很多人第一次实现 Agent 时,会把对话历史放在一个数组里:
const messages: Message[] = []
每轮用户输入追加一条 user message,模型回复追加一条 assistant message,工具调用再追加 tool message。只要 demo 还在一个进程里运行,这个结构看起来足够清楚。
但真实 Agent 很快会遇到更难的问题:用户明天要恢复今天的任务;上下文太长时需要压缩;一次任务可能分出多个探索方向;同一个 Agent 可以从 CLI 切到 Telegram 或 Discord;用户会问“上次我们怎么修的那个问题”;系统还要知道每个 session 用了多少 token、花了多少钱、是否还在运行。
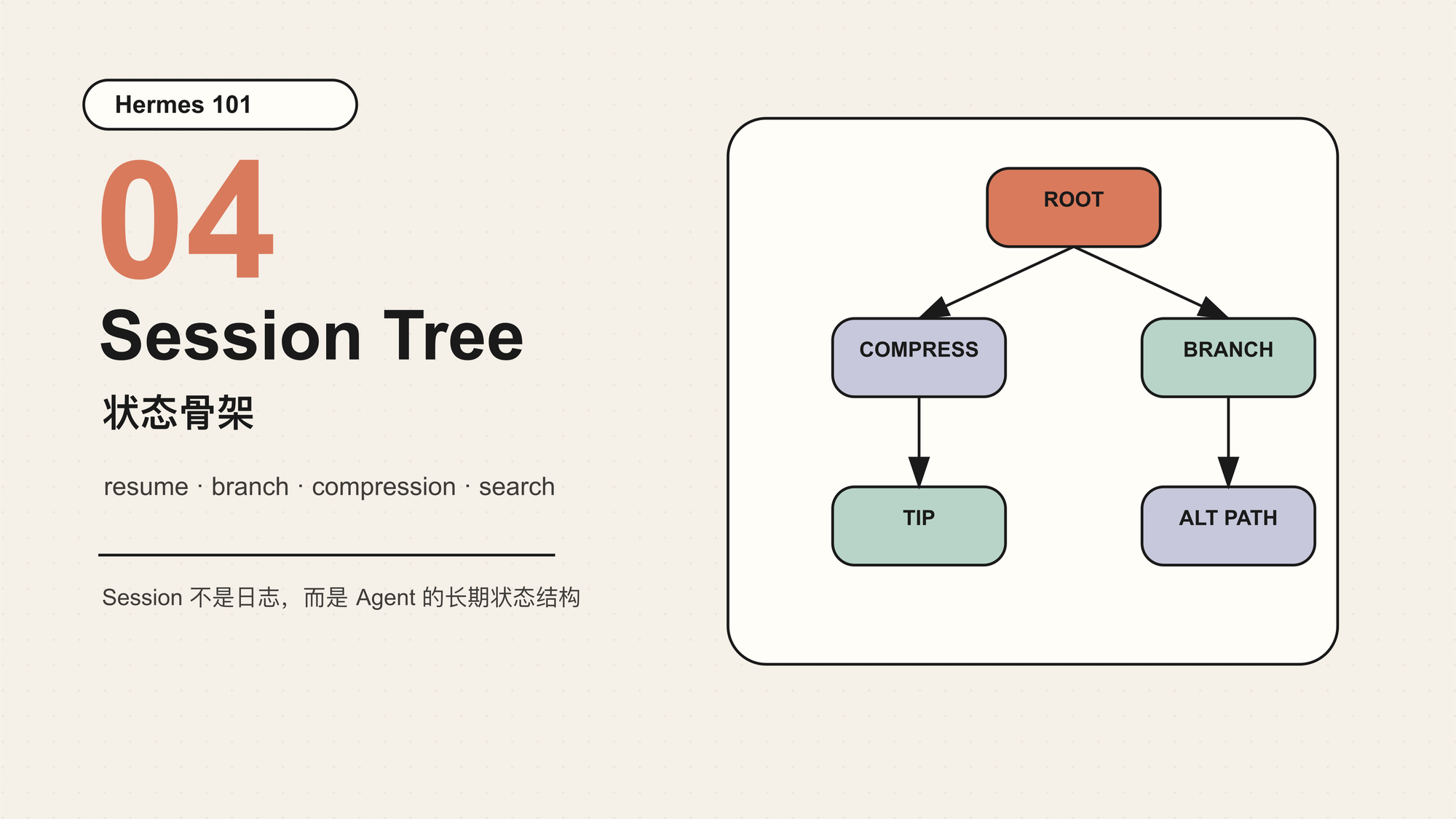
这时,messages[] 已经不够了。Agent 需要的是一棵 Session Tree。
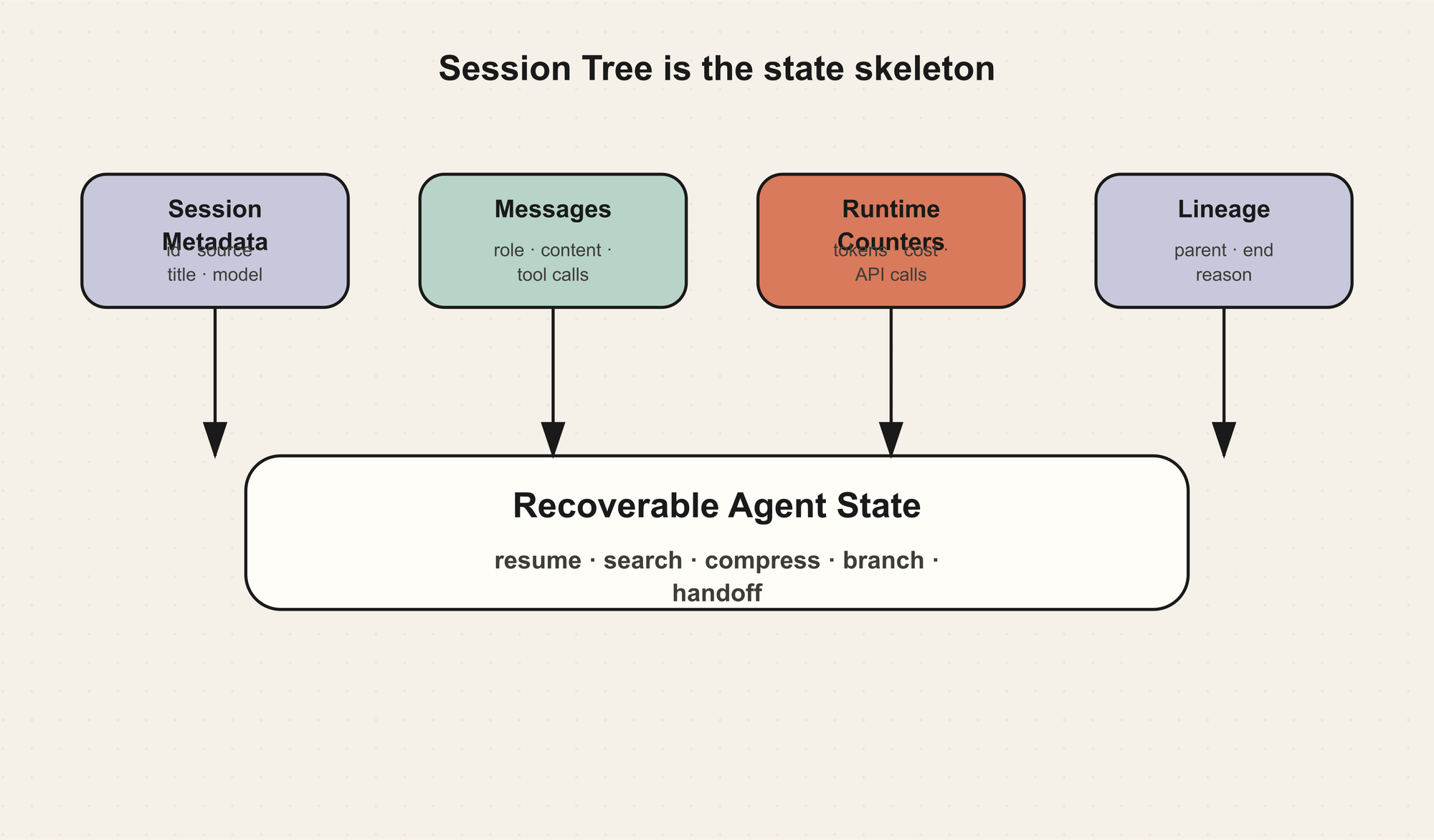
在 Hermes 里,session 不是日志文件的别名,而是 Agent 状态的持久化骨架。它把一次对话、它的消息、工具调用、标题、来源、模型配置、token 统计、父子关系和搜索索引放在同一个可查询的结构里。
读完本文,你应该能回答
- Session 为什么不只是 messages 数组?
- 树状 session 如何支持恢复、分叉、搜索和跨平台接续?
- 哪些状态应该跟随 session,哪些不应该?
- mini-agent-harness 如何设计可恢复的会话存储?
本篇在系列中的位置
前几篇讲了一次执行如何发生,本篇开始处理“执行之后留下什么”。它连接 Agent Loop 的短期消息历史和后续 Memory、Compaction、Resume 等长期能力。
贯穿案例
贯穿这个系列,可以一直带着同一个任务来读:用户说“帮我修复这个 repo 里的 failing tests”。不同章节会回答同一个任务在运行时的不同问题:入口怎样进入、上下文怎样准备、模型怎样决定下一步、工具怎样执行、状态怎样保存、失败后怎样恢复。
Session Continuity 表
同一个“修复 failing tests”任务,可能不是一次完成。Session Tree 要支持几种接续方式。
| 场景 | Session 需要保存什么 | 如果只保存 messages 会怎样 |
|---|---|---|
| 明天继续同一任务 | 历史、摘要、cwd、工具结果、标题 | 不知道任务进度和关键结论 |
| 从某一步分叉尝试新方案 | parent/child 关系、分叉点 | 新旧方案混在一起 |
| 从 Telegram 接着 CLI 的任务 | platform/session key 映射 | 找不到同一段上下文 |
| 搜索过去解决过的问题 | metadata、标题、时间、摘要 | 只能全文扫聊天记录 |
| 压缩后继续执行 | compacted state、受保护尾部 | 模型丢失最近工具调用配对 |
这就是为什么 Session Tree 是运行时结构,而不只是聊天记录归档。它决定 Agent 能否跨时间、跨入口、跨分支继续工作。
从 messages 到 session
最小 Agent 的状态通常长这样:
type Message = {
role: "system" | "user" | "assistant" | "tool"
content: string
}
type AgentState = {
messages: Message[]
}
这个结构能支持一次连续对话,但它没有回答几个生产系统必须回答的问题。
第一,谁拥有这段对话?它来自 CLI、Telegram、Discord、cron,还是 API server?不同入口的 session 隔离规则不同。
第二,它能不能恢复?如果进程退出后只剩内存里的数组,用户就无法继续任务。即使写成 JSONL,也很难高效搜索、统计和管理。
第三,它和别的 session 是什么关系?压缩后的 continuation、用户主动创建的 branch、子 Agent 执行的 delegate task,都不是孤立对话。它们有共同祖先,也可能代表同一个逻辑任务的不同阶段。
所以 Hermes 把 session 拆成两个层次:
type Session = {
id: string
source: "cli" | "telegram" | "discord" | "cron" | string
userId?: string
title?: string
model?: string
modelConfig?: Record<string, unknown>
systemPromptSnapshot?: string
parentSessionId?: string
startedAt: number
endedAt?: number
endReason?: "user_exit" | "compression" | "branched" | string
counters: TokenAndCostCounters
}
type StoredMessage = {
id: number
sessionId: string
role: "user" | "assistant" | "tool" | "system"
content?: string | MessagePart[]
toolCalls?: ToolCall[]
toolCallId?: string
toolName?: string
timestamp: number
tokenCount?: number
}
Session 描述对话本身,StoredMessage 描述对话里的事件。两者分开之后,系统才能做 resume、search、lineage、billing、prune 和 handoff。
Session Tree 的三种边
Session Tree 不是为了画图好看,而是为了区分几类完全不同的“继续”。
第一类是 resume。用户退出后再次打开同一个 session,系统读取同一个 session id 的消息,继续向后追加。这不是新节点,而是同一节点继续生长。
第二类是 compression continuation。当上下文接近窗口上限,Hermes 会压缩旧对话,创建一个新的 continuation session,并把 parent_session_id 指向旧 session。旧 session 的 end_reason 会记录为 compression。从用户视角看,这是同一个任务继续;从存储视角看,这是一个新节点,方便保留完整历史和新的活跃上下文。
第三类是 branch。用户用 /branch 创建一个独立分支时,Hermes 会复制当前对话历史,创建新 session,并把它挂到原 session 下。它和 compression 很像,都有父子关系;但语义不同:compression 是同一路径的继续,branch 是探索另一条路径。
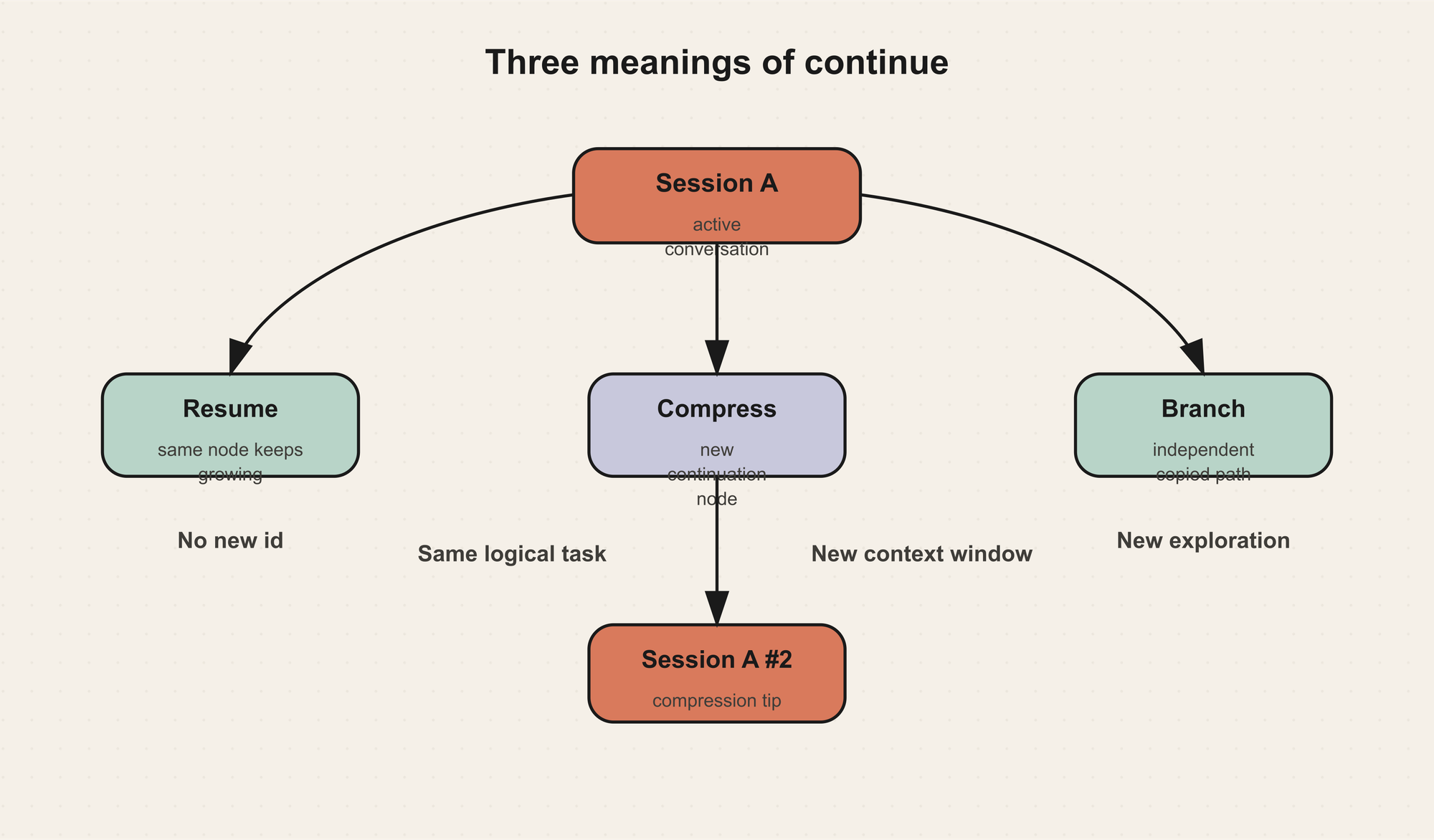
这个区分非常重要。列表页通常应该把 compression chain 投影成一个逻辑会话,否则用户会看到很多“半截对话”。但 branch 不应该被合并掉,因为它代表一个独立探索方向。子 Agent session 也不应默认出现在用户的主列表里,否则主任务会被内部执行痕迹淹没。
Hermes 的实现用 parent_session_id 表示树边,再通过 end_reason 和时间关系判断这条边的语义。比如 compression continuation 是“父 session 因 compression 结束,子 session 在父结束后创建”;branch 是“父 session 因 branched 结束,子 session 复制历史后继续”。
这比简单保存 parent_id 更稳,因为不同类型的父子关系需要不同的 UI、搜索和恢复策略。
恢复不是把日志拼回去
很多系统把 resume 理解成“读取旧 messages,然后继续 append”。这只是第一步。
真正的恢复至少要恢复四类信息。
第一是 role-aware transcript。工具调用不是普通文本。assistant.tool_calls、tool.tool_call_id、tool_name、provider 返回的 stop reason 或 reasoning metadata,都需要按 provider 能接受的格式恢复。否则模型下一轮可能无法理解上一次工具调用和工具结果之间的对应关系。
第二是 system prompt snapshot。一次会话开始时看到的系统提示、工具描述、技能注入、配置状态,可能和今天不同。Hermes 会在 session metadata 里保存 system prompt snapshot,至少让系统知道这段会话当时是在什么运行条件下创建的。
第三是 runtime counters。token、cost、API call count、cache read/write、reasoning tokens 不是文章里好看的统计数字。它们会影响 observability、成本控制、自动压缩和问题排查。
第四是 lineage context。如果当前 session 是压缩后的 continuation,恢复时可能需要沿父链读取祖先信息,或者至少把用户-facing 的列表和标题解析到最新 continuation。
一个更接近生产系统的 resume 可以这样写:
async function resumeSession(idOrTitle: string): Promise<AgentState> {
const sessionId = await store.resolveSession(idOrTitle)
const tipId = await store.projectCompressionTip(sessionId)
const session = await store.getSession(tipId)
const messages = await store.getMessagesAsConversation(tipId, {
includeAncestors: session.isContinuation
})
return {
sessionId: tipId,
title: session.title,
source: session.source,
model: session.model,
messages,
counters: session.counters,
parentSessionId: session.parentSessionId
}
}
这里的关键不是具体 API,而是边界:resume 读取的不是“一个文件”,而是一个可查询、可投影、可恢复运行语义的 session graph。
为什么 Hermes 用 SQLite
Session storage 最容易被低估。很多 demo 会先用 JSON 文件,因为写起来快。但当 Agent 进入多入口、多工具、多进程运行时,JSON 文件很快会遇到边界。
Hermes 选择 SQLite 存储 session metadata 和 messages。核心表包括:
sessions:session id、source、user、model、system prompt、title、父 session、时间、结束原因、token 和成本统计。messages:完整消息历史,包括 role、content、tool calls、tool name、tool_call_id、reasoning metadata 等。messages_fts/messages_fts_trigram:全文搜索索引,后者用于中文、日文等 CJK/substring 搜索。state_meta/schema_version:数据库元信息和迁移状态。
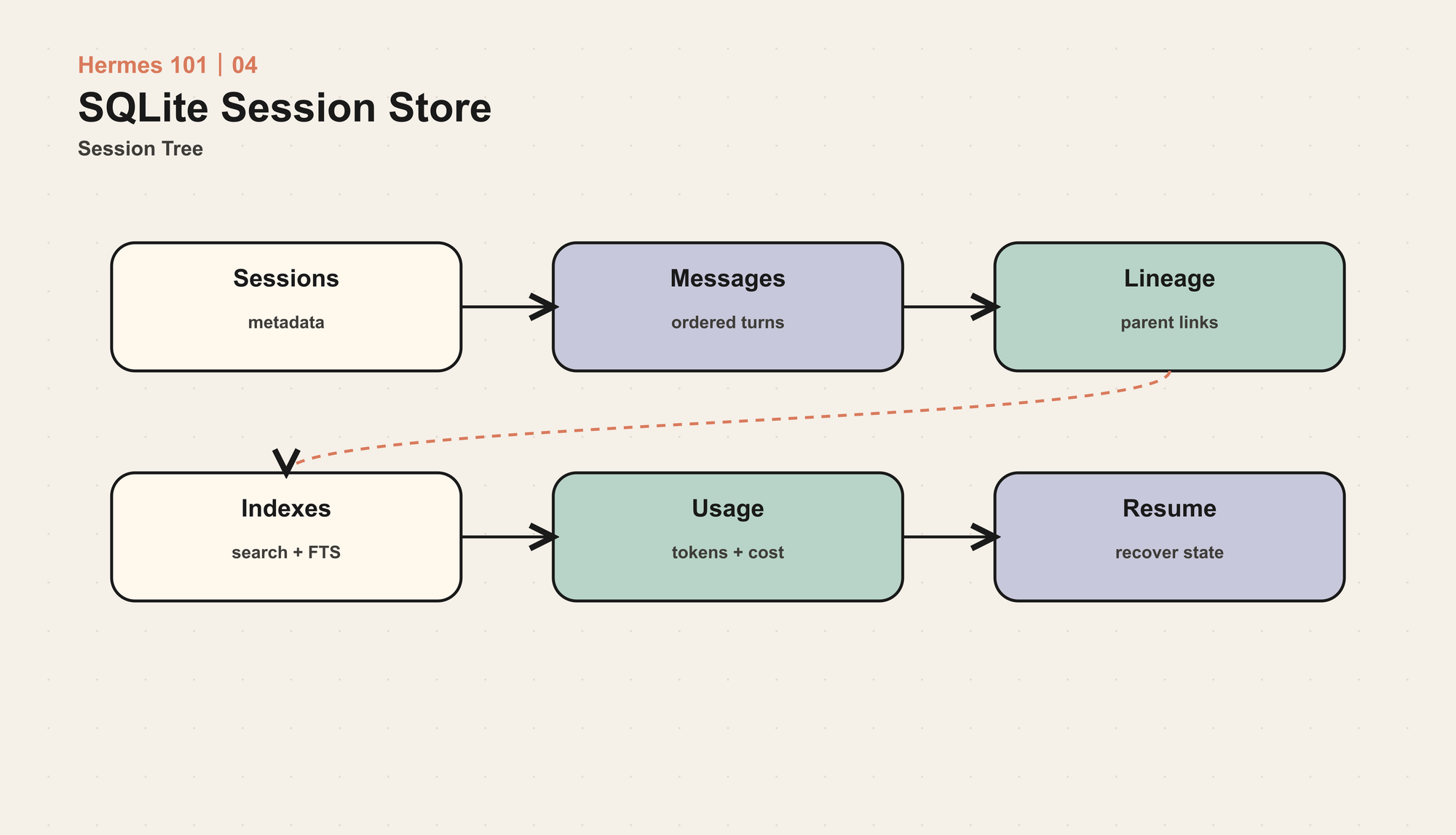
这不是为了“上数据库”而上数据库。SQLite 在这里解决的是几个具体问题。
首先是 结构化查询。列出最近 session、按来源过滤、查某个标题、找一个 lineage 的最新 continuation、统计 token 和 cost,都比扫描一堆文件可靠。
其次是 全文搜索。session_search 能跨过去的对话找相关上下文,不是靠把所有历史重新塞进 prompt,而是先用 FTS5 找到匹配消息,再按 session 聚合、截取上下文、交给模型总结。
再次是 并发。CLI、gateway、cron、子 Agent 可能同时读写同一个状态库。Hermes 使用 WAL mode,让多个 reader 和一个 writer 共存;写入时用短 SQLite timeout 加应用层随机 jitter retry,避免多个进程在同一时间重试造成 convoy effect。
最后是 迁移。Agent 状态不是一次设计完就不变。今天要加 title,明天要加 cost,后天要加 reasoning metadata 或 CJK trigram index。用 schema version 和迁移链管理这些变化,比散落的 JSON 文件更可控。
搜索是 session 的第二生命
长期 Agent 的一个核心能力是 recall。用户不会永远把上下文重新说一遍,他们会说“上次那个问题”“之前我们讨论过的方案”“你记得我们怎么配置的吗”。
这时最差的做法是把所有历史都塞进当前 prompt。它会浪费上下文窗口,也会把大量无关内容带进当前任务。
Hermes 的 session_search 走的是另一条路径:
- 用 FTS5 在
messages上搜索匹配内容。 - 按 session 聚合结果,取最相关的若干 session。
- 读取匹配附近的对话片段,而不是整库上下文。
- 用快速模型生成面向当前问题的摘要。
- 把摘要作为工具结果返回给当前 Agent。
这使得历史 session 变成可检索知识,而不是无限增长的上下文负债。
这里也能看出 Session Tree 和 Memory 的区别。Memory 保存的是长期稳定事实,比如用户偏好、环境约定、项目习惯。Session search 保存的是可回溯的工作痕迹。前者应该短、准、长期有效;后者可以大、细、可查询。
把所有历史都写进 Memory,会污染长期记忆。把所有历史都靠 session search 临时找,又可能漏掉必须持续注入的偏好。可靠 Agent 需要两者共存。
跨平台 handoff 需要同一个 session
如果 Agent 只在 CLI 里运行,session storage 只是恢复能力。可一旦 Agent 同时接入消息平台,session 就变成跨平台身份。
Hermes 的 handoff 设计是:用户可以从 CLI 把当前会话交给 Telegram、Discord、Slack 等平台。Gateway 会把目标平台的线程或话题绑定到原来的 session id,并发送一个 synthetic user turn,让 Agent 在新位置确认并总结当前状态。
这背后的关键不是“发一条消息到 Telegram”,而是 不要丢失 session identity。
如果 handoff 创建了一个全新 session,模型就只会看到一条孤立摘要,工具调用历史、标题、lineage、token/cost、未来 resume 都会断开。正确做法是让平台线程接管同一个 session,之后用户在消息平台里的回复仍然进入同一个对话轨道。
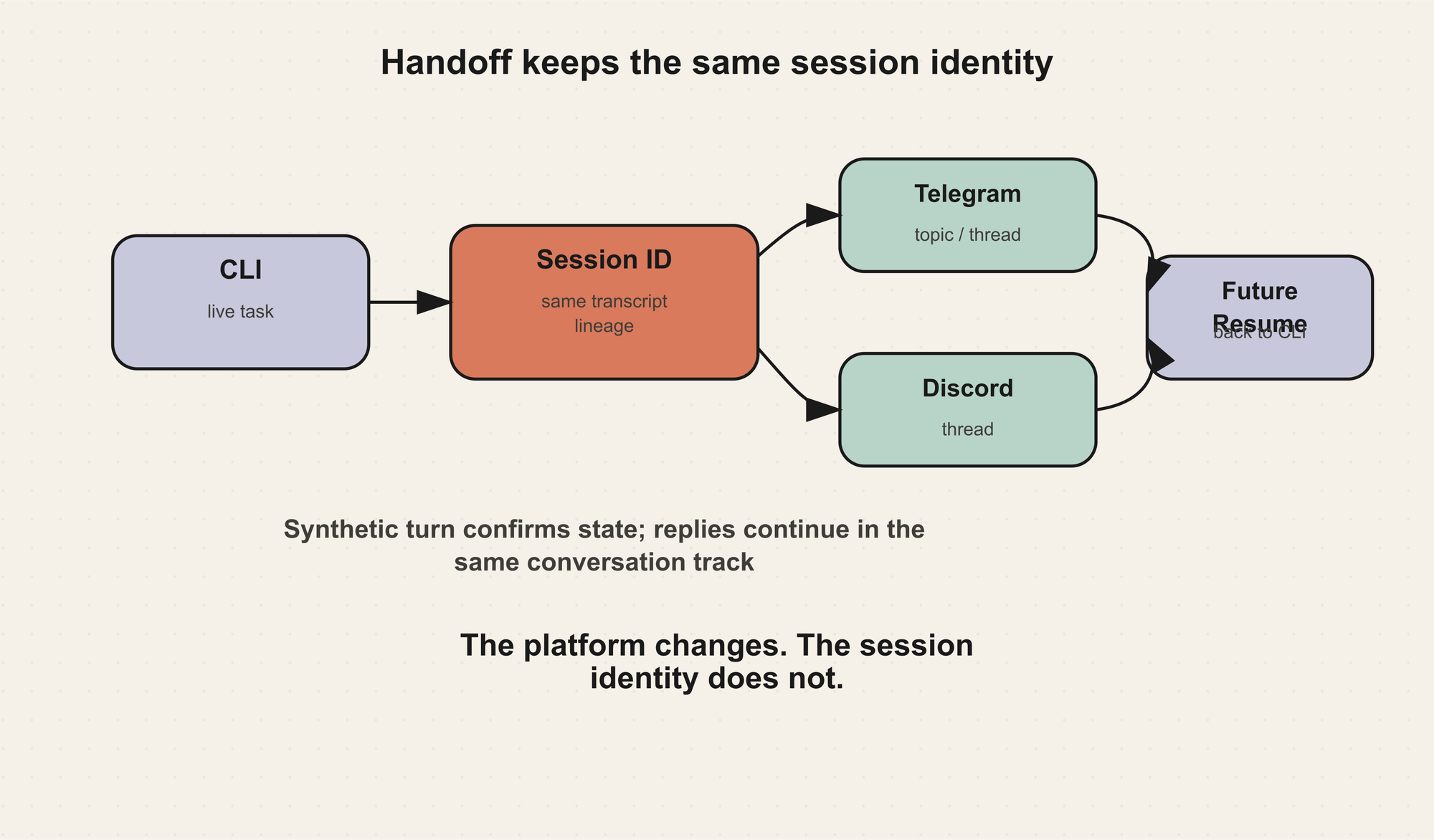
这也是为什么 messaging 平台上的 session key 设计很重要。DM、群聊、频道、论坛 topic、thread 的隔离规则不同。一个群里每个用户应不应该共享同一个上下文?一个 thread 里是不是应该多人共享?这些都不是 prompt 能解决的问题,而是 session key 和 runtime policy 的问题。
可迁移伪实现:Session Tree
下面的伪代码是机制抽象,不对应 Hermes 的真实 API 或文件结构。学习框架不需要一开始实现 Hermes 的完整数据库层,但应该从第一天就避免把状态写死成一个全局 messages[]。
一个简化版可以这样设计:
type SessionNode = {
id: string
title?: string
source: string
parentId?: string
endReason?: "compression" | "branched" | "user_exit"
startedAt: number
endedAt?: number
}
type SessionStore = {
create(input: CreateSessionInput): Promise<SessionNode>
appendMessage(sessionId: string, message: StoredMessage): Promise<void>
getMessages(sessionId: string): Promise<StoredMessage[]>
replaceMessages(sessionId: string, messages: StoredMessage[]): Promise<void>
end(sessionId: string, reason: string): Promise<void>
branch(sessionId: string, title?: string): Promise<SessionNode>
latestContinuation(sessionId: string): Promise<string>
search(query: string): Promise<SearchResult[]>
}
第一版甚至可以用 SQLite 的三张表实现:
CREATE TABLE sessions (
id TEXT PRIMARY KEY,
title TEXT,
source TEXT NOT NULL,
parent_id TEXT,
started_at REAL NOT NULL,
ended_at REAL,
end_reason TEXT
);
CREATE TABLE messages (
id INTEGER PRIMARY KEY AUTOINCREMENT,
session_id TEXT NOT NULL,
role TEXT NOT NULL,
content TEXT,
tool_calls TEXT,
tool_call_id TEXT,
tool_name TEXT,
timestamp REAL NOT NULL
);
CREATE VIRTUAL TABLE messages_fts USING fts5(content);
然后按顺序加能力:
- 先支持 create、append、resume。
- 再支持 title 和 list。
- 再支持 branch,把当前 messages 复制到新 session。
- 再支持 compression continuation,把摘要后的新上下文写入子 session。
- 再支持 FTS search。
- 最后再支持 token/cost counters、platform session key、handoff 和 prune。
这样做的好处是,学习者从一开始就会把 Agent 当成“可恢复的状态机”,而不是“一次性聊天循环”。
小结
Session Tree 是 Agent 工程里很容易被忽略的一层,因为它不像模型、工具、规划那样显眼。但它决定了 Agent 能不能长期工作。
没有 session tree,Agent 只是当前进程里的聊天数组。进程结束,状态消失;上下文变长,只能硬塞;用户要分叉,只能复制粘贴;跨平台切换,只能发摘要;历史检索,只能靠人回忆。
有了 session tree,Agent 才能把一次任务变成可恢复、可压缩、可分叉、可搜索、可跨平台接续的长期状态。
Hermes 的实现给出的核心启发是:session 不是日志,而是运行时状态结构。它连接 Agent Loop、Tool Runtime、Context Compression、Memory、Gateway 和 Observability。理解这一层,才真正理解一个长期运行的 Agent 为什么不是一个 while loop 加一个 messages 数组。
参考资料
- Hermes Agent README: https://github.com/NousResearch/hermes-agent
- Hermes Agent Sessions: https://hermes-agent.nousresearch.com/docs/user-guide/sessions
- Hermes Agent Session Storage: https://hermes-agent.nousresearch.com/docs/developer-guide/session-storage
- Hermes Agent Agent Loop Internals: https://hermes-agent.nousresearch.com/docs/developer-guide/agent-loop
- SQLite Write-Ahead Logging: https://www.sqlite.org/wal.html
- SQLite FTS5 Extension: https://www.sqlite.org/fts5.html