很多 Agent 失败并不是因为模型能力不够,而是因为模型看到的上下文不对。
它可能缺少项目约定,所以写出了不符合仓库风格的代码;也可能被过多历史消息淹没,在旧结论和新任务之间摇摆;还可能看到了一个当前不可用的工具,于是计划从第一步就偏离现实。
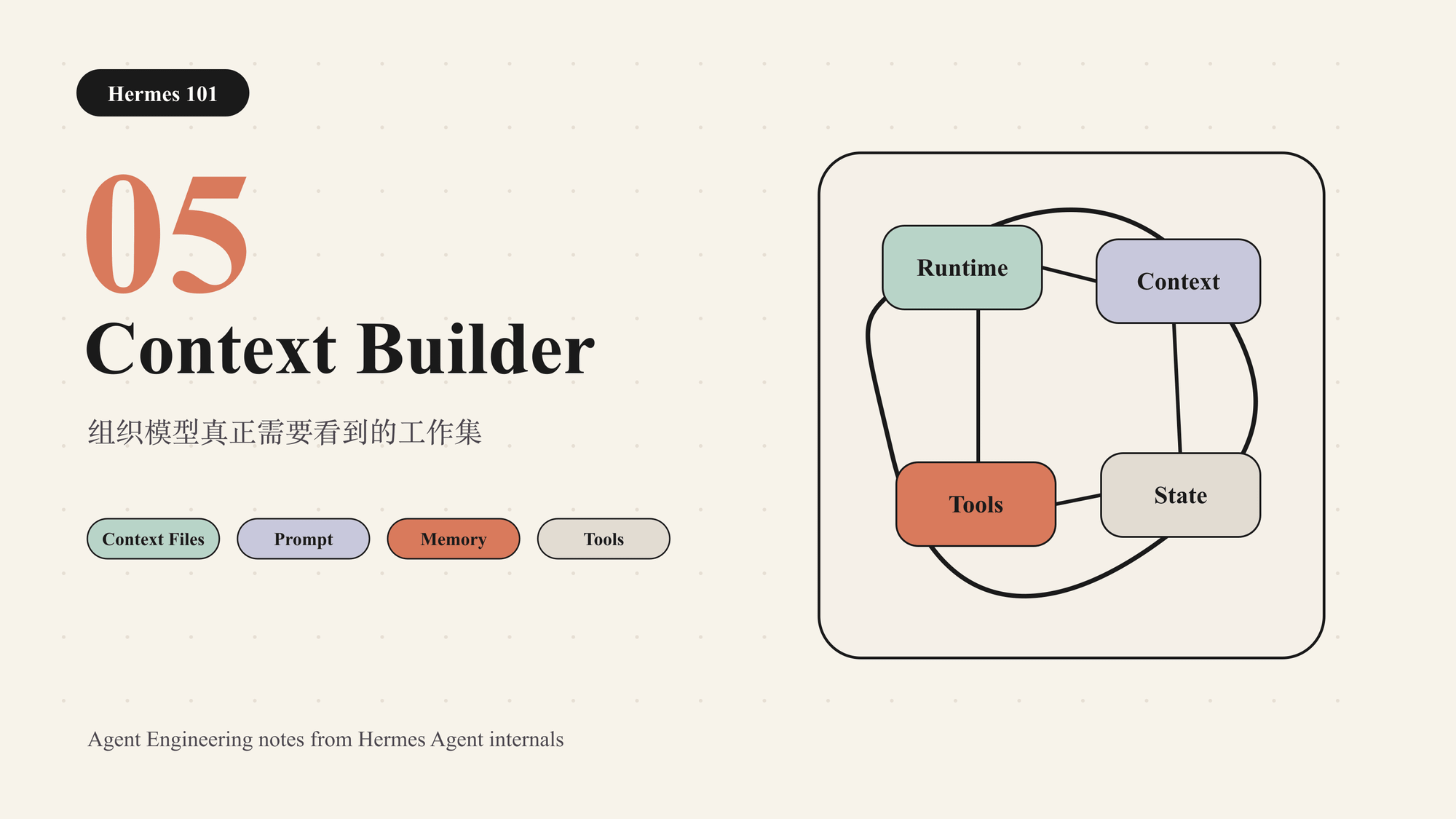
这就是 Context Builder 的位置。它不是简单把所有材料拼成 prompt,而是在每轮模型调用之前,把身份、规则、会话状态、任务输入、工具能力和外部记忆组织成一个可执行的工作集。
读完本文,你应该能回答
- 上下文为什么不是越多越好?
- Context Builder 如何决定模型这一轮能看到什么?
- 系统规则、项目规则、技能、记忆和工具 schema 应该怎样排序?
- 如何避免旧历史、无关规则或不可用工具污染当前任务?
本篇在系列中的位置
前面已经有 loop、tools 和 session,本篇回答模型调用前的关键问题:这一轮到底把什么交给模型。下一篇会继续看当上下文太长时,Hermes 如何压缩而不是简单丢弃历史。
贯穿案例
贯穿这个系列,可以一直带着同一个任务来读:用户说“帮我修复这个 repo 里的 failing tests”。不同章节会回答同一个任务在运行时的不同问题:入口怎样进入、上下文怎样准备、模型怎样决定下一步、工具怎样执行、状态怎样保存、失败后怎样恢复。
定义
Context Builder 是 Agent Runtime 中负责构造模型输入的层。它决定哪些信息进入上下文、以什么格式进入、在什么时机进入,以及哪些信息必须留在模型视野之外。
最小 Agent 里,context builder 往往只是一段数组拼接:
const request = [
{ role: "system", content: systemPrompt },
...history,
{ role: "user", content: userInput }
]
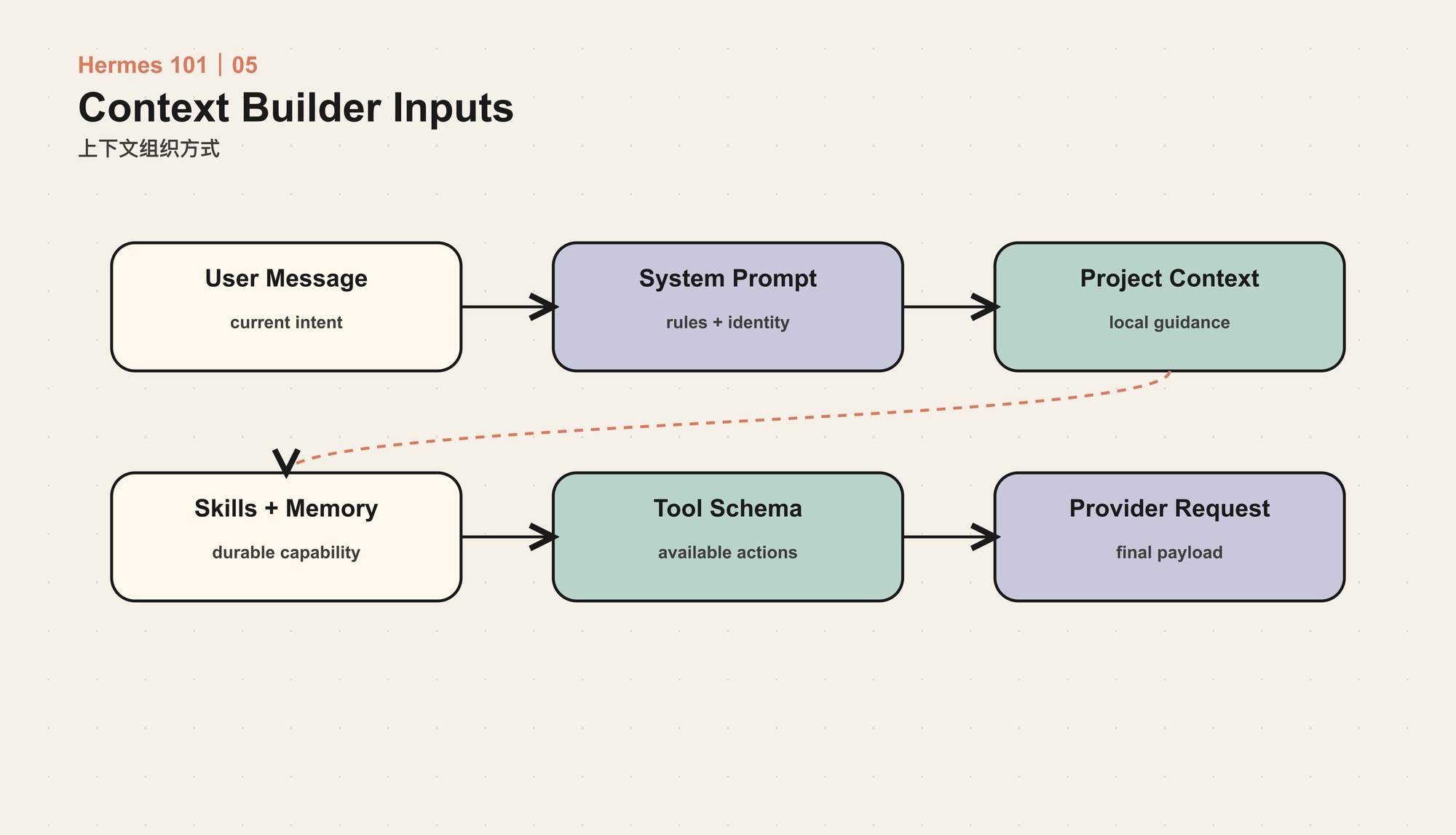
这个实现能跑 demo,但不能支持长期任务。真实 Agent 的输入来自多个来源:系统身份、用户偏好、项目规则、技能说明、工具 schema、会话历史、压缩摘要、检索结果、平台元数据和当前工作目录。Context Builder 的核心价值,是让这些来源形成稳定的层次,而不是互相覆盖。
Hermes 的上下文来源
Hermes 的上下文构造可以分成几类。
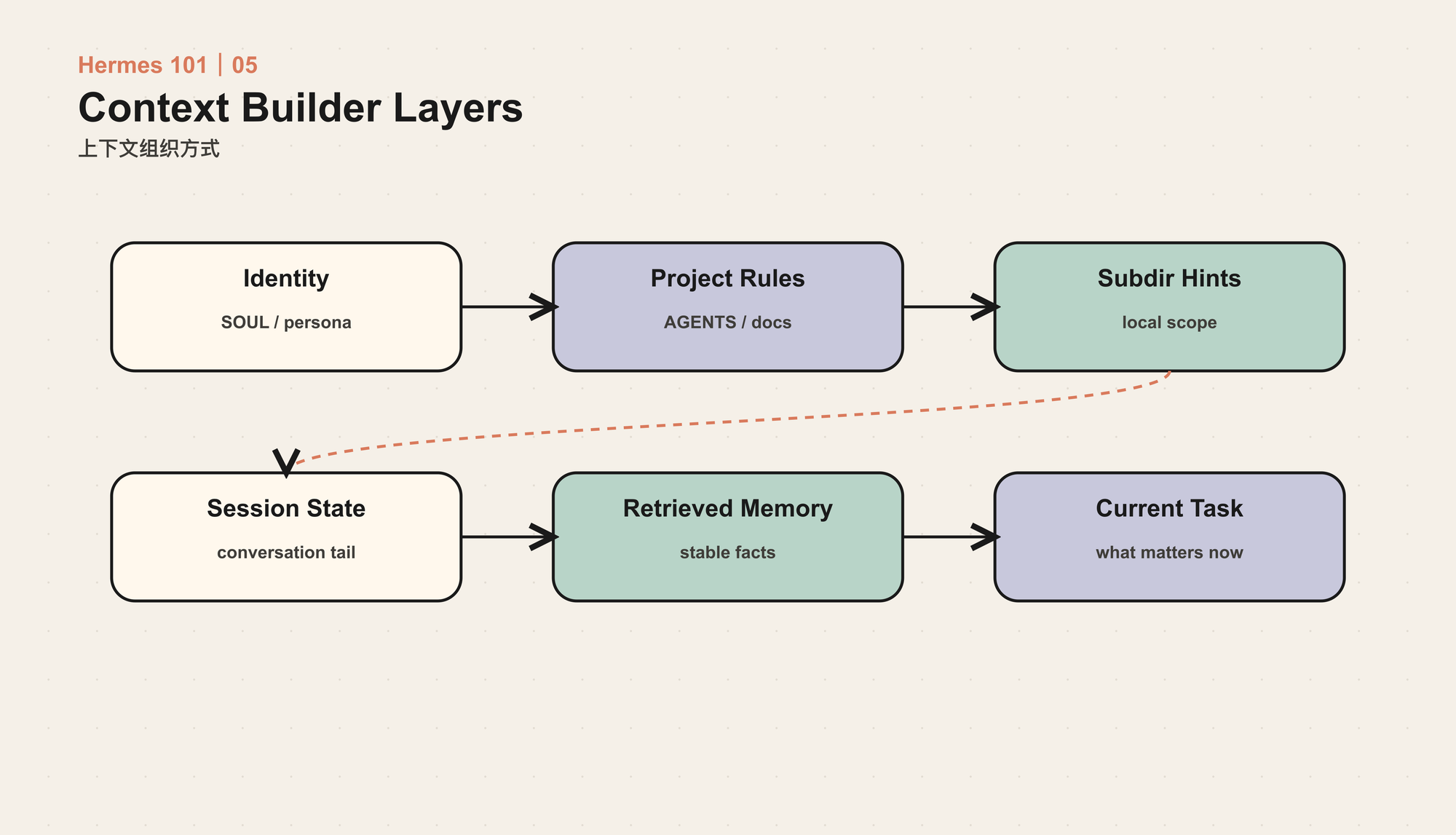
第一类是 稳定身份层。例如全局 personality、工具使用规则、安全约束、执行纪律。这些内容通常进入 system prompt,并且需要保持稳定,因为频繁改变 system prompt 会破坏 prompt caching,也会让同一个 session 的行为难以解释。
第二类是 项目上下文层。Hermes 会从工作目录发现项目级 Hermes 配置文件、AGENTS.md、CLAUDE.md、编辑器规则文件等上下文入口。启动时加载根目录上下文;当工具访问子目录时,再按需发现子目录里的 AGENTS.md 或 CLAUDE.md。这是一种渐进式上下文注入:不把整个仓库规则一次塞进 prompt,而是在路径真正相关时才进入模型视野。
第三类是 能力层。工具 schema、skills 索引、MCP 工具、插件暴露的能力,都会影响模型计划。Context Builder 必须只暴露当前可用的能力,否则模型会把不可执行的动作当成计划基础。
第四类是 会话层。当前消息、历史对话、工具结果、压缩摘要、session metadata、token 统计,决定模型如何接续任务。这里的难点不是“保留越多越好”,而是既要保留决策依据,又要避免旧信息拖累当前任务。
Context 冲突矩阵
读这一篇时,最容易混淆的是:不同来源的上下文都像“提示词”,但它们的优先级和风险完全不同。可以用下面这张表判断冲突时应该保留谁、压低谁。
| 冲突场景 | 应该优先相信 | 应该压低或隔离 | 原因 |
|---|---|---|---|
| 用户当前请求 vs 旧会话摘要 | 用户当前请求 | 旧摘要 | 当前 turn 是最新意图,旧摘要只提供背景 |
| 项目规则 vs 通用编码习惯 | 项目规则 | 通用习惯 | Agent 应该服从当前 repo 的约定 |
| Tool result vs 模型猜测 | Tool result | 猜测 | 工具结果是可观察事实 |
| Skill 流程 vs 当前错误信息 | 当前错误信息 | Skill 中过时步骤 | Skill 是经验,不是不可变规则 |
| 可用工具列表 vs 记忆里的旧工具 | 当前工具列表 | 旧记忆 | 模型只能调用本轮真实暴露的工具 |
这张表的意义不是让 Context Builder 做“文本排序”,而是让它在进入模型前先完成一次语义分层:哪些是硬约束,哪些是背景,哪些只是候选建议。
组装顺序比内容更多
Context Builder 的一个常见误区,是只关注“放什么”,不关注“放在哪里”。
对模型来说,顺序和边界会改变语义。系统规则、项目规则、用户当前请求、工具结果、历史摘要如果混在同一段文本里,模型很难判断哪条信息优先级更高。Hermes 的设计倾向于把不同来源放在清晰的段落中,并让关键约束出现在稳定位置。
可迁移伪实现:Context Builder
下面的伪代码是机制抽象,不对应 Hermes 的真实 API 或文件结构。
一个工程化的 Context Builder 可以抽象成这样:
type ContextSource =
| { kind: "identity"; priority: 100; content: string }
| { kind: "project"; priority: 80; content: string }
| { kind: "skill"; priority: 70; content: string }
| { kind: "memory"; priority: 60; content: string }
| { kind: "session"; priority: 50; messages: Message[] }
| { kind: "tool_schema"; priority: 40; tools: ToolSchema[] }
async function buildProviderRequest(input: UserInput): Promise<ModelRequest> {
const sources = await collectContextSources(input)
const scanned = sources.filter(passPromptInjectionScan)
const bounded = applyTokenBudgets(scanned)
return {
system: renderSystemSections(bounded),
messages: renderConversation(input.session, bounded),
tools: renderAvailableToolSchemas(bounded)
}
}
这里有三个边界很关键。
首先,Context Builder 不应该信任所有文本。项目上下文文件可能来自外部仓库,网页内容可能包含 prompt injection,工具结果也可能把恶意指令带回上下文。进入 prompt 之前要做扫描、截断和标注。
其次,Context Builder 不应该破坏消息角色结构。工具调用和工具结果有 provider 规定的对应关系,不能为了压缩或拼接方便把它们变成普通段落。
最后,Context Builder 不应该把“长期记忆”和“当前工作集”混为一谈。记忆是可检索资产;工作集是本轮模型真正需要看的内容。把所有记忆常驻 prompt,会把个性化变成上下文污染。
渐进式发现
Hermes 的子目录上下文发现体现了一个重要原则:上下文应当跟随行动路径,而不是跟随仓库体积。
当 Agent 读取 backend/src/main.py 时,系统会检查相关目录上是否存在 AGENTS.md 或 CLAUDE.md,并把发现的规则随工具结果注入给模型。这样做有两个收益。
第一,系统 prompt 保持相对稳定,有利于缓存和可预测性。第二,模型只在接触某个区域时看到该区域规则,减少无关约束干扰。
这类设计也解释了为什么 Context Builder 不是一个纯字符串函数。它需要知道工具调用路径、当前工作目录、session 来源、平台、模型上下文长度和可用工具集合。
产品边界
Context Builder 决定 Agent 的“注意力界面”。如果它过于保守,模型缺少必要材料;如果它过于贪婪,模型会被噪声拖慢,并且成本上升。
好的 Context Builder 不是追求最大上下文,而是追求 最小充分上下文:让模型看到完成当前任务需要的事实、规则、工具和状态,同时保留边界、来源和优先级。
小结
Hermes 的 Context Builder 说明了一件事:Agent 的智能不只来自模型,也来自模型调用前的输入组织。上下文工程的核心不是“塞更多资料”,而是持续回答一个工程问题:这轮行动,模型到底需要看到什么。