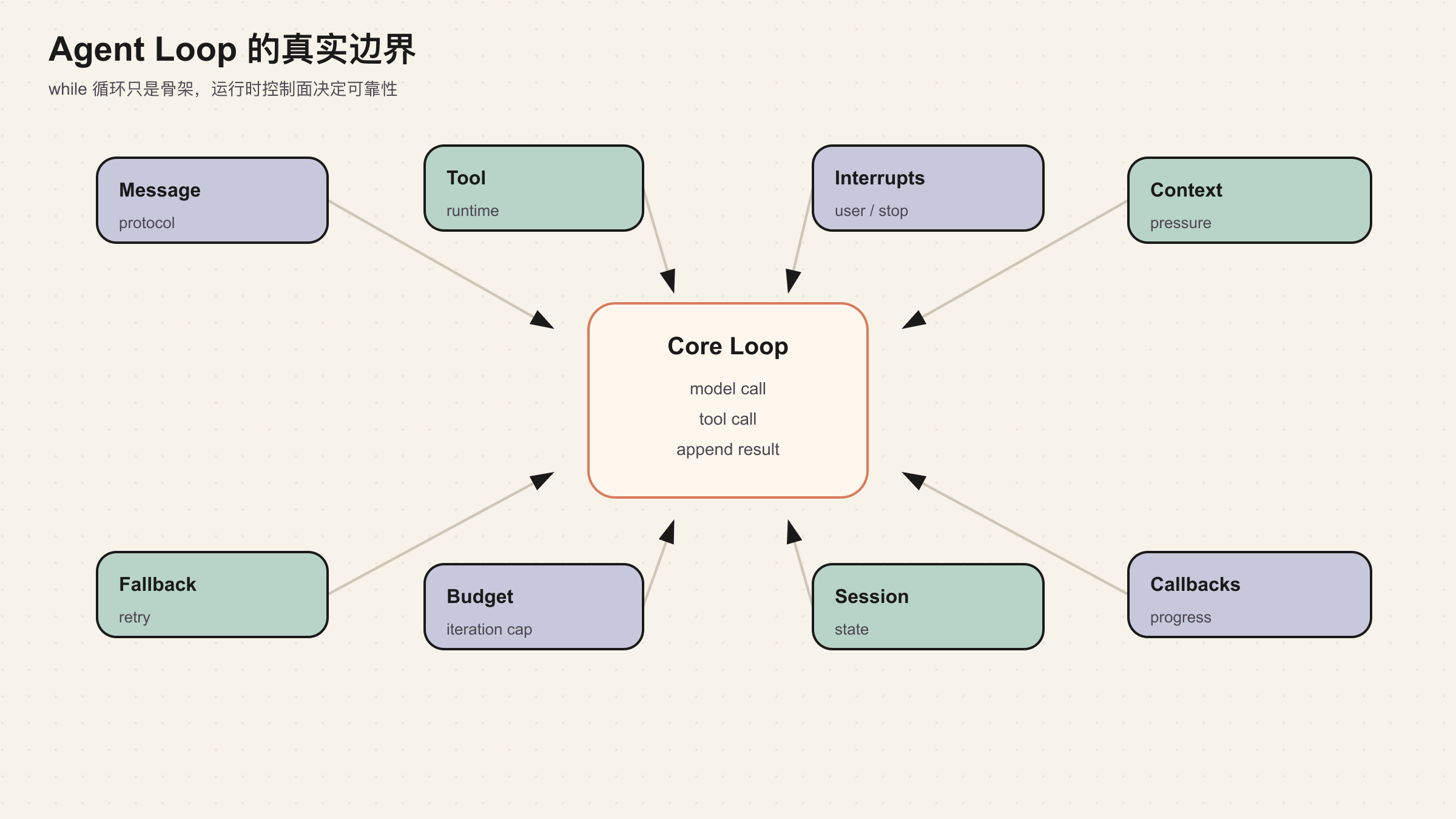
所以更准确的说法是:Agent Loop 是一个状态机。while 循环只是它的骨架。
Agent Loop 状态表
把 Agent Loop 看成状态机之后,很多边界会更清楚。
| 状态 | 进入条件 | 退出条件 | 失败风险 |
|---|---|---|---|
| Prepare Turn | 收到用户消息或恢复 session | system prompt、messages、tools 准备完成 | 上下文缺失、工具暴露错误 |
| Preflight | 即将调用模型 | token、预算、压缩检查通过 | 历史过长、tool 配对破坏 |
| Model Call | provider request 已构造 | assistant message 返回 | 429、超时、协议差异 |
| Tool Dispatch | assistant 返回 tool_calls | 所有 tool result 回填 | 权限拒绝、并发失败、结果过长 |
| Continue | tool result 已进入 messages | 下一轮 model call 或压缩 | 循环失控、重复调用工具 |
| Finalize | assistant 无 tool_calls | 保存 session、返回用户 | 未保存状态、平台投递失败 |
这张表解释了为什么真实 Agent Loop 不能只写成 while(true)。循环本身很短,难的是每个状态的进入条件、退出条件和失败恢复。
Hermes 的一轮执行
Hermes 的核心入口是 AIAgent.run_conversation()。从外部看,它接收用户消息,返回最终回答。从内部看,它做的是一次完整的 turn lifecycle。
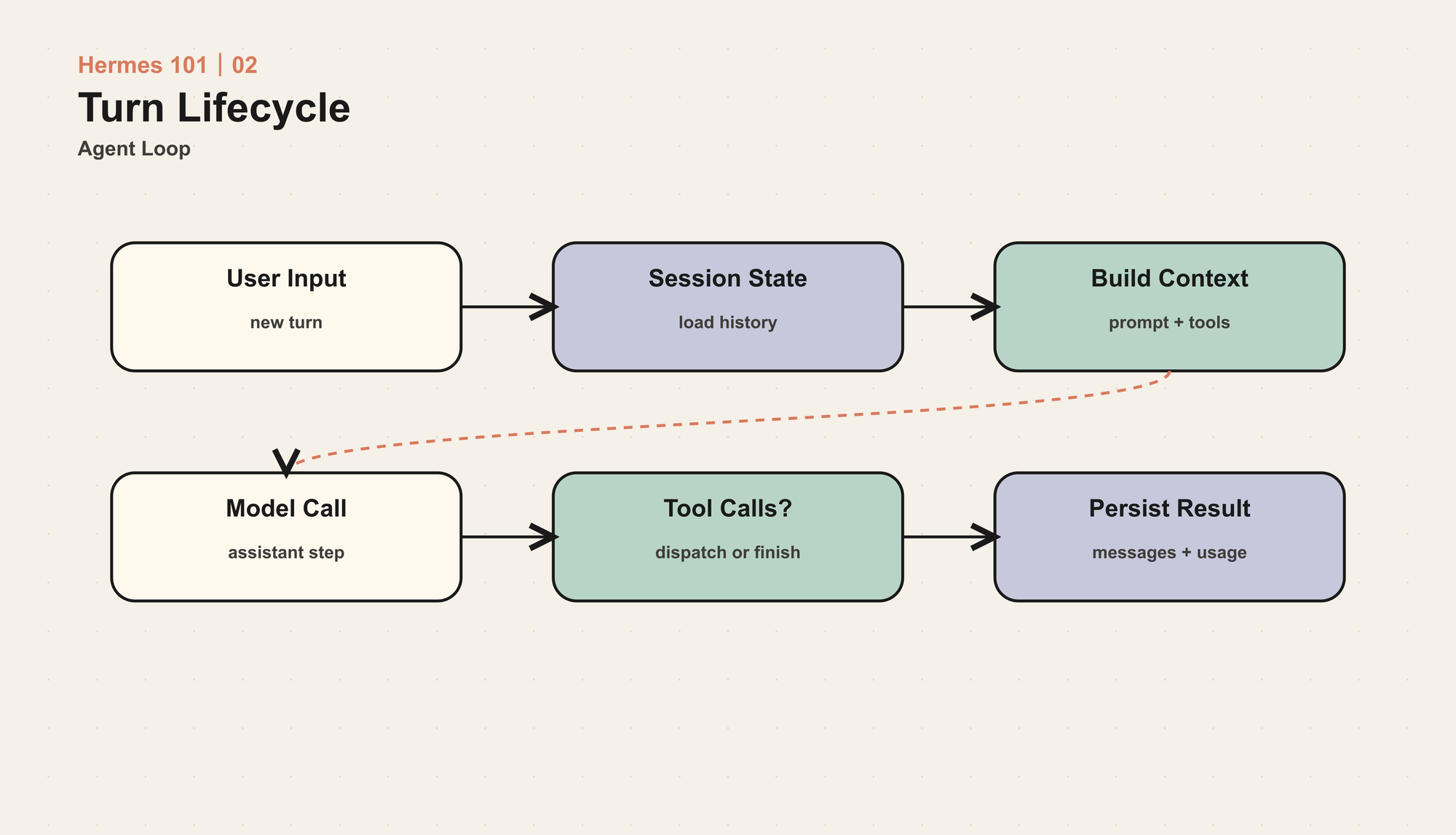
这条路径里有几个关键点。
用户消息不会直接被发给模型。Hermes 先创建或恢复 session,绑定日志上下文,设置当前 task id,清理上一次 provider 故障留下的连接,恢复 todo / memory nudge 状态,然后才把 user message 追加到内部消息列表里。
系统提示词也不是每次都重建。Hermes 会缓存 system prompt。继续会话时,它优先从 session store 取上一次保存的 system prompt,而不是读取最新 memory 再拼一遍。原因很现实:频繁改变系统提示词会破坏 prompt cache,也会让模型在同一个 session 里看到不一致的前缀。只有压缩等事件需要刷新时,系统提示词才会重新构造。
进入模型调用前,Hermes 会做 preflight compression 判断。如果上下文压力太高,中间历史会被压缩,最近消息和关键 tool call / tool result 配对会被保护。压缩不是 Agent Loop 的附属功能,它直接决定下一次模型调用能不能成立。
然后才是模型调用。Hermes 支持多种 API mode:OpenAI-compatible Chat Completions、OpenAI Codex Responses、Anthropic Messages。它们在外部协议上不同,但在 Agent Loop 内部会被整理成 OpenAI 风格的 messages:system、user、assistant、tool。
模型返回后,loop 分两条路:
- 如果有 tool calls,Hermes 执行工具,把结果按协议追加回 messages,然后继续下一轮模型调用。
- 如果没有 tool calls,Hermes 保存 session,刷新 memory,返回最终文本。
这就是表面的循环。但真正让它能工作的,是每一步周围的控制面。
消息顺序是硬约束
很多 Agent bug 看起来像“模型不听话”,实际是消息历史坏了。
对 tool calling 来说,消息顺序不是随便的聊天记录。一个 assistant 消息如果包含 tool_calls,后面必须有对应的 tool 消息。tool 消息必须带回正确的 tool_call_id。并行工具可以产生多个连续的 tool 消息,但它们仍然要和前一个 assistant 消息里的 tool_calls 对齐。
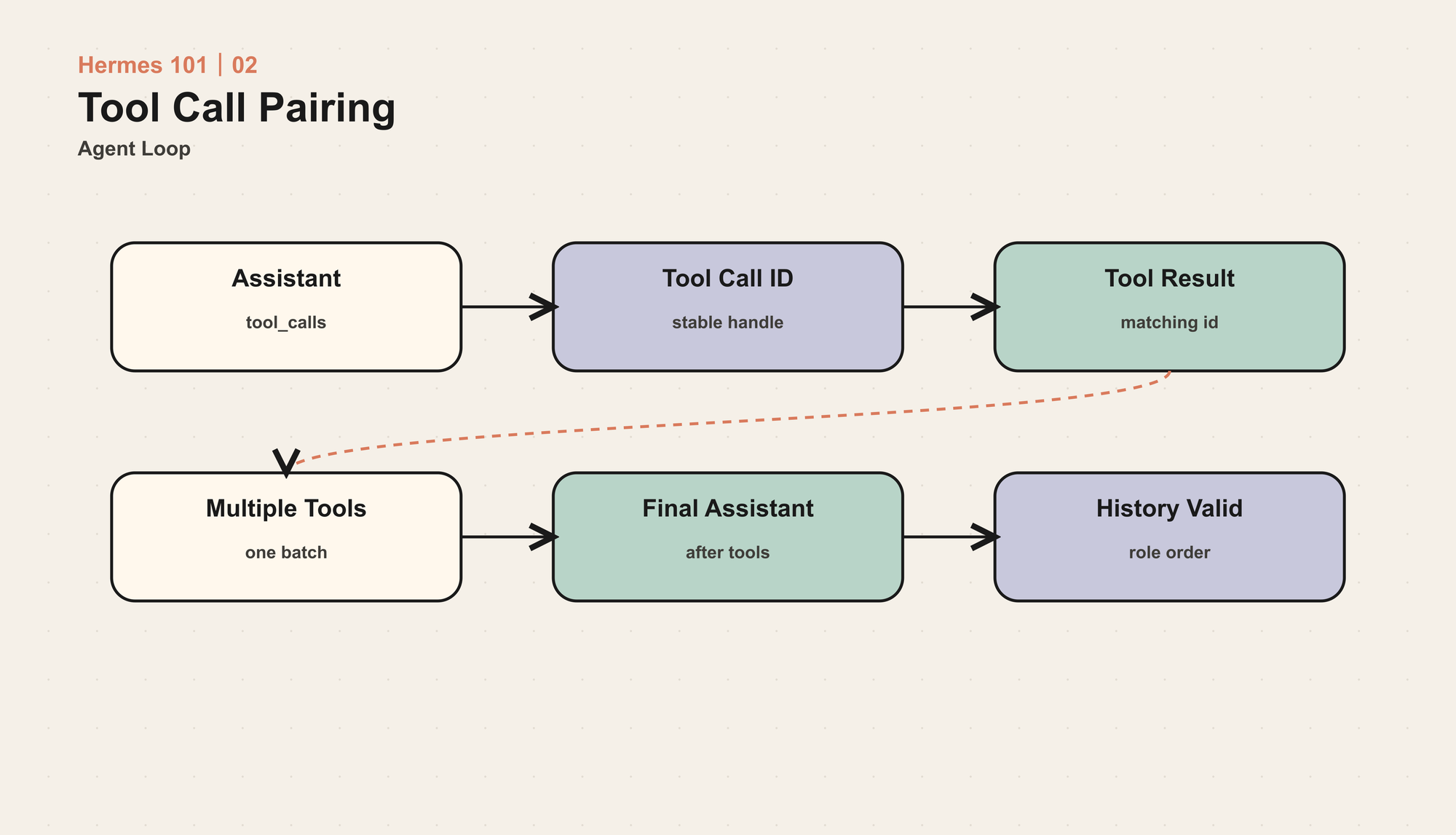
Hermes 文档里把这个约束写得很明确:系统消息之后,普通对话应该维持 User → Assistant 的交替;工具调用期间是 Assistant(with tool_calls) → Tool → Tool → Assistant。不能出现两个 assistant 连在一起,也不能出现两个 user 连在一起。只有 tool role 可以连续出现,因为多个工具结果可能属于同一个 assistant tool call 批次。
这个细节容易被低估。比如一个工具返回的是图片内容,而当前 provider 不支持 image_url。你不能简单删除这个 tool 消息,因为删除后前一个 assistant 的 tool_call 就没有匹配结果了。Hermes 的做法是把内容替换成文本占位符,保留 tool_call_id 链接,让消息历史仍然合法。
把这个规则抽象成类型,可以写成这样:
type AssistantToolMessage = {
role: "assistant"
content?: string
tool_calls: Array<{
id: string
function: { name: string; arguments: string }
}>
}
type ToolResultMessage = {
role: "tool"
tool_call_id: string
name?: string
content: string
}
function appendToolResults(
messages: Message[],
assistant: AssistantToolMessage,
results: ToolResultMessage[],
) {
const expected = assistant.tool_calls.map(call => call.id)
const actual = results.map(result => result.tool_call_id)
assertSameSet(expected, actual)
messages.push(assistant)
messages.push(...sortByToolCallOrder(results, assistant.tool_calls))
}
真正的实现还要处理 provider 差异、streaming、工具失败、打断和平台回调。但底层不变:tool result 不是日志,它是协议的一部分。
工具执行也有调度策略
模型一次可能返回多个 tool calls。最简单的做法是顺序执行。但顺序执行会浪费时间,尤其是多个 web search、read_file、session_search 彼此独立的时候。
Hermes 在 run_agent.py 里有一组并发判断规则。clarify 这种交互式工具不能并发;只读工具通常可以并发;文件工具要看路径是否重叠;其它有副作用或共享状态的工具默认走顺序路径。通过这套规则,Hermes 可以在安全时并发,在不确定时保守。
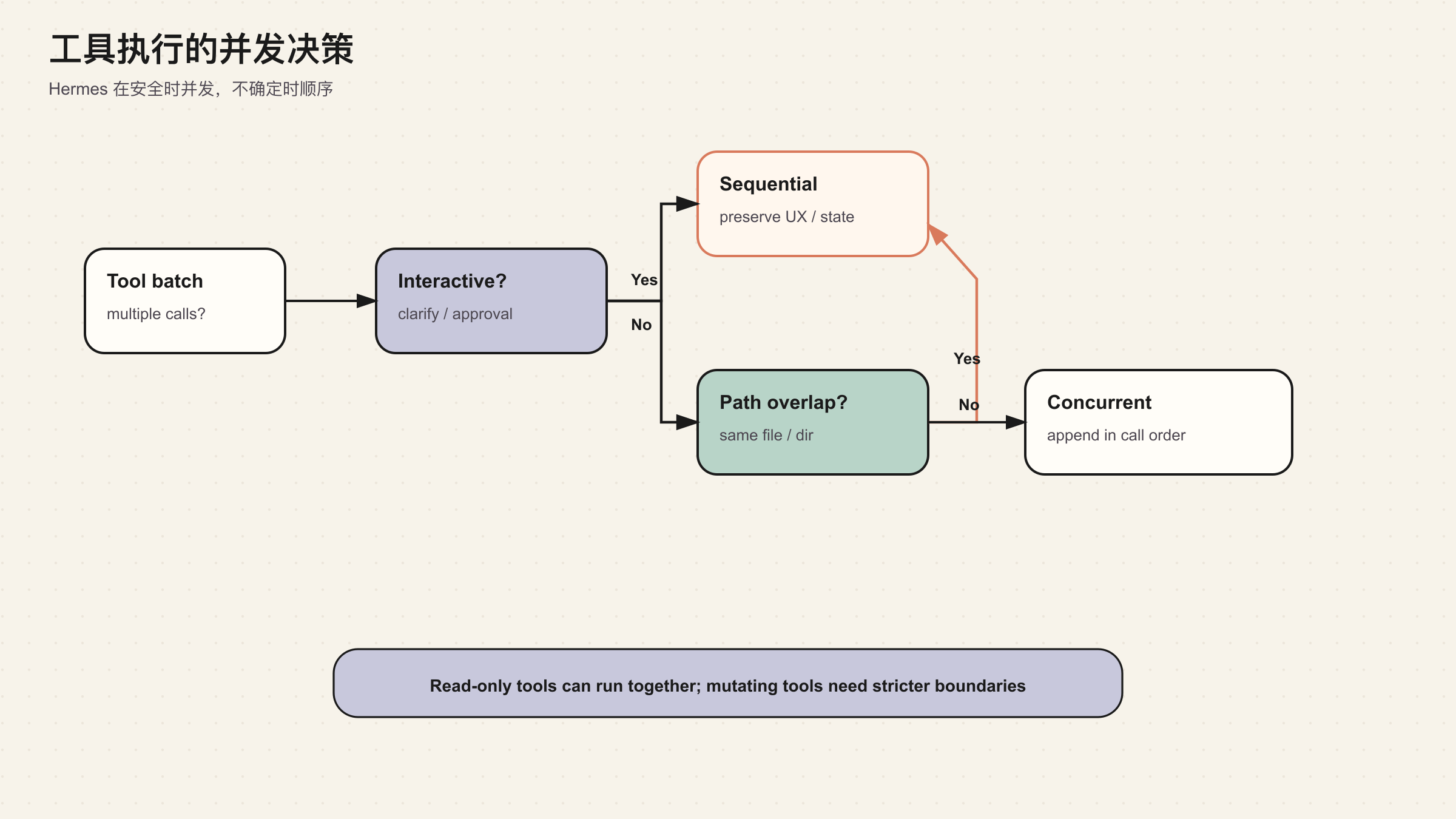
这看起来像性能优化,其实也是语义保护。
如果两个工具同时写同一个文件,结果不可预测。如果一个工具在等用户澄清,另一个工具继续修改系统,用户看到的状态就会混乱。如果工具结果按完成时间追加,而不是按原始 tool_call 顺序追加,某些 provider 可能拒绝消息,模型也可能把结果对应错。
所以并发工具执行至少要满足三个条件:
function shouldParallelize(calls: ToolCall[]): boolean {
if (calls.length <= 1) return false
const names = calls.map(call => call.name)
if (names.some(name => NEVER_PARALLEL.has(name))) return false
const reservedPaths: string[] = []
for (const call of calls) {
if (PATH_SCOPED_TOOLS.has(call.name)) {
const path = normalizePath(call.args.path)
if (overlapsAny(path, reservedPaths)) return false
reservedPaths.push(path)
continue
}
if (!PARALLEL_SAFE_TOOLS.has(call.name)) return false
}
return true
}
Hermes 的并发路径还有一个重要约束:结果按原始 tool_call 顺序写回 messages,而不是按哪个工具先完成写回。这是 Agent Loop 的协议纪律,不是显示层选择。
有些工具不能只走 registry
理想情况下,所有工具都在统一 registry 里注册,Agent Loop 只负责派发。Hermes 也基本这样做:每个工具文件通过 registry.register() 自注册,model_tools.py 负责发现工具、生成 schema、执行 handler。
但 Hermes 也有一类 agent-level tools,会被 AIAgent 截获,而不是直接走普通 registry。比如 todo、memory、session_search、delegate_task。它们之所以特殊,是因为它们不是纯外部能力,而是会触碰 Agent 自己的运行时状态。
todo读写当前 agent 的任务状态memory写入长期记忆,并可能通知外部 memory backendsession_search查询当前 session DB,并排除不该混入的上下文delegate_task会创建子 agent,继承或隔离部分运行时配置
这说明 Agent Loop 不是“模型发工具名,runtime blindly dispatch”。它必须知道哪些工具属于执行环境,哪些工具属于 Agent 自身的控制面。
一个更接近 Hermes 的派发结构是这样:
async function invokeTool(call: ToolCall, agent: AgentRuntime): Promise<string> {
const args = parseJsonOrEmpty(call.arguments)
const blocked = await agent.plugins.beforeToolCall(call.name, args)
if (blocked) return json({ error: blocked.message })
const guardrail = agent.guardrails.beforeCall(call.name, args)
if (!guardrail.allowed) return syntheticBlockedResult(guardrail)
switch (call.name) {
case "todo":
return agent.todoStore.apply(args)
case "memory":
return agent.memory.write(args)
case "session_search":
return agent.sessionSearch.query(args)
case "delegate_task":
return agent.delegation.spawn(args)
default:
return agent.toolRegistry.dispatch(call.name, args)
}
}
这个分层很重要。没有它,工具系统会变成一堆函数;有了它,工具系统才成为运行时的一部分。
API call 必须可打断
Agent Loop 里最难处理的不是工具,而是等待。
模型调用可能持续几十秒。用户可能在这期间改变主意,或者发 /stop。如果 API call 在主线程里阻塞,Agent 就无法及时响应。Hermes 的 _interruptible_api_call() 把实际 HTTP 请求放到后台线程,主线程同时等待三件事:response ready、interrupt event、timeout。
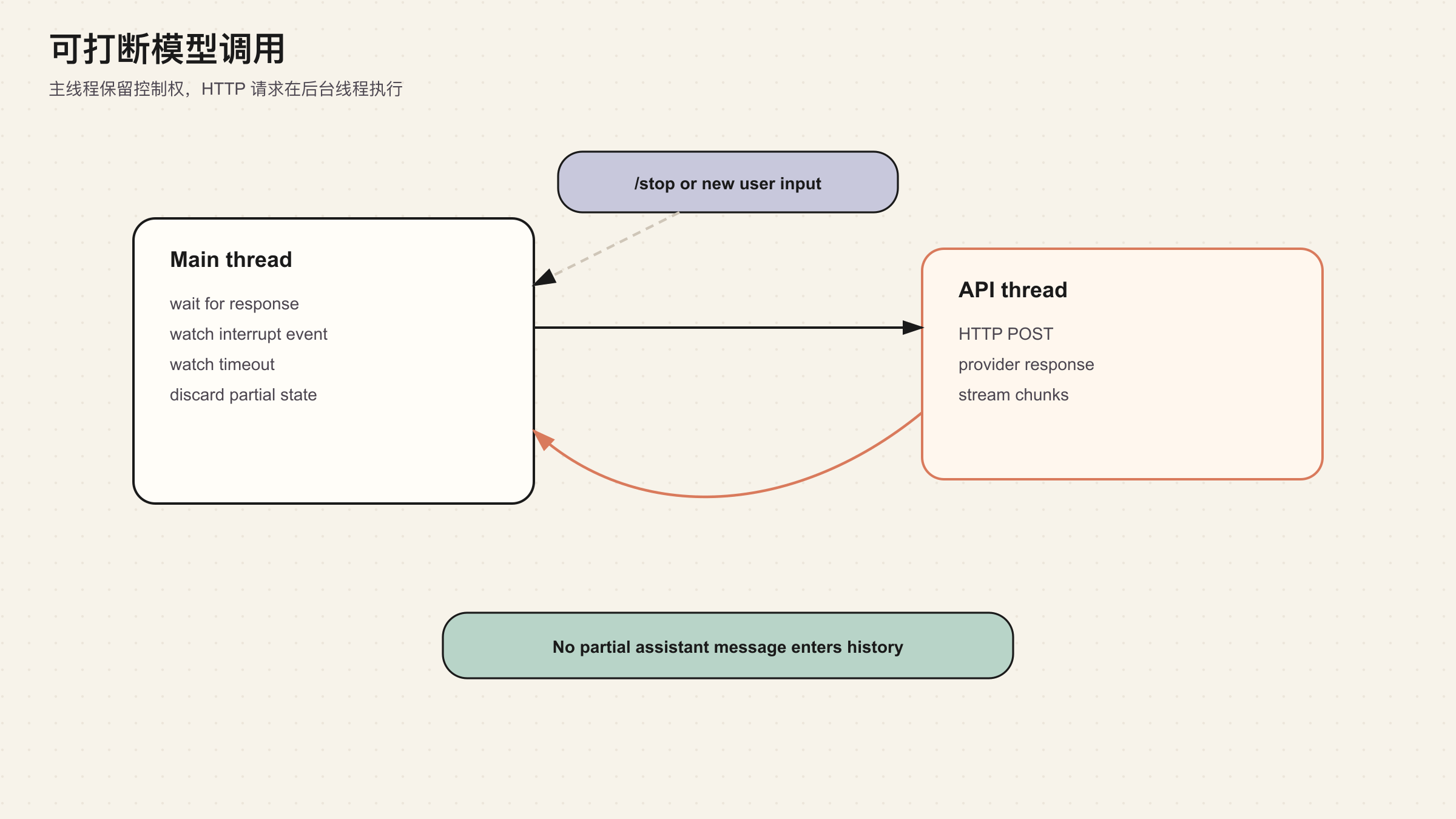
如果用户打断,Hermes 不会把半截响应塞进消息历史。它会丢弃那次响应,让 Agent 可以处理新的输入或干净退出。这一点很关键。半截 assistant message 如果进入 history,后面很容易出现两个问题:模型看到不完整状态;tool_call 配对关系被破坏。
可打断调用的伪代码大概是这样:
async function interruptibleCall(request: ModelRequest, signal: InterruptSignal) {
const apiPromise = runInBackgroundThread(() => provider.call(request))
while (true) {
if (signal.interrupted) {
apiPromise.abandon()
return { type: "interrupted" }
}
if (apiPromise.done) {
return { type: "response", value: apiPromise.result }
}
if (apiPromise.timedOut) {
return { type: "timeout" }
}
await sleep(50)
}
}
这不是为了用户体验的小优化,而是 Agent Runtime 的控制权问题。只要 Agent 会运行长任务,它就必须能被打断。
失败不是异常,是分支
真实 Agent Loop 里的失败路径很多。
provider 会返回 429、5xx、401/403。模型可能输出空内容。工具参数可能不是合法 JSON。Codex Responses 或 Anthropic Messages 可能有自己的停止原因。工具可能执行失败,但失败信息仍然要作为 tool result 回到模型,让模型决定下一步。
Hermes 把这些失败拆成几类处理:
- API 失败可以触发 credential refresh 或 fallback provider
- 无效 JSON / 无效工具调用有有限重试
- 工具失败会作为结构化结果返回,而不是直接崩掉 loop
- 上下文太长会触发压缩或上下文长度探测
- 达到 iteration budget 后,会请求模型总结已完成工作
这说明 Agent Loop 的退出条件不是简单的“没有 tool calls”。更完整的状态机至少包含:done、needs_tools、retryable_error、fallback、compress、interrupted、budget_exhausted。
type LoopState =
| { kind: "call_model" }
| { kind: "execute_tools"; calls: ToolCall[] }
| { kind: "compress_context" }
| { kind: "retry"; reason: string }
| { kind: "fallback_model"; provider: ProviderConfig }
| { kind: "interrupted" }
| { kind: "budget_exhausted" }
| { kind: "done"; text: string }
把失败当成状态,系统才有机会恢复。把失败当成异常,Agent 往往只能停止。
iteration budget 是安全边界
Agent Loop 如果不受限制,就可能陷入工具调用循环。模型一次次搜索、读文件、修补,再继续搜索。某些任务确实需要很多轮,但没有上限是不负责任的。
Hermes 用 IterationBudget 控制每个 turn 的模型调用轮数。默认上限是 agent.max_turns。达到上限后,Hermes 不会继续盲跑,而是要求模型总结当前完成情况。如果模型仍然不给最终文本,系统会强制收束。
这里的重点不是“省 token”。iteration budget 是三个边界:
- 成本边界:防止一次任务无限消耗模型调用
- 时间边界:防止用户等一个永远不结束的循环
- 副作用边界:防止 Agent 在不确定状态下继续执行工具
一个长期在线的 Agent,不能只相信模型会自己停下来。
Agent Loop 需要观测面
如果 Agent 只在终端里运行,print 日志勉强够用。但 Hermes 同时运行在 CLI、TUI、Gateway、ACP、Cron。不同入口需要不同反馈:终端要 spinner,消息平台要进度提示,IDE 要状态更新,Cron 要最终投递。
Hermes 在 AIAgent 上提供了多种 callback surface:tool progress、thinking、reasoning、clarify、step、stream delta、tool generation、status。Agent Loop 不直接关心 Telegram 或 IDE,但它会在关键节点发事件,让入口层决定怎样展示。
这就是“运行时”和“界面”的分离。Agent Loop 负责告诉外部:我开始思考了、我准备调用工具了、工具执行完了、我被打断了、我返回最终结果了。入口层负责把这些事件变成用户能理解的体验。
没有观测面,Agent 很容易变成黑盒。用户只看到它卡住,开发者也很难知道它卡在模型、工具、权限、网络还是上下文压缩。
一个更像生产系统的 Agent Loop
把上面的部分合起来,一个更接近生产系统的 Agent Loop 可以写成这样:
async function runConversation(input: UserInput, runtime: AgentRuntime) {
const taskId = runtime.ids.newTaskId()
const messages = await runtime.session.loadOrCreate()
runtime.logs.bindSession(runtime.session.id)
runtime.connections.cleanupStaleProviderSockets()
runtime.state.hydrateFromHistory(messages)
messages.push({ role: "user", content: input.text })
let systemPrompt = await runtime.prompt.getStablePrompt()
let apiCallCount = 0
while (true) {
if (!runtime.budget.consume()) {
return await runtime.model.requestSummary(messages)
}
if (runtime.context.shouldCompress(messages)) {
await runtime.memory.flush()
const compressed = await runtime.context.compress(messages)
messages.replaceWith(compressed.messages)
systemPrompt = await runtime.prompt.refreshAfterCompression()
}
const request = runtime.adapters.toProviderRequest({
systemPrompt,
messages,
tools: runtime.tools.schemas(),
})
const response = await runtime.model.callInterruptibly(request)
if (response.interrupted) {
return runtime.interrupts.cleanExit(messages)
}
if (response.retryableError) {
const recovered = await runtime.recovery.retryOrFallback(response.error)
if (recovered) continue
throw response.error
}
const assistant = runtime.adapters.toInternalAssistantMessage(response)
messages.push(assistant)
apiCallCount += 1
if (!assistant.tool_calls?.length) {
await runtime.session.save(messages)
await runtime.memory.flushIfNeeded()
return assistant.content ?? ""
}
const results = await runtime.tools.executeBatch({
calls: assistant.tool_calls,
taskId,
apiCallCount,
preserveOrder: true,
})
messages.push(...results)
await runtime.callbacks.step({ messages, apiCallCount })
}
}
这段伪代码比最小 loop 长很多,但它仍然省略了不少细节。现实中的 Hermes 还要处理 prompt caching marker、reasoning content、credential pool、provider capability detection、streaming scrubber、plugin hooks、checkpoint、approval callback、subagent iteration budget、memory nudge、skill nudge、文件变更验证等。
这正是重点:Agent Loop 的复杂度不是偶然堆出来的。它来自真实使用场景里的约束。
mini-agent-harness 应该怎样实现这一层
后面这个系列会持续使用一个极简学习框架 mini-agent-harness。如果要为它实现第二篇讨论的 Agent Loop,不应该一开始就复制 Hermes 的全部复杂度。更合理的做法是保留结构,压低规模。
最小版本可以包含这些模块:
type MiniAgentHarness = {
model: ModelClient
tools: ToolRegistry
session: SessionStore
prompt: PromptBuilder
context: ContextManager
budget: IterationBudget
callbacks: AgentCallbacks
}
第一版只需要支持一种 OpenAI-compatible tool calling 协议,一种本地 session store,一个同步工具执行器,一个简单的压缩占位接口。但接口要留对:messages 要保存 tool_call_id,tool registry 要区分 schema 和 handler,Agent Loop 要有 budget,模型调用要有可打断抽象,工具结果要按原始顺序回填。
学习框架的目标不是功能少,而是把关键边界暴露出来。
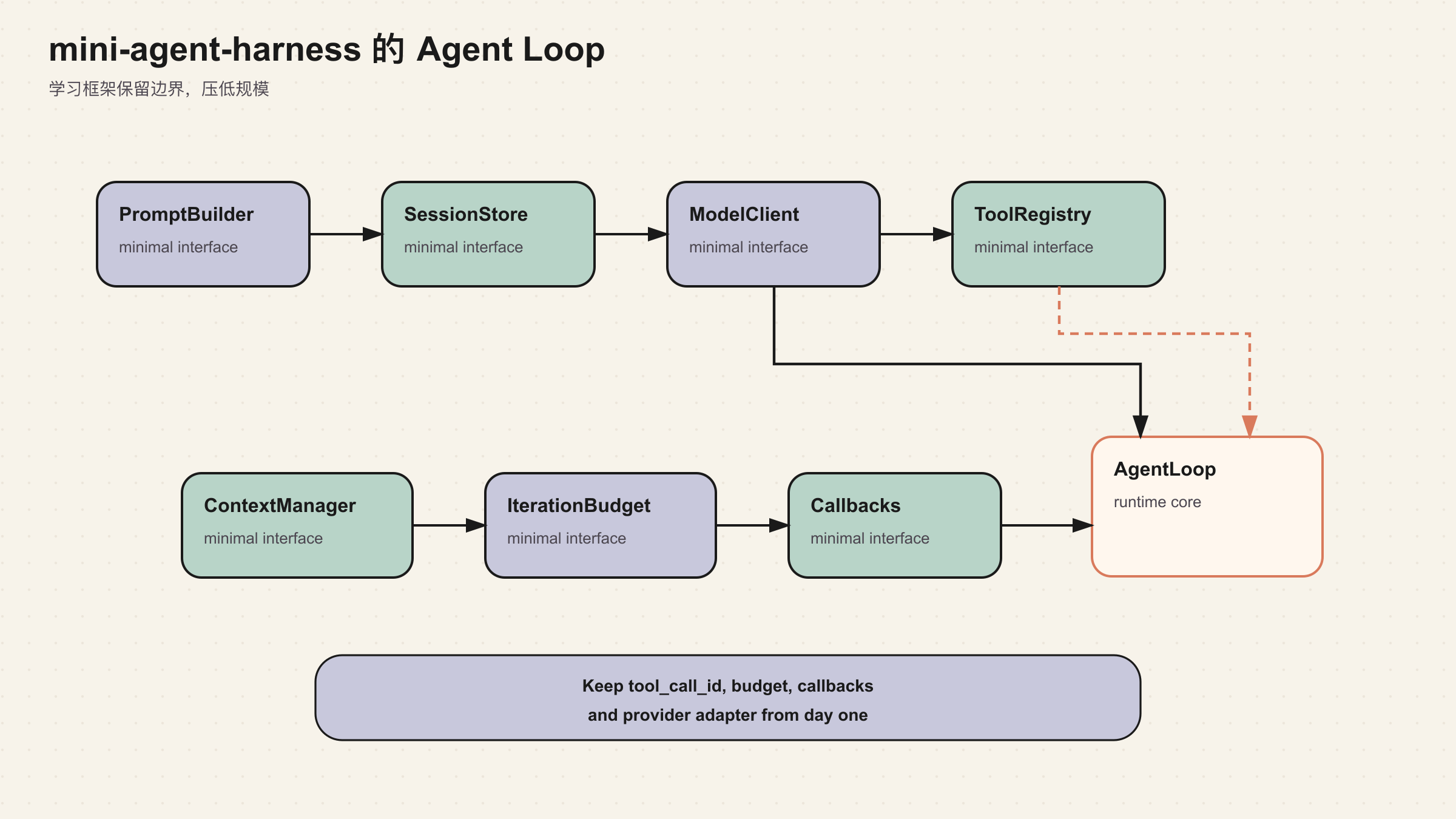
如果这个边界设计对了,后续加 memory、skills、gateway、cron、MCP、observability 都不会推翻 Agent Loop。它们只是接入同一个运行时状态机。
这篇的结论
Agent Loop 不是“问模型,调工具,再问模型”。那只是最外层的形状。
真正的 Agent Loop 至少要回答这些问题:
- 内部消息格式是什么?
- provider 协议差异在哪里被吸收?
- tool_call 和 tool_result 怎样保证配对?
- 哪些工具可以并发,哪些必须顺序?
- 工具失败是异常还是可供模型读取的结果?
- 用户打断时,正在进行的 API call 怎样处理?
- 上下文太长时,是压缩、降级,还是失败?
- 模型失败时,是重试、换 credential,还是 fallback provider?
- 循环什么时候必须停止?
- 状态何时保存,memory 何时 flush?
- 外部界面怎样观察 loop 的进度?
Hermes 的答案不是唯一答案,但它很完整。它把 Agent Loop 从“演示工具调用的 while 循环”推进成一套可恢复、可观测、可约束的运行时状态机。
这也是 Agent Engineering 的核心变化:我们不再只是在写 prompt,而是在设计一个会把模型输出变成真实操作的软件系统。
参考资料
- Hermes Agent README: https://github.com/NousResearch/hermes-agent
- Hermes Agent Agent Loop Internals: https://hermes-agent.nousresearch.com/docs/developer-guide/agent-loop
- Hermes Agent Tools Runtime: https://hermes-agent.nousresearch.com/docs/developer-guide/tools-runtime
- Hermes Agent Provider Runtime Resolution: https://hermes-agent.nousresearch.com/docs/developer-guide/provider-runtime
- Hermes Agent Context Compression and Caching: https://hermes-agent.nousresearch.com/docs/developer-guide/context-compression-and-caching
- Hermes Agent Session Storage: https://hermes-agent.nousresearch.com/docs/developer-guide/session-storage
- Anthropic, Building Effective Agents: https://www.anthropic.com/research/building-effective-agents
- Anthropic, Effective Context Engineering for AI Agents: https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
- Anthropic, Writing Effective Tools for AI Agents: https://www.anthropic.com/engineering/writing-tools-for-agents
- OpenAI Agents SDK docs: https://openai.github.io/openai-agents-python/