长上下文窗口让 Agent 能做更久的任务,但它没有消除上下文管理问题。只要任务足够长,工具输出、文件内容、网页摘录、调试日志和多轮计划都会不断堆积。最终,模型面对的不再是清晰任务,而是一大段混杂历史。
Context Compaction 解决的不是“怎样省 token”这么简单。它要把已经发生过的过程压缩成一种仍然可执行、可恢复、可审计的状态。
读完本文,你应该能回答
- 压缩和摘要有什么不同?
- 为什么最近消息与 tool_call/tool_result 配对必须被保护?
- 压缩应该保留哪些决策依据,丢弃哪些噪声?
- mini-agent-harness 怎样实现可继续执行的压缩状态?
本篇在系列中的位置
上一篇讲“如何构造上下文”,本篇讲“上下文装不下时怎么办”。它为后面的 Memory 和 Session Resume 打基础:长期任务不能只靠更大的窗口。
贯穿案例
贯穿这个系列,可以一直带着同一个任务来读:用户说“帮我修复这个 repo 里的 failing tests”。不同章节会回答同一个任务在运行时的不同问题:入口怎样进入、上下文怎样准备、模型怎样决定下一步、工具怎样执行、状态怎样保存、失败后怎样恢复。
定义
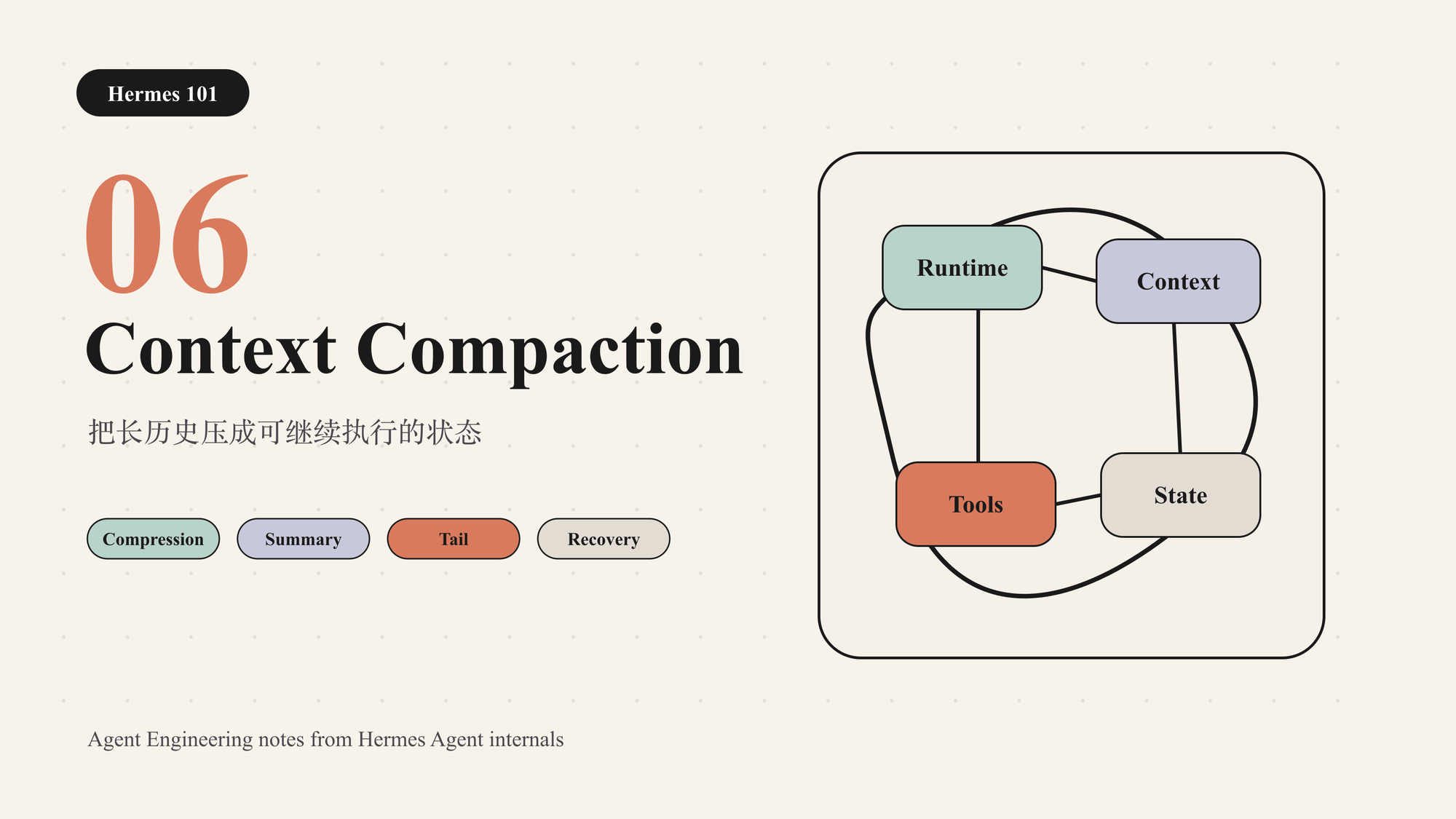
Context Compaction 是在长会话中重写模型工作集的机制:保留当前任务需要的结论、约束、文件、错误和下一步,同时把不再需要逐字保留的中间过程移出活跃上下文。
最危险的做法是把 compaction 理解成普通摘要。普通摘要追求“概括”;Agent compaction 追求“接着干”。两者的评价标准不同。
一个好的 compaction 结果必须回答:
- 用户目标是什么;
- 已经完成了什么;
- 当前卡在哪里;
- 哪些文件、命令、URL、错误消息仍然重要;
- 哪些决策已经确定,不能下一轮又重新讨论;
- 下一步应该从哪里继续。
Hermes 的双层压缩
Hermes 有两层压缩机制。
第一层是 gateway session hygiene。它运行在 Agent 处理消息之前,是防止 Telegram、Discord 等长时间积累的 gateway session 把模型请求直接撑爆的安全网。它的阈值更高,目的是兜底,而不是频繁介入。
第二层是 Agent 内部的 ContextCompressor。它运行在 Agent Loop 中,能看到更准确的 token 使用情况,也能按照当前模型上下文长度计算预算。默认情况下,它在上下文达到一定比例时触发,是日常长任务管理的主机制。
这个区分很重要。Gateway 层不知道本轮工具调用之后会发生什么,它只能防止请求失败。Agent 层知道当前对话结构、工具调用组和 token 计数,才能做更细的压缩。
压缩时应该保留什么
压缩失败通常不是因为摘要写得短,而是因为保留错了东西。一个可继续执行的 compaction 至少要区分下面几类信息。
| 信息类型 | 是否保留 | 处理方式 | 例子 |
|---|---|---|---|
| 当前目标 | 必须保留 | 用一句话明确任务状态 | “修复 repo 中 failing tests” |
| 已验证事实 | 必须保留 | 保留命令、结果和结论 | “pytest A 失败,因为缺少 env mock” |
| 未验证猜测 | 谨慎保留 | 标记为假设 | “可能是路径解析问题” |
| tool_call / tool_result 配对 | 必须保护 | 不拆散最近配对 | assistant 调用 terminal 后紧跟结果 |
| 长日志 | 通常裁剪 | 只保留错误栈和关键行 | 5000 行测试日志压成 20 行 |
| 已废弃计划 | 通常丢弃 | 只在失败复盘中提及 | “尝试方案 A,已证伪” |
所以 compaction 更像“状态重写”,不是“聊天摘要”。它要让下一轮模型知道:现在在哪里、已经试过什么、哪些证据可靠、下一步最合理。
四个阶段
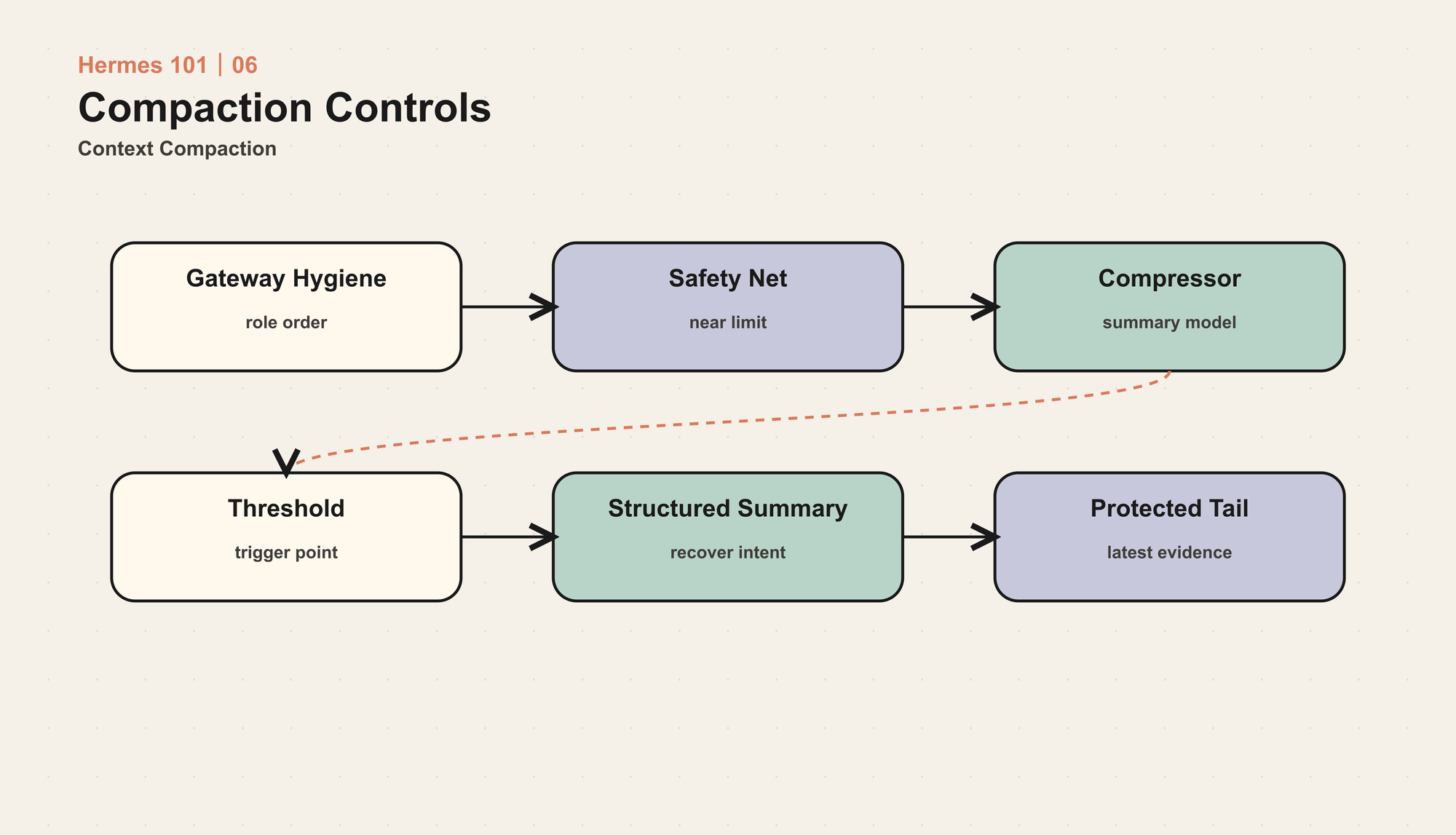
Hermes 的内置压缩器可以理解为四个阶段。
第一阶段是清理旧工具输出。长工具结果通常是 token 最大来源,尤其是文件全文、构建日志、网页内容和搜索结果。对已经远离当前尾部的旧工具结果,Hermes 会先做廉价清理,把冗长内容替换成占位说明。这样不需要调用摘要模型,就能回收大量空间。
第二阶段是确定边界。不是所有历史都适合压缩。系统开头、最早的任务定义、最近的若干轮对话和工具调用尾部都需要保护。Hermes 会保留 head 和 tail,中间段才进入摘要。边界还要避免切断 tool call 与 tool result 的对应关系,否则 provider 消息结构会被破坏。
第三阶段是生成结构化摘要。摘要不是一段自然语言回顾,而是带有目标、约束、进展、关键决策、相关文件、下一步和关键上下文的工作状态。
第四阶段是重新组装消息列表。系统提示、摘要消息、受保护尾部被拼回一个合法的 OpenAI-format message 序列;孤立的工具调用或工具结果会被清理或补齐,避免下一轮模型调用失败。
可迁移伪实现:Context Compaction
下面的伪代码是机制抽象,不对应 Hermes 的真实 API 或文件结构。
async function compact(messages: Message[]): Promise<Message[]> {
const pruned = pruneOldToolResults(messages)
const { head, middle, tail } = chooseBoundaries(pruned, {
protectFirst: 3,
protectLast: 20,
tailBudget: "token-based"
})
const summary = await summarizeForContinuation(middle, {
previousSummary: state.previousSummary,
template: "goal / constraints / progress / files / next steps"
})
return sanitizeToolPairs([
...head,
asContinuationMessage(summary),
...tail
])
}
为什么尾部必须保留
很多 compaction 方案会试图把所有历史都压成一段摘要。但 Agent 任务里,最近尾部通常包含未完成动作的细节:刚刚运行的命令、最新错误、用户刚纠正的偏好、即将编辑的文件片段、工具返回的结构化 ID。
这些信息如果只靠摘要模型转述,风险很高。Hermes 因此用 token 预算和消息数量双重保护 tail:既按 token 从后往前累计,也保证至少保留一定数量的近期消息。
这体现了一个工程判断:摘要适合保存稳定结论,不适合保存刚发生的操作现场。
多次压缩的问题
长任务可能经历多次压缩。如果每次都只总结当前中间段,早期重要事实会逐渐消失。Hermes 会保存上一轮摘要,并要求摘要模型更新它,而不是从零开始。
这让 compaction 更接近状态转移:旧任务从 In Progress 移到 Done,新决策加入 Key Decisions,过时信息被删掉。它不是无限叠加摘要,而是维护一个可继续执行的任务状态。
失败边界
Compaction 最大的风险是静默丢失上下文。一个常见坑是摘要模型的上下文窗口比主模型小,导致中间段发不过去。如果系统没有显式处理,压缩可能在失败后直接丢弃历史。
因此生产系统需要把 compaction 当成可靠性组件,而不是优化项:要有阈值、预算、日志、失败回退、结构化模板和可验证的恢复效果。
小结
Context Compaction 的目标不是让聊天记录变短,而是让 Agent 在长任务中保持行动连续性。Hermes 的实现提醒我们:长上下文不是免费的,真正重要的是把历史转换成可执行状态,并让当前尾部保持清晰。