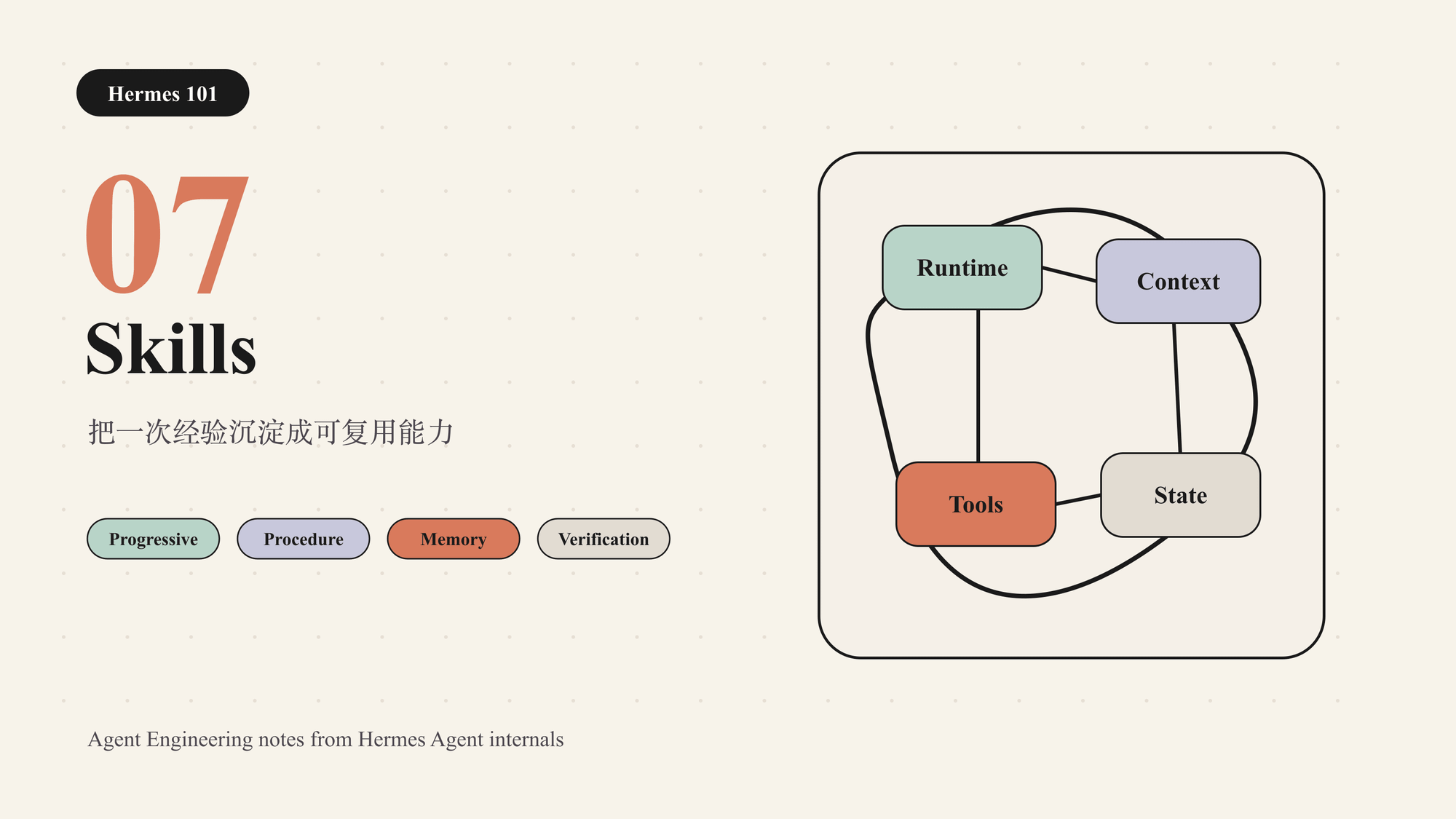
Agent 做得越久,越容易遇到同一种问题反复出现:某个 API 有固定认证方式,某类发布流程有固定校验步骤,某个项目有稳定约定,某种错误有已知坑点。
如果这些经验只留在一次会话里,下一次还要重新探索。长期记忆可以记住事实,但它不适合保存完整流程。Hermes 用 Skills 来承载这类可复用程序性知识。
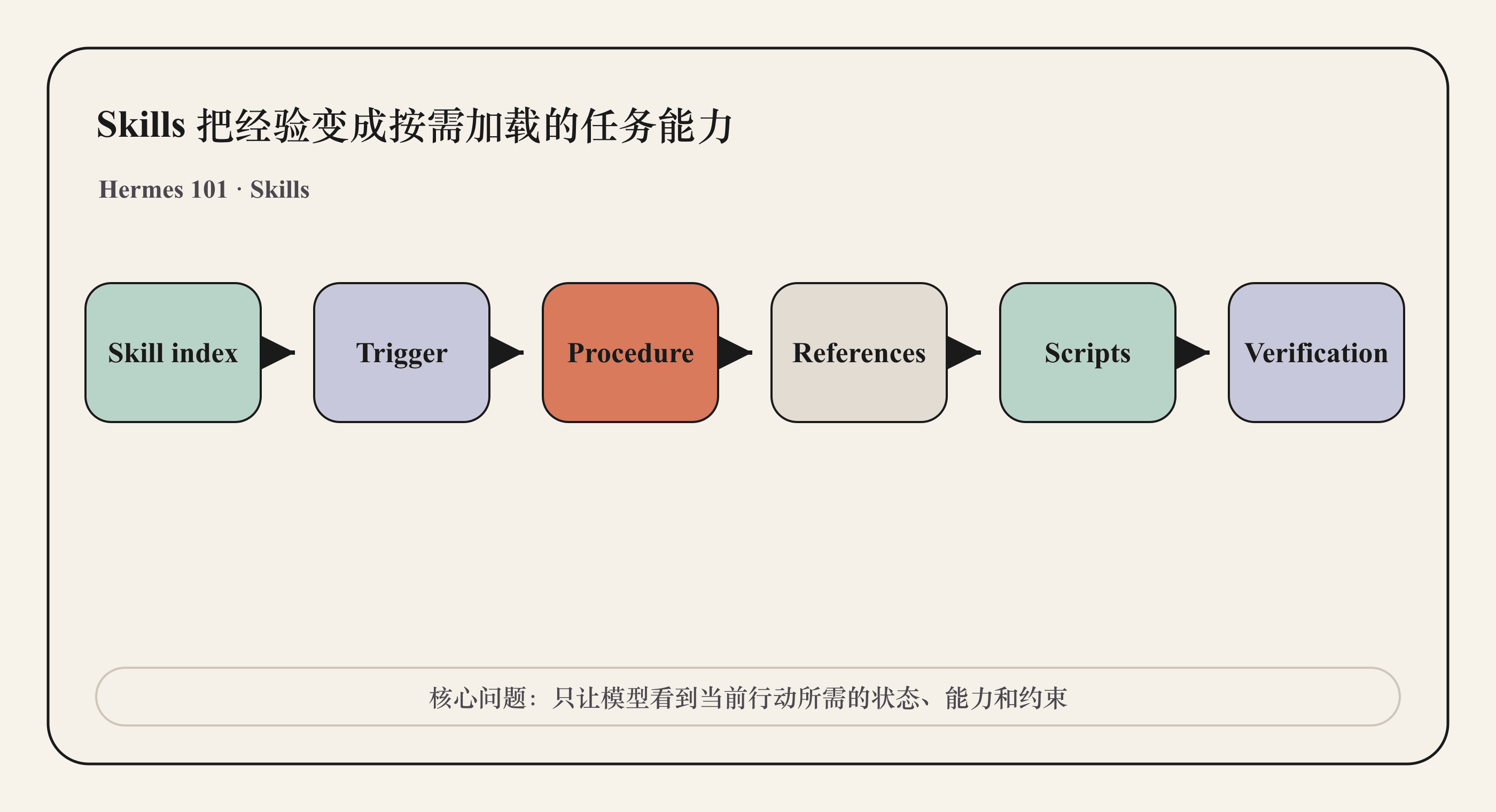
读完本文,你应该能回答
- Skill 和 Memory、工具、普通文档有什么区别?
- 什么时候应该加载一个 Skill,而不是把所有知识都放进 prompt?
- 一个好 Skill 应该包含哪些步骤、坑点和验证方法?
- mini-agent-harness 如何把经验沉淀成可复用流程?
本篇在系列中的位置
前面讲的是一次任务如何被执行和压缩,本篇进入“经验复用”。Skill 是 Agent 从一次性执行走向稳定工作流的关键层,后面的 Extensions 会继续扩大这种能力边界。
贯穿案例
贯穿这个系列,可以一直带着同一个任务来读:用户说“帮我修复这个 repo 里的 failing tests”。不同章节会回答同一个任务在运行时的不同问题:入口怎样进入、上下文怎样准备、模型怎样决定下一步、工具怎样执行、状态怎样保存、失败后怎样恢复。
定义
Skill 是一种可按需加载的任务能力包。它通常包含适用场景、操作步骤、命令、坑点、验证方法,以及必要的参考文件、模板或脚本。
它和普通文档的区别在于:skill 是给 Agent 执行任务时使用的,而不是给人阅读存档。好的 skill 不只是解释概念,而是减少下一次执行时的探索成本。
例如,发布 Ghost 文章不是“知道 Ghost API 存在”就够了。Agent 需要知道:应该用 Admin API 不是 Content API;状态默认 draft,用户明确说发布才 publish;正文 SVG 要转 PNG;excerpt 要映射到 custom_excerpt;发布后要验证公开页没有本地路径泄露。把这些规则写成 skill,下一次就不会重犯同样错误。
Skills 不是长期记忆
长期记忆适合保存稳定事实:用户偏好、项目位置、常用账户、长期约定。Skill 适合保存流程:什么时候用、怎么做、怎么验证、哪里容易错。
这个区分很重要。如果把流程塞进 memory,系统 prompt 会越来越重,而且下一次任务不一定相关。相反,skill 可以保持在索引里,只有任务匹配时才加载。
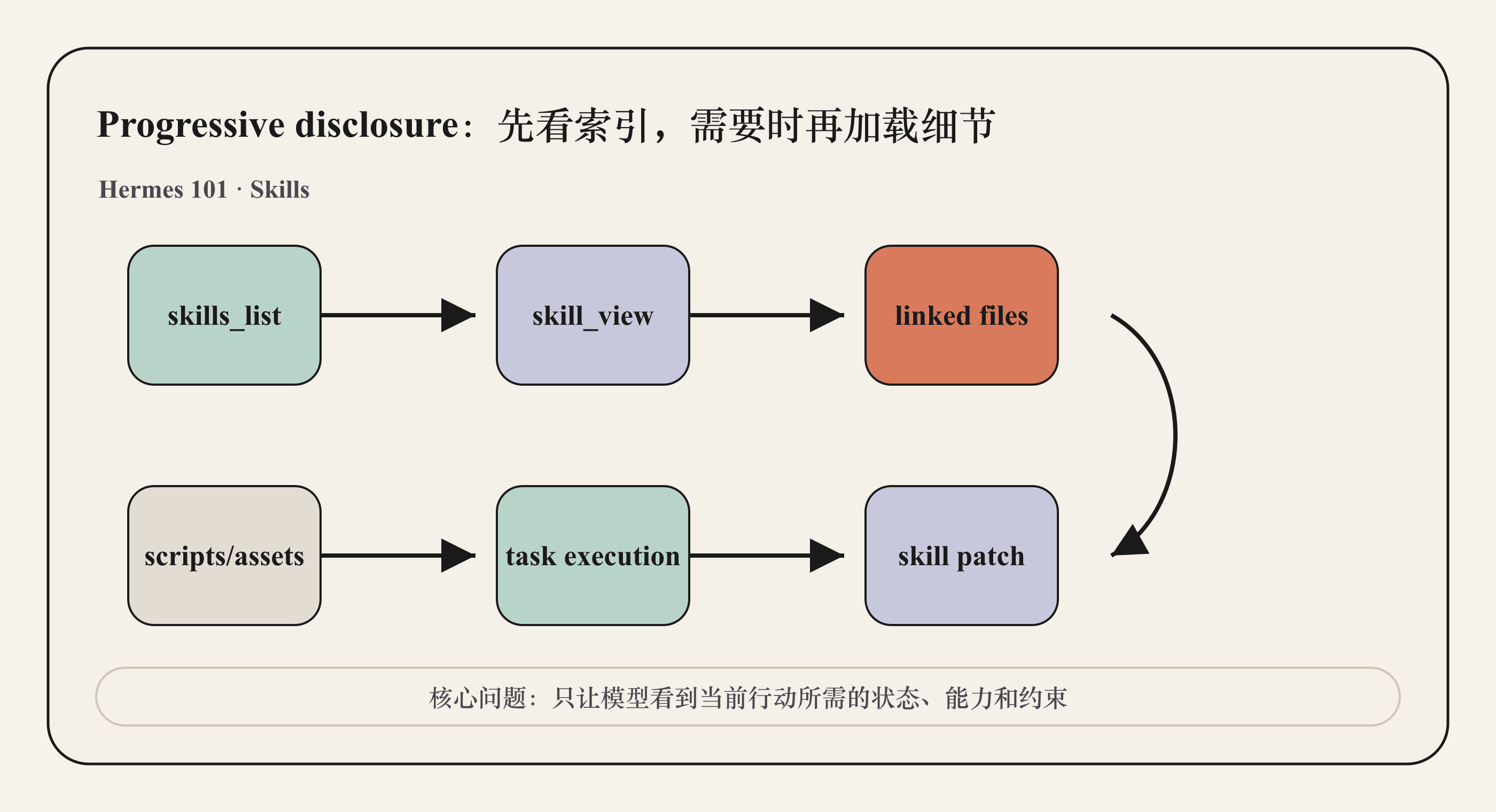
Hermes 的 skill 系统使用渐进式披露:
可迁移伪实现:Skill Index
下面的伪代码是机制抽象,不对应 Hermes 的真实 API 或文件结构。
type SkillIndexItem = {
name: string
description: string
category?: string
}
type Skill = {
frontmatter: SkillMetadata
instructions: string
linkedFiles?: {
references?: string[]
templates?: string[]
scripts?: string[]
assets?: string[]
}
}
模型先看到技能索引;需要时调用 skill_view(name) 加载完整内容;如果完整 skill 又链接了参考文件,再按路径加载具体文件。这样既能让大量技能可发现,又不会把所有流程常驻上下文。
Skill / Memory / Tool 的边界
Skill 很容易和 Memory、Tool 混在一起。可以用这张表区分。
| 层 | 保存什么 | 什么时候用 | 不应该保存什么 |
|---|---|---|---|
| Memory | 长期仍然重要的事实 | 识别用户偏好、项目约定、环境事实 | 临时任务进度、完整操作流程 |
| Skill | 可复用流程和坑点 | 遇到同类任务时按需加载 | 用户隐私、一次性执行日志 |
| Tool | 可执行能力 | 需要读写文件、搜索、发布、运行命令时 | 长篇经验解释 |
| Session | 当前任务上下文 | 继续同一段工作时 | 跨项目永久规则 |
以“修复 failing tests”为例:用户偏好“先写测试再改代码”属于 Memory;“这个项目如何跑测试、常见失败如何排查”属于 Skill;真正执行 pytest 属于 Tool;这次具体失败栈属于 Session。
一个好 Skill 的结构
Hermes 的 SKILL.md 通常包含几个部分。
第一是元数据。name 和 description 决定它怎样被发现;platforms 可以限制只在 macOS、Linux 或 Windows 出现;required_environment_variables 可以在加载时提示缺少的密钥;Hermes metadata 可以声明分类、标签、工具依赖或 fallback 关系。
第二是触发条件。Agent 需要知道什么时候加载这个 skill,而不是只在用户明确说出 skill 名时才使用。
第三是步骤。步骤应该足够具体,最好包含命令、路径、API 字段和顺序。含糊的“检查配置然后发布”帮助不大;“读取 slug、上传 PNG、用 custom_excerpt、再验证公开 HTML”才是可执行知识。
第四是坑点和验证。Skill 的价值往往来自失败经验。一个流程真正可复用,必须知道怎么确认成功,以及哪些“看起来成功”的状态其实还没完成。
---
name: ghost-publishing
description: Publish or verify posts on Ghost
---
## When to Use
- User asks to publish, update, or verify a Ghost post.
## Procedure
1. Load credentials from env.
2. Convert Markdown to HTML.
3. Upload local images first.
4. Upsert by slug via Admin API.
## Pitfalls
- Use custom_excerpt, not excerpt.
- Do not leave SVG body image URLs.
## Verification
- Fetch public URL.
- Confirm HTTP 200 and no local path leakage.
Agent 自我改进
Skills 让 Hermes 具备一种轻量的自我改进能力。
当 Agent 解决了一个复杂问题,或者用户纠正了一个流程,它可以把新经验保存成 skill。下一次遇到相似任务时,系统不用重新从通用知识出发,而是加载已经验证过的本地流程。
这不是模型训练,也不是微调。它更像一种 操作层知识库:低成本、可审阅、可修改、能被版本化,也能随用户环境变化而更新。
Hermes 还允许 skill 带引用文件、模板、脚本和资产。对于复杂流程,主 SKILL.md 可以保持简洁,把 API 细节、示例模板或辅助脚本放到 linked files 里。这样模型不会一开始就吃掉全部 token。
治理边界
Skills 强大,也需要边界。
第一,skill 不应该保存密钥。它可以声明需要哪些环境变量,但不应该把真实 token 写进文件。
第二,skill 不应该变成临时任务日志。一次任务完成了什么、当前进度在哪里,属于 session;稳定可复用流程才属于 skill。
第三,skill 需要维护。过期的命令、旧 API 字段、错误的路径,会让 Agent 更自信地犯错。因此 Hermes 把 skill 管理也做成工具:可以创建、补丁、编辑、删除,并在使用中发现问题时立刻修正。
小结
Skills 是 Hermes 中最重要的经验层。它把“这次怎么做成的”转化为“下次如何更可靠地做”。对 Agent Engineering 来说,这是一种比长期记忆更可控、比模型微调更便宜、比普通文档更贴近执行的能力沉淀方式。