Hermes 101|01|Agent Runtime
模型不是 Agent 的全部。一个能长期工作的 Agent,需要工具、上下文、状态、记忆、调度、网关和可恢复的运行时。
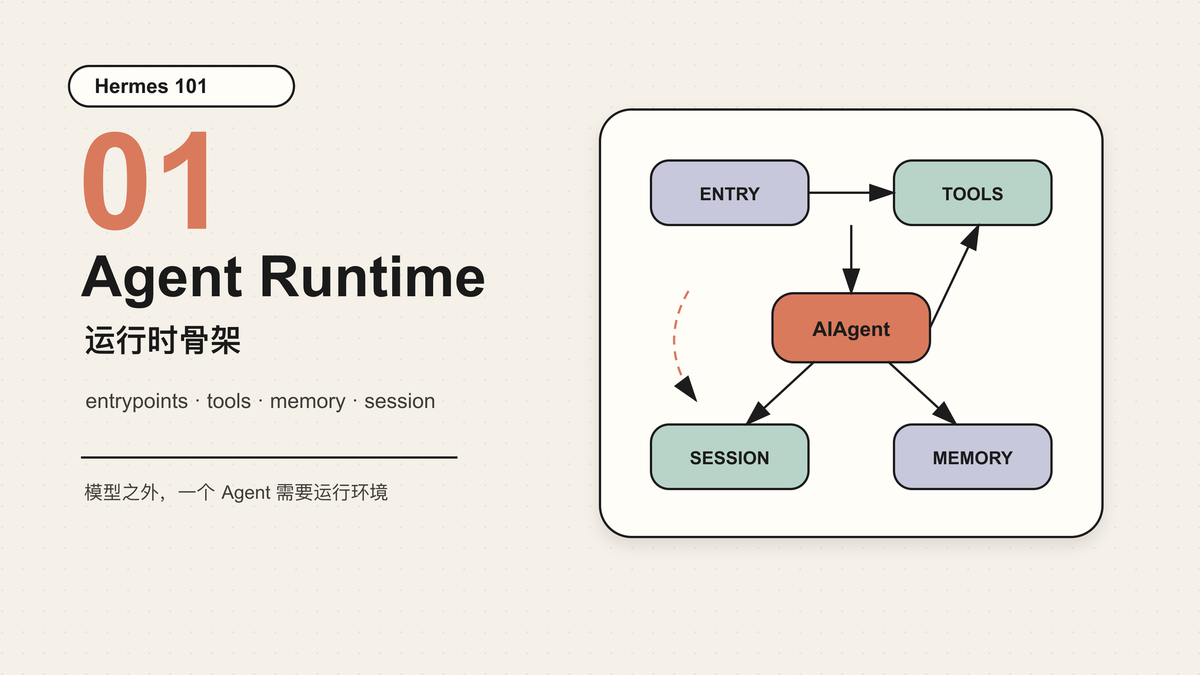
一个 Agent 系统最容易被误解的地方,是把模型看得太重,把运行时看得太轻。
大模型当然重要。没有足够强的模型,工具调用、代码修改、长任务规划都会变得脆弱。但模型不是 Agent 的全部。一个能长期工作的 Agent,必须把模型放进一套运行时里:它要知道自己有什么工具,怎样调用工具,怎样保存状态,怎样压缩上下文,怎样处理用户中途打断,怎样在失败后换模型重试,怎样把一次经验沉淀成下次可复用的技能。
Hermes Agent 的价值正在这里。它不是一个“把命令行包在聊天窗口里”的工具,也不是一个只负责转发 API 请求的壳。它更像一个面向 Agent 的运行时系统:模型只是其中一个模块,和工具系统、上下文系统、记忆系统、会话系统、网关、定时任务、插件机制一起工作。
这篇是 Hermes 101 的第一篇。我们先不深入每个模块的实现细节,而是建立一张系统地图:一个真实 Agent Runtime 需要哪些部件,Hermes 怎样把这些部件组织起来,以及为什么这套结构比“写一个更好的 prompt”更重要。
读完本文,你应该能回答
- Agent Runtime 和“调用模型的脚本”差在哪里?
- 为什么入口可以很多,但核心执行逻辑必须统一?
- 一个可长期运行的 Agent 至少需要哪些运行时部件?
- mini-agent-harness 应该先实现哪些最小能力?
本篇在系列中的位置
这是全系列的地图篇。前面没有预备章节;本篇先定义 Hermes 作为 Agent Runtime 的边界,后面几篇会把这张地图拆开:第 02 篇看 Agent Loop,第 03 篇看 Tool Runtime,第 04 篇看 Session Tree。
贯穿案例
贯穿这个系列,可以一直带着同一个任务来读:用户说“帮我修复这个 repo 里的 failing tests”。不同章节会回答同一个任务在运行时的不同问题:入口怎样进入、上下文怎样准备、模型怎样决定下一步、工具怎样执行、状态怎样保存、失败后怎样恢复。
一次任务的 Runtime 路线图
先用贯穿案例把总图落地:用户说“帮我修复这个 repo 里的 failing tests”时,Hermes 不是把这句话直接丢给模型,而是让它穿过一条运行时路线。
| 阶段 | Runtime 问题 | 主要机制 |
|---|---|---|
| 入口 | 请求从 CLI、Gateway、Cron 还是 IDE 进来? | entrypoint / adapter |
| 会话 | 这是新任务、继续任务,还是从旧 session 恢复? | Session Tree |
| 上下文 | 模型这一轮应该看到哪些规则、历史、技能和工具? | Context Builder |
| 决策 | 模型应该回答、调用工具,还是请求澄清? | Agent Loop |
| 行动 | 读文件、跑测试、改代码怎样受控执行? | Tool Runtime / permissions |
| 状态 | 工具结果、压缩摘要、记忆和日志怎样留下? | Session / Memory / Observability |
| 恢复 | 失败、打断、超长上下文或 provider 故障怎样处理? | Compaction / fallback / resume |
这张路线图是后面 13 篇的阅读骨架。每篇只是在放大其中一段:Loop 放大“决策”,Tool Runtime 放大“行动”,Context Builder 放大“模型能看到什么”,Gateway 和 Cron 放大“入口”,Provider Runtime 放大“模型调用本身”。
一张总图
Hermes 有很多入口:终端、TUI、消息平台、IDE、定时任务、批处理。它们最终都会进入同一个核心:AIAgent。
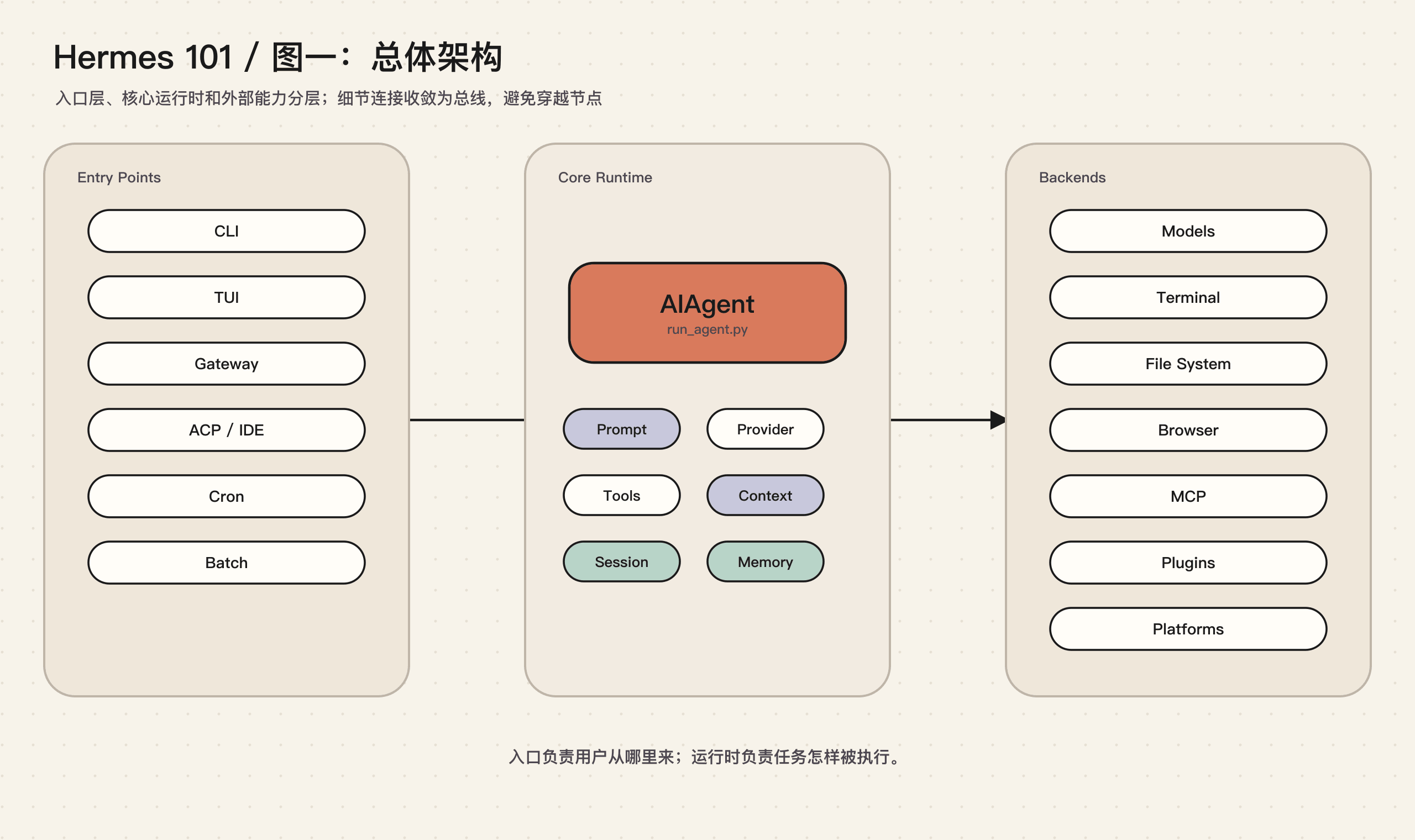
这张图里最重要的点不是模块数量,而是方向:入口可以很多,但执行核心应该统一。CLI、Telegram、Cron、IDE 不应该各自实现一套 Agent 逻辑。它们只是不同的用户界面和触发方式,真正的循环、工具调用、上下文处理、状态保存都应该在同一套运行时里。
Hermes 的设计基本遵循这个原则。cli.py 负责交互式终端体验,gateway/run.py 负责消息平台事件,cron/scheduler.py 负责定时任务,acp_adapter/ 负责 IDE 协议,但它们都会创建或调用 run_agent.py 里的 AIAgent。
这让 Hermes 有一个清晰的边界:入口层处理“用户从哪里来”,运行时处理“任务怎样被执行”。
Agent Runtime 包含什么
如果只看最小实现,一个 Agent Runtime 至少需要七个部分。
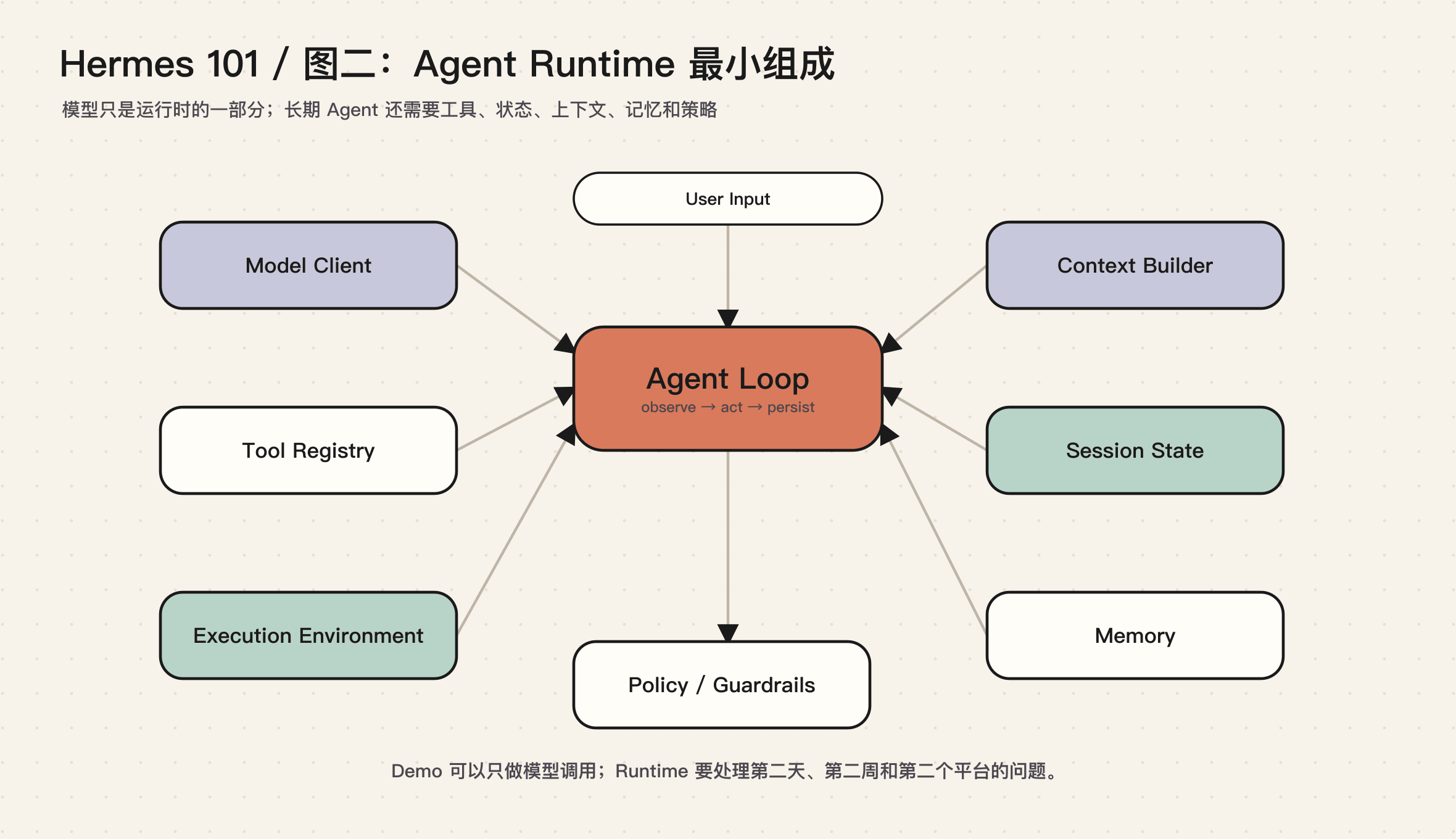
它们分别解决不同问题:
- Model Client 负责和模型通信
- Agent Loop 负责多轮调用和工具执行
- Tool Registry 负责告诉模型有哪些能力
- Execution Environment 负责真正执行命令、读写文件、访问浏览器或远端环境
- Context Builder 负责把身份、记忆、技能、项目上下文装配成 prompt
- Session State 负责保存历史、恢复会话、搜索过去的对话
- Policy / Guardrails 负责限制危险行为、审批命令、隔离权限
很多 Agent demo 只实现了前两个部分:调用模型,如果模型要求工具,就执行工具,再把结果塞回去。这足够演示 function calling,但不够支撑长期使用。
真正的问题会在第二天出现:
- 用户换到 Telegram 里继续同一个任务,状态在哪里?
- 模型跑到 100K token,上下文怎么压缩?
- 工具太多,模型选错工具怎么办?
- 命令可能删除文件,谁来审批?
- 任务需要每天早上自动执行,谁来调度?
- 这次踩过的坑,下次怎样不再踩?
- 主模型 429 或 500,系统怎样恢复?
- 插件带来新工具,怎样进入统一 schema?
Hermes 的源码基本就是围绕这些问题展开的。
中心是 AIAgent
Hermes 的核心类是 AIAgent。它不是一个简单的 LLM wrapper,而是一次对话执行的协调器。
它大致负责这些事:
- 组装系统提示词和工具 schema
- 解析当前应该使用哪个 provider、哪个 API mode、哪个 credential
- 调用模型
- 解析 tool calls
- 执行工具
- 维护 OpenAI 风格的消息历史
- 处理压缩、重试、fallback model
- 处理用户中断
- 触发 CLI、Gateway、ACP 所需的回调
- 保存会话和记忆
可以把它简化成这段 TypeScript 风格伪代码:
type Message = {
role: "system" | "user" | "assistant" | "tool"
content?: string
tool_calls?: ToolCall[]
tool_call_id?: string
}
class AIAgent {
constructor(
private model: ModelClient,
private tools: ToolRuntime,
private promptBuilder: PromptBuilder,
private sessionStore: SessionStore,
private contextEngine: ContextEngine,
private memory: MemoryManager,
) {}
async runConversation(userInput: string): Promise<string> {
const systemPrompt = await this.promptBuilder.build()
let messages: Message[] = await this.sessionStore.load()
messages.push({ role: "user", content: userInput })
messages = await this.contextEngine.maybeCompress(messages)
while (true) {
const response = await this.model.call({
system: systemPrompt,
messages,
tools: this.tools.schemas(),
})
messages.push(response.asAssistantMessage())
if (!response.tool_calls?.length) {
await this.memory.flushIfNeeded()
await this.sessionStore.save(messages)
return response.content ?? ""
}
const toolResults = await this.tools.execute(response.tool_calls)
for (const result of toolResults) {
messages.push({
role: "tool",
tool_call_id: result.toolCallId,
content: result.content,
})
}
}
}
}
真实 Hermes 比这复杂得多。它支持多种 API mode,比如 OpenAI-compatible Chat Completions、OpenAI Codex Responses、Anthropic Messages;它要处理 message alternation;它要在工具执行时发出 progress callback;它还要管理 iteration budget、fallback chain、credential pool、reasoning content、prompt caching、session lineage。
但核心结构没有变:Agent 是一个循环,不是一次请求。
一次请求怎样流动
一条用户消息进入 Hermes 后,大致会经历下面这条路径。
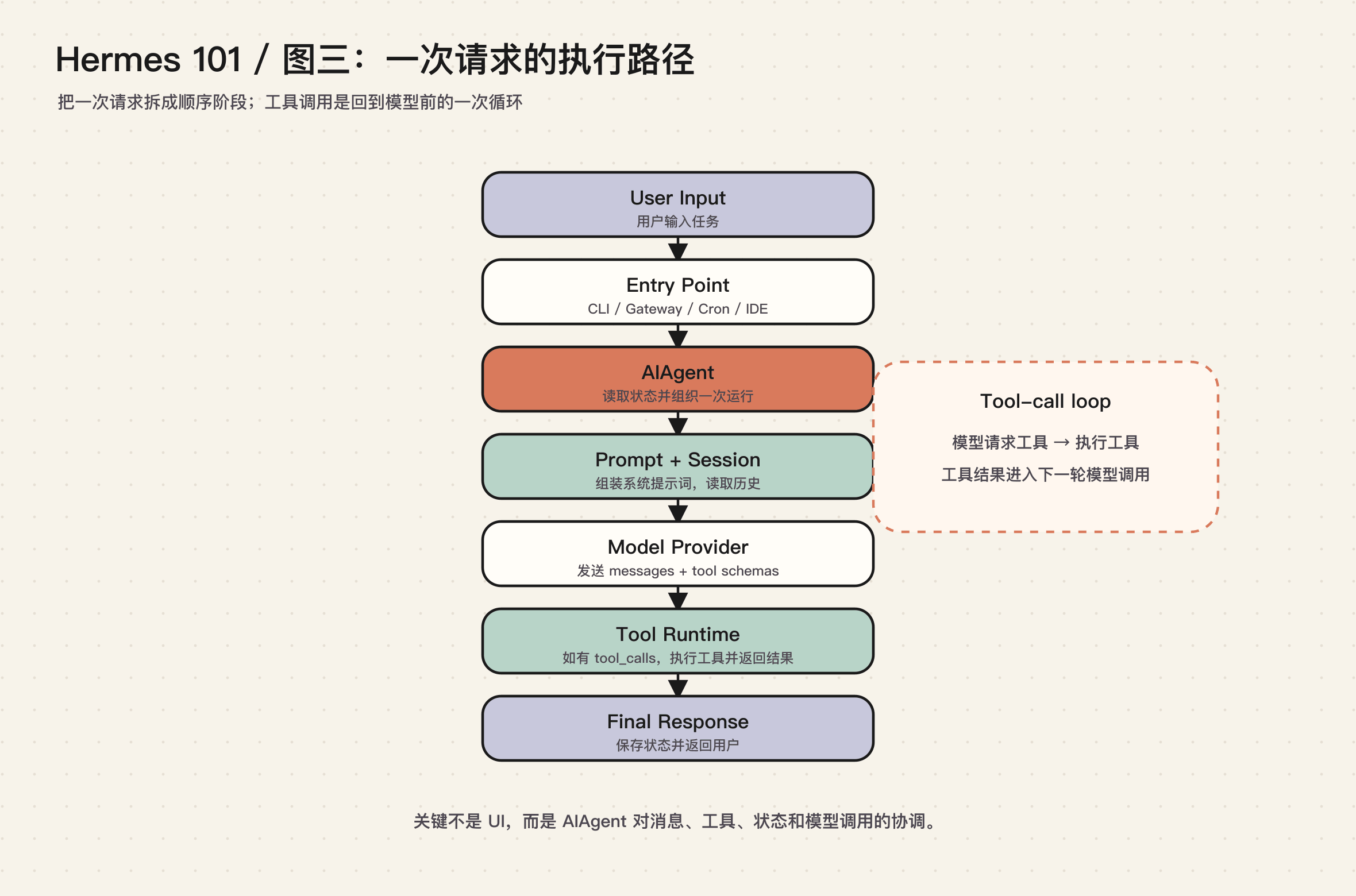
这条路径解释了为什么 Hermes 的核心不是 UI。UI 只是 Entry Point。真正让 Agent 可靠工作的,是 AIAgent 对消息、工具、状态、上下文和模型调用的协调。
Prompt 是装配出来的
在很多项目里,system prompt 是一段大字符串。Hermes 的做法更接近“上下文装配”。
一次会话开始时,Hermes 会把多个来源组合成系统提示词:
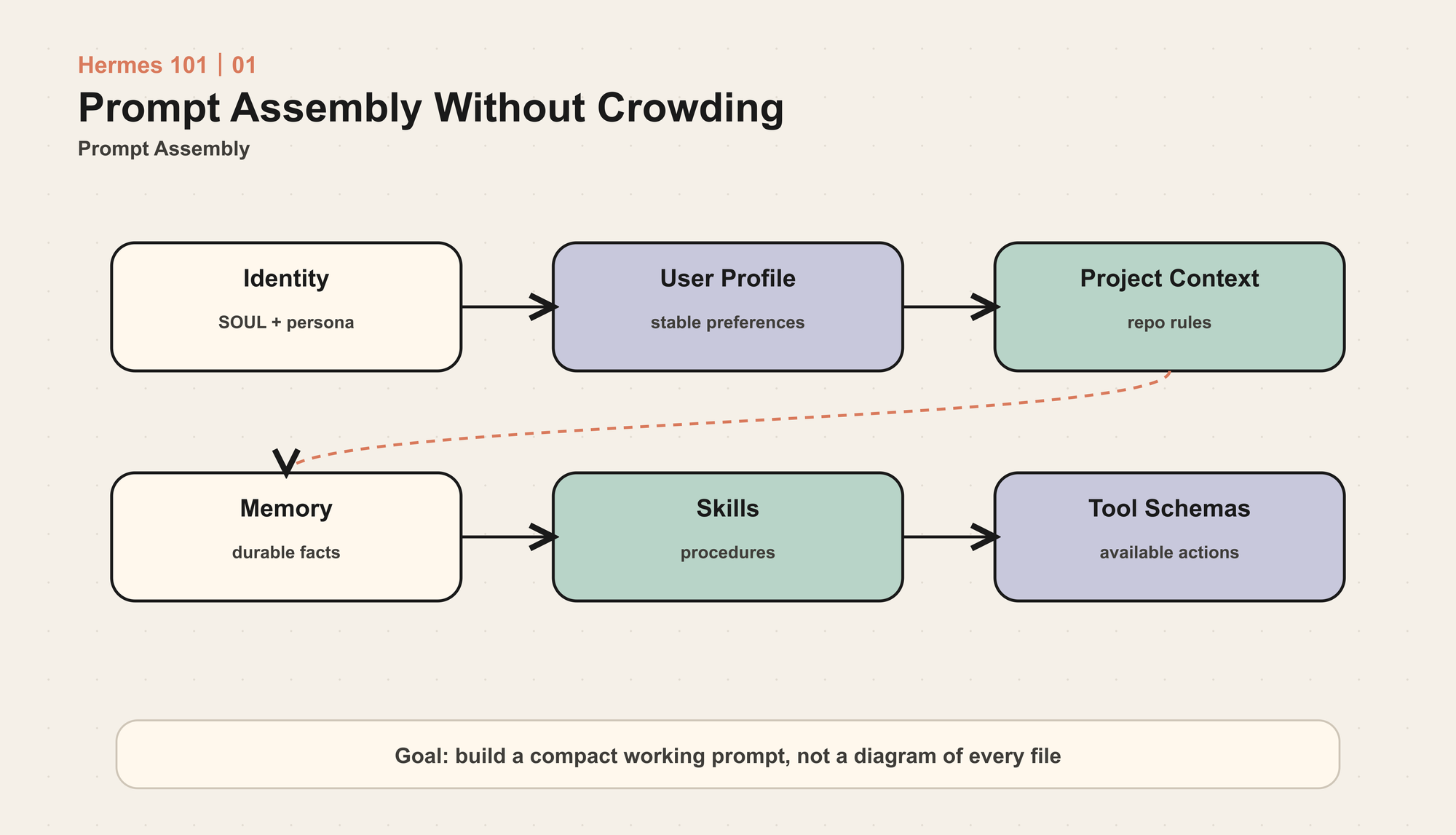
这里有一个重要取舍:系统提示词在会话中应尽量稳定。
原因很现实。系统提示词如果频繁变化,prompt caching 会失效,模型看到的前缀也会漂移。Hermes 因此区分两类上下文:
- 稳定层:身份、工具使用规则、记忆快照、技能索引、项目上下文
- 临时层:预算提醒、上下文压力、当前平台的某些 overlay、特定模型的 API call 附加信息
这个设计比“每次调用都重新拼一段 prompt”更复杂,但它解决的是生产系统里一定会遇到的问题:成本、缓存、可重复性、上下文一致性。
工具系统决定能力边界
Agent 能做什么,不取决于模型“知道”什么,而取决于运行时给了它什么工具。
Hermes 的工具系统由几个层次组成:
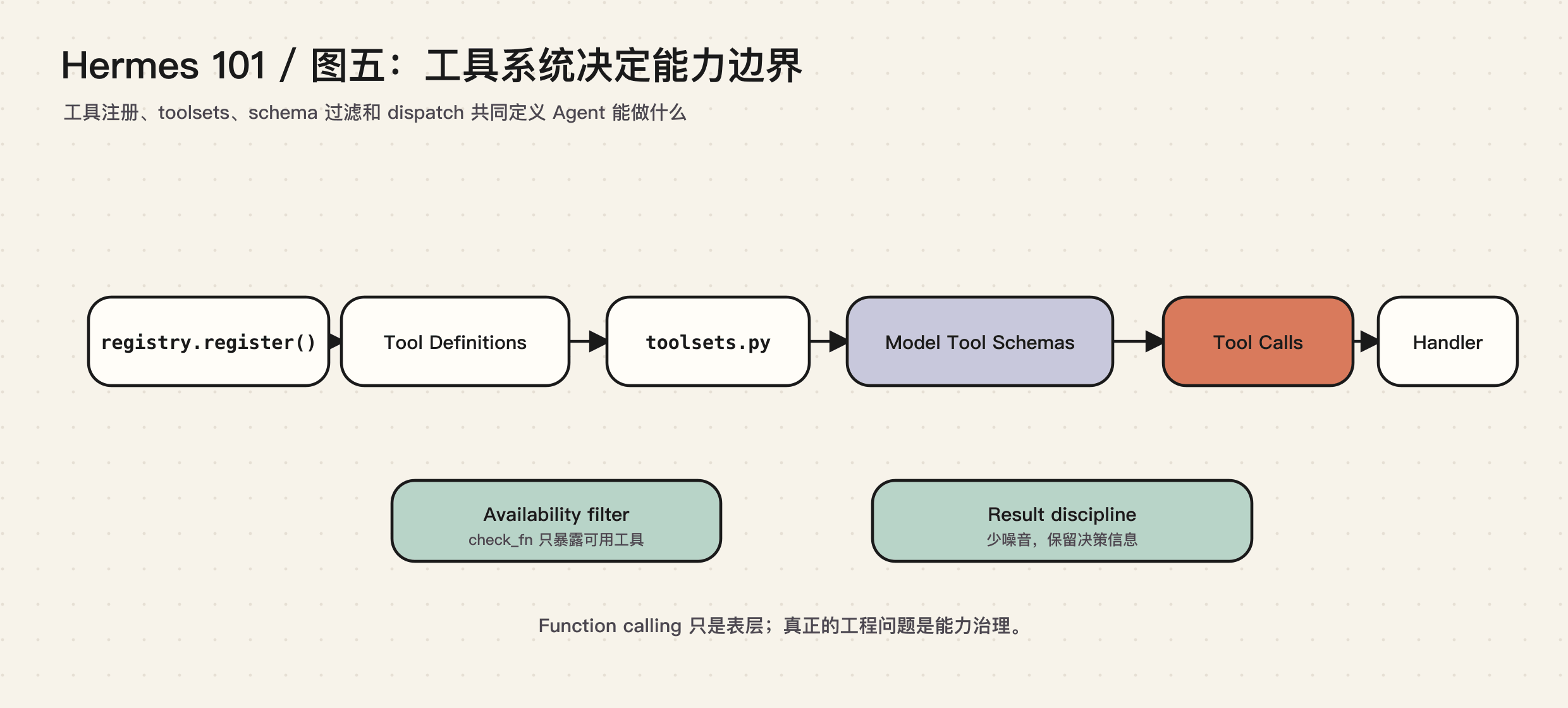
每个工具文件通过 registry.register() 自注册。model_tools.py 负责发现这些工具,过滤当前可用工具,生成给模型看的 schema,并在模型发起 tool call 时把请求派发到具体 handler。
这套机制的重点不是“能注册函数”,而是“能治理能力”。Hermes 通过 toolsets 控制不同平台、不同场景下的工具集合。例如:
- CLI 可以有 terminal、file、browser 等本地能力
- Cron job 需要禁用会造成递归的 cronjob 工具
- 某些平台不应该开放高风险工具
- Subagent 可以只拿到完成任务所需的最小工具集
- MCP 和插件工具可以动态进入系统,但仍通过统一 registry 暴露
工具系统的另一个关键点是返回内容。工具不是把所有 stdout 原样塞回模型就完事。返回内容越嘈杂,模型越容易被污染;返回内容越少,又可能缺少决策信息。这就是 Anthropic 在工具设计文章里强调的点:工具描述和工具结果都是上下文工程的一部分。
Hermes 把工具系统放在中心位置,是因为 Agent 的实际能力边界在这里。
状态让 Agent 能跨会话工作
一次性 demo 可以把 messages 放在内存里。长期 Agent 不能这样做。
Hermes 使用 SQLite 保存 session 和 messages。它不只是保存聊天记录,还保存:
- session source,例如 cli、telegram、discord
- model 和 provider 信息
- token usage
- tool call count
- cost 信息
- reasoning 字段
- parent_session_id
- FTS5 搜索索引
- CJK / substring search 用的 trigram FTS
可以把它看成 Agent 的状态层。
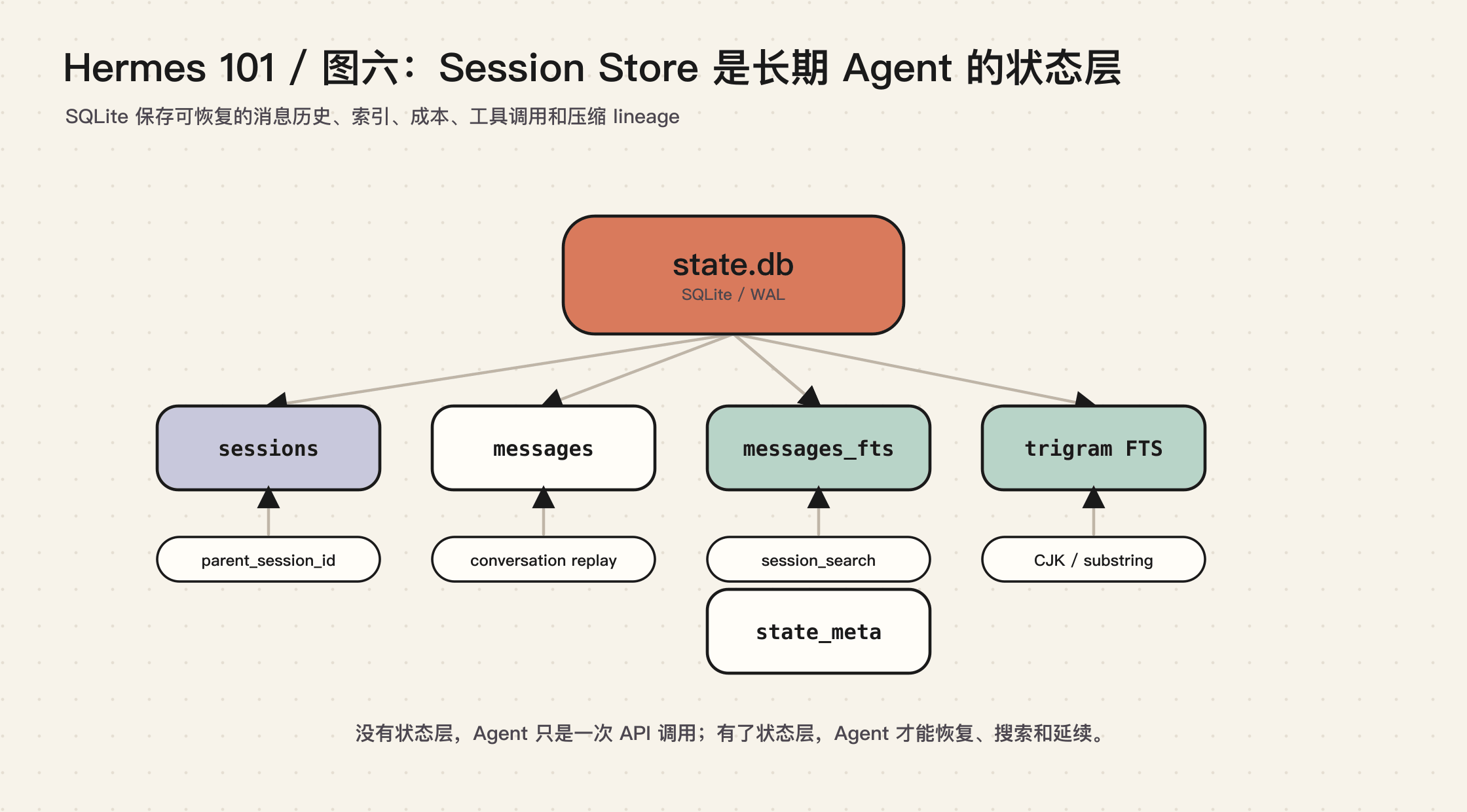
这件事听起来普通,但它改变了 Agent 的性质。
有了 session store,Agent 可以恢复过去的上下文,可以搜索历史会话,可以在压缩后维护 lineage,可以按平台隔离会话,可以统计成本和工具调用。它不再是“一次 API 调用的临时对象”,而是一个可恢复的长期系统。
Context 不会自己变干净
长任务里,上下文会逐渐变脏。
工具输出、错误日志、文件内容、搜索结果、用户中途改变主意、模型的中间推理,都会挤占上下文窗口。更长的 context window 可以缓解问题,但不能消除问题。窗口越长,噪音也越容易被长期保留下来。
Hermes 的 ContextCompressor 做的是运行时层面的上下文治理:
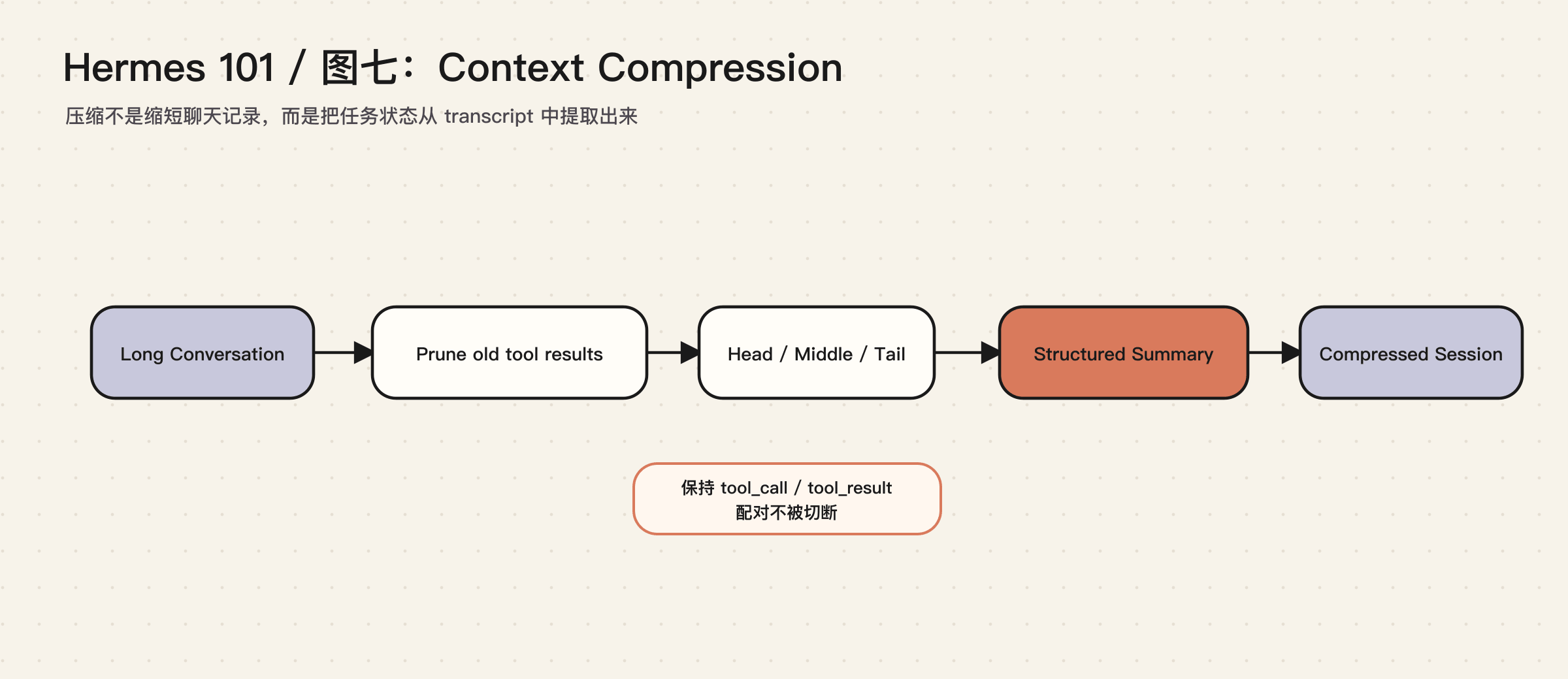
它会保护开头的关键消息和最近的 tail,把中间部分压缩成结构化摘要,并避免切断 tool_call 与 tool_result 的配对。Gateway 还有一个更高阈值的 session hygiene,用来防止长期消息平台会话在进入 Agent 前就爆掉。
这里的重点不是“摘要聊天记录”。好的压缩应该保存任务状态:目标、约束、已完成内容、关键决策、相关文件、阻塞问题、下一步。Hermes 的摘要模板正是按这个方向设计的。
Memory 和 Skills 分工不同
Hermes 的一个核心卖点是 self-improving。这个词容易被误解,好像 Agent 会自己变聪明。更准确地说,Hermes 让经验有地方沉淀。
沉淀分两类。
第一类是 memory:稳定事实。
例如:
- 用户偏好中文
- 某个项目使用特定测试命令
- 某个环境里某个工具有已知限制
第二类是 skills:可复用流程。
例如:
- 怎样发布 Ghost 文章
- 怎样做 GitHub PR review
- 怎样运行某个项目的测试和部署流程
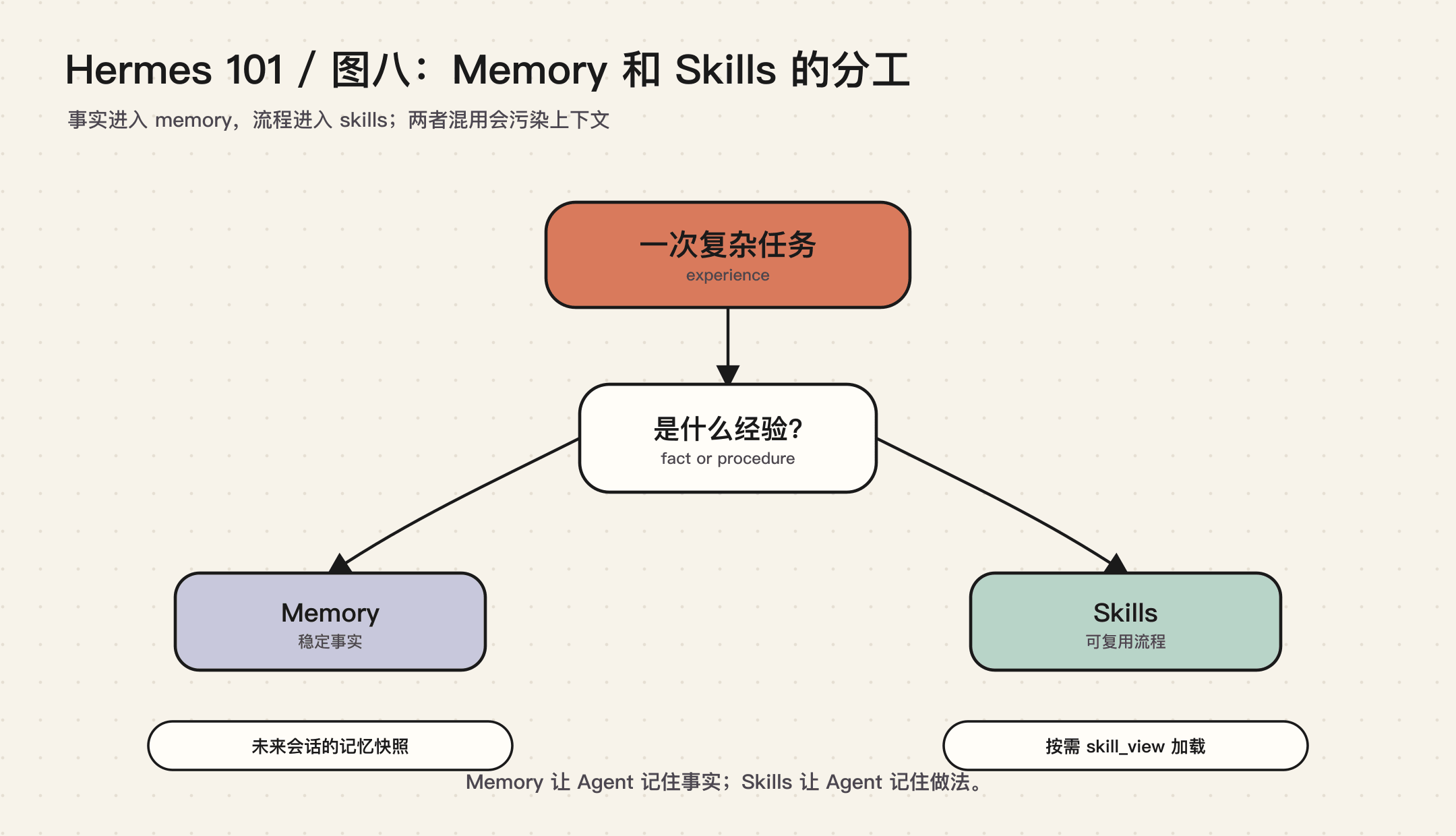
这个分工很重要。把流程写进 memory,会污染每一次会话;把事实写成 skill,又会让简单偏好变得难以检索。Hermes 的设计接近 Claude Code 的建议:memory 保存每次都应该知道的事实,skills 保存按需加载的操作程序。
Gateway 让 Agent 离开终端
很多 coding agent 默认活在本地终端里。Hermes 的 gateway 把它变成长期在线服务。
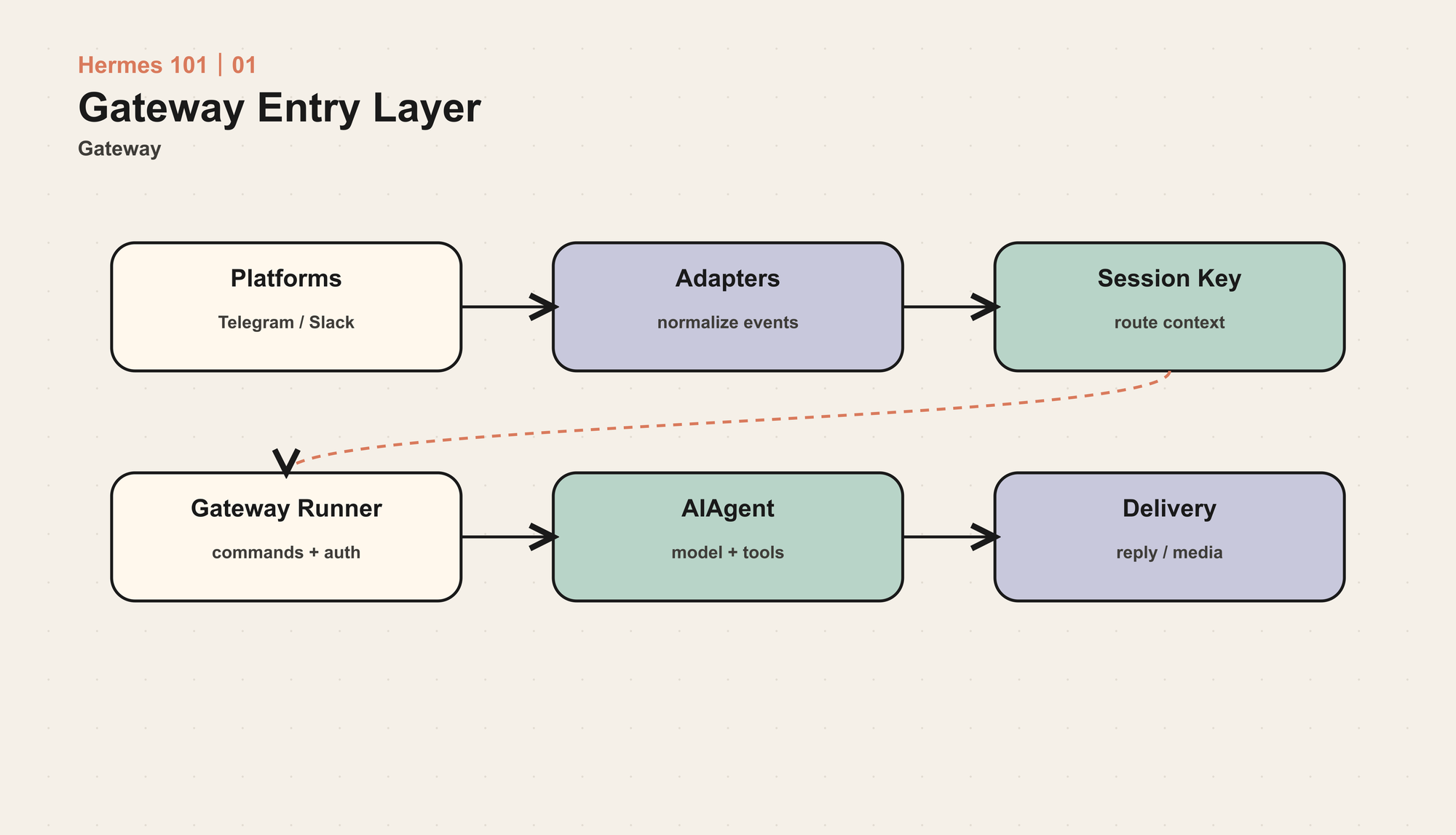
Gateway 的价值不是“支持很多平台”这个数字本身,而是它把 Agent 的运行方式从“我打开终端问一句”变成“我在任何入口都能触发同一个运行时”。
这带来新的工程问题:
- 用户身份怎样授权?
- 同一个 chat/thread 怎样映射到 session?
- Agent 正在运行时,用户又发了一条消息怎么办?
/approve、/deny、/stop怎样绕过普通队列?- Cron 结果怎样投递到 home channel?
- 发送到平台的消息要不要写回当前会话?
Hermes 的 gateway 层处理这些问题,核心 Agent Loop 不需要知道 Telegram 或 Slack 的细节。
Cron 把 Agent 变成异步工作流
Agent 如果只能被动响应用户输入,价值会受限。很多任务本来就是异步的:每天早上汇总新闻,每小时检查服务,每周生成报告,有变化才提醒。
Hermes 的 cron 不是传统 shell cron 的替代品。它调度的是 Agent 任务。
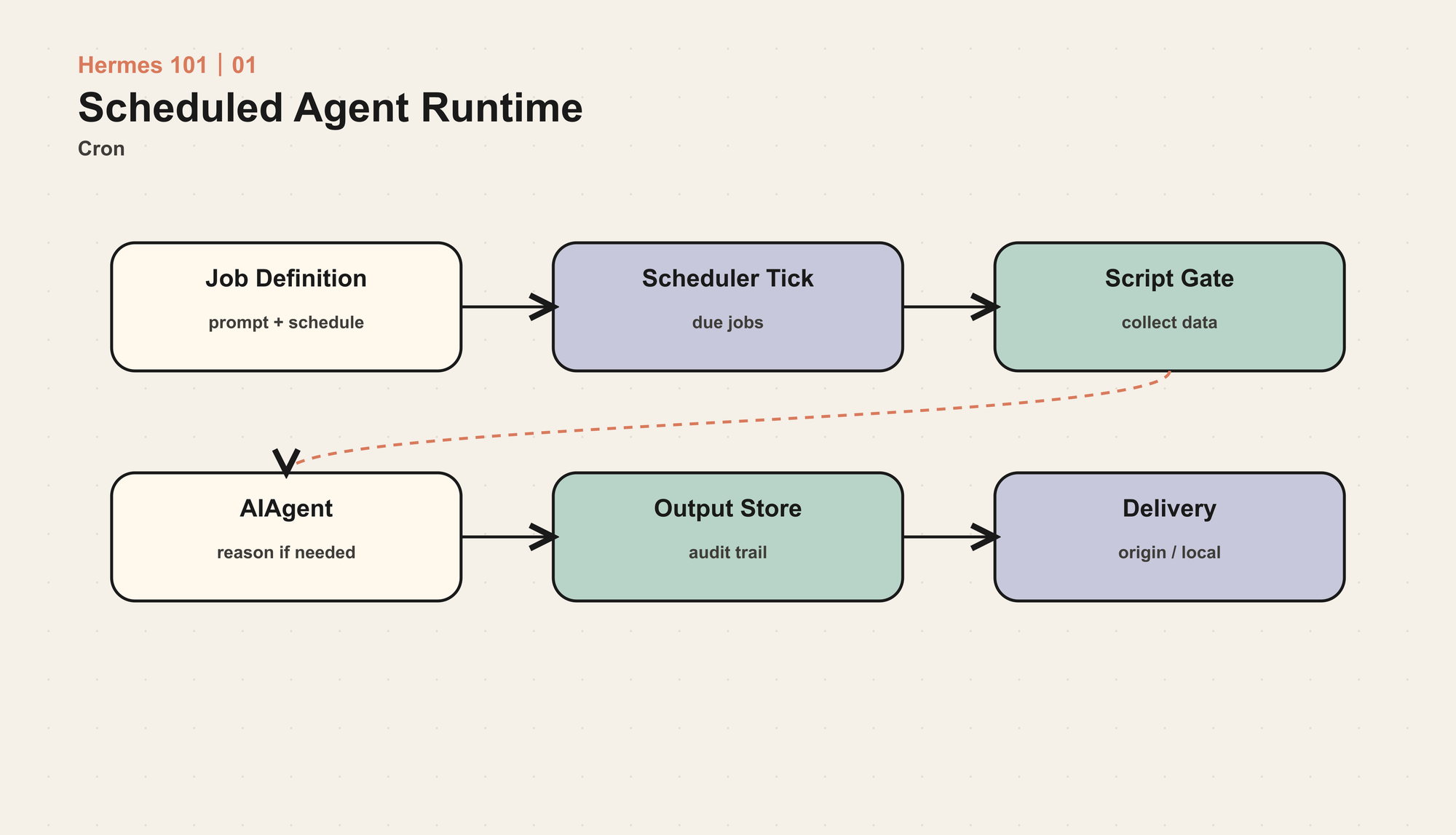
关键点是 fresh session。Cron job 不继承当前聊天上下文,因此 prompt 必须自包含。它可以加载 skills,可以运行脚本收集数据,可以把结果发到指定平台,也可以在 no_agent 模式下只执行脚本。
这其实是一种 Agent workflow:把 LLM 的判断能力、工具能力、平台投递能力放进定时任务系统里。
一个更准确的定义
到这里,我们可以给 Hermes 这样的系统一个更准确的定义。
一个 Agent Runtime 至少包含:
type AgentRuntime = {
entrypoints: Entrypoint[]
loop: AgentLoop
modelRouter: ProviderResolver
promptBuilder: PromptBuilder
toolRuntime: ToolRuntime
executionEnvironments: Environment[]
sessionStore: SessionStore
memory: MemorySystem
skills: SkillSystem
contextEngine: ContextEngine
policy: Guardrails
scheduler: CronScheduler
pluginSystem: PluginSystem
observability: LogsAndCallbacks
}
这个定义把 Agent 从“会调用工具的模型”推进到“可运行的软件系统”。
Hermes 的源码说明了一件事:Agent Engineering 的重点不是给模型更多指令,而是给模型一个更可靠的运行环境。模型负责判断下一步,运行时负责让下一步可执行、可观察、可恢复、可约束。
这也是 Hermes 101 后续文章要展开的主线。
这一系列会讲什么
后面的文章会沿着 Hermes 的运行时结构往下拆:
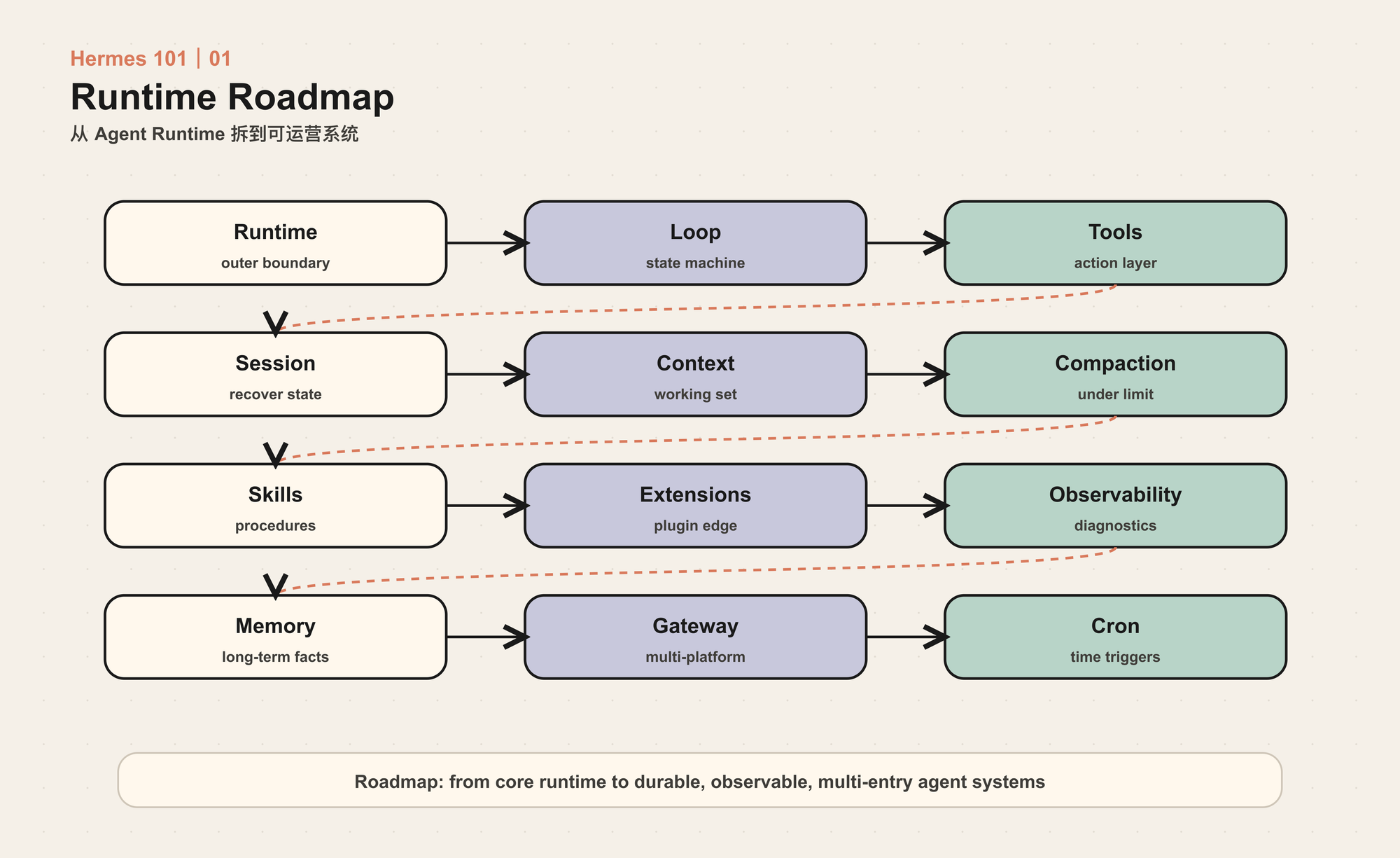
每一篇都会从一个工程问题开始,而不是从功能介绍开始。比如:
- Agent Loop 怎样处理工具调用?
- Prompt 为什么需要稳定前缀?
- 工具系统怎样限制能力边界?
- 长任务为什么需要 session lineage?
- Memory 和 Skills 为什么不能混用?
- Gateway 怎样处理用户中途打断?
- Cron job 为什么必须是 fresh session?
- 插件、MCP、ACP 怎样扩展 Agent Runtime?
Hermes 只是一个案例,但它足够完整。通过它可以看到现代 Agent 系统正在形成的一套工程共识:上下文要治理,工具要分层,状态要持久化,执行要可观察,权限要可控,经验要能沉淀。
模型会继续变强,但运行时不会消失。相反,模型越强,运行时越重要。因为更强的模型会尝试做更复杂、更长、更有副作用的任务。没有运行时,它只是一次聪明的回复;有了运行时,它才可能成为一个可用的 Agent。
参考资料
- Hermes Agent README: https://github.com/NousResearch/hermes-agent
- Hermes Agent Architecture docs: https://hermes-agent.nousresearch.com/docs/developer-guide/architecture
- Hermes Agent Agent Loop Internals: https://hermes-agent.nousresearch.com/docs/developer-guide/agent-loop
- Hermes Agent Tools Runtime: https://hermes-agent.nousresearch.com/docs/developer-guide/tools-runtime
- Hermes Agent Prompt Assembly: https://hermes-agent.nousresearch.com/docs/developer-guide/prompt-assembly
- Hermes Agent Context Compression and Caching: https://hermes-agent.nousresearch.com/docs/developer-guide/context-compression-and-caching
- Hermes Agent Session Storage: https://hermes-agent.nousresearch.com/docs/developer-guide/session-storage
- Anthropic, Building Effective Agents: https://www.anthropic.com/research/building-effective-agents
- Anthropic, Effective Context Engineering for AI Agents: https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
- Anthropic, Writing Effective Tools for AI Agents: https://www.anthropic.com/engineering/writing-tools-for-agents
- OpenAI Agents SDK docs: https://openai.github.io/openai-agents-python/