
很多人认真使用 Claude Code 或 Codex,不是先研究 API 价格表,而是先从订阅开始。
无论是几十美元还是几百美元的档位,看起来都是在买一个更聪明的 coding agent。但用久一点,很快就会遇到几个朴素的问题:
为什么一个长任务跑着跑着,额度消耗得这么快?
为什么只是继续上一轮上下文,首 token 还是要等?
为什么同样是让 agent 改代码,短任务很轻,长任务却越来越贵、越来越慢?
答案不只在模型价格里,也在上下文的处理方式里。
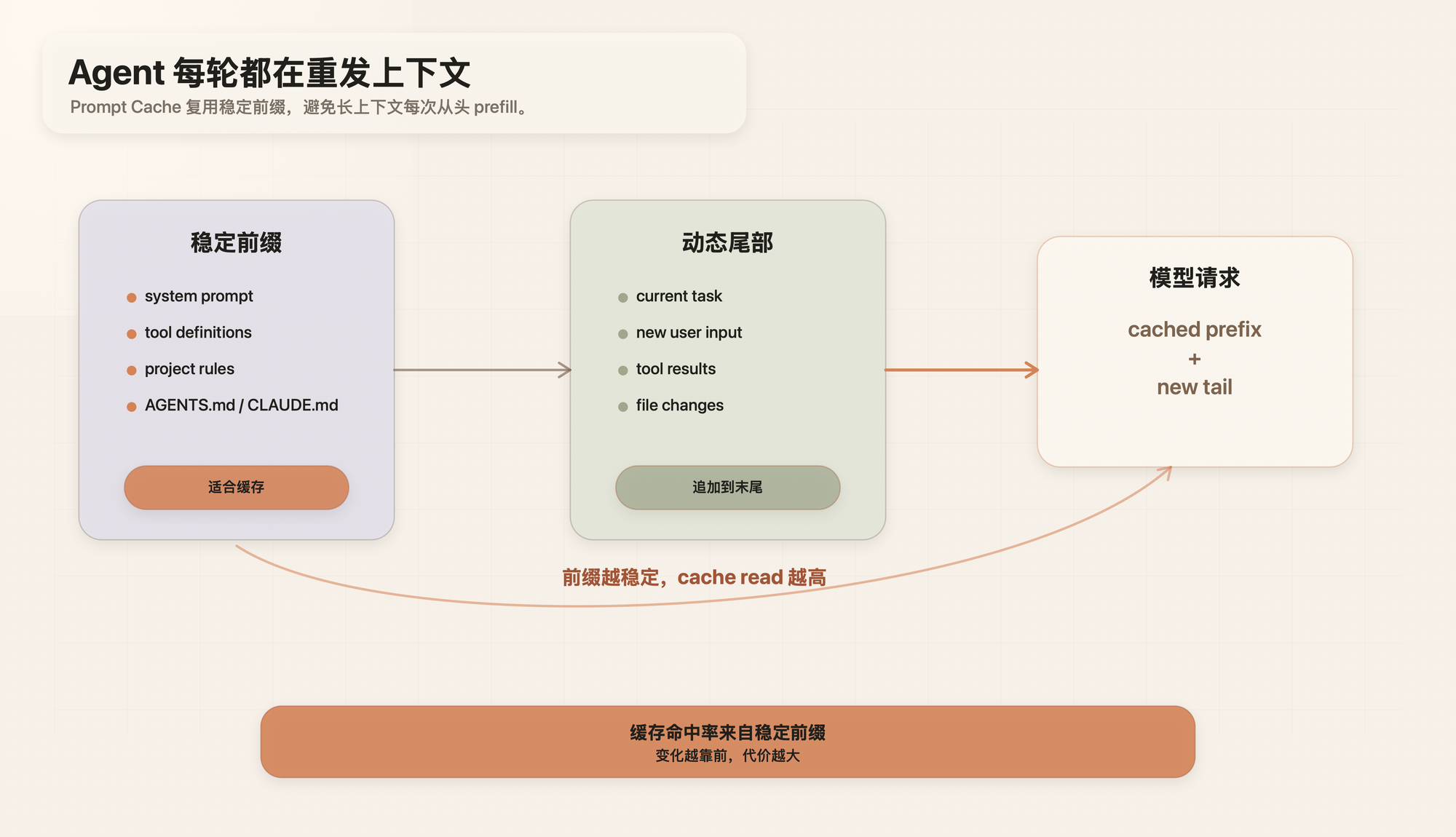
Coding agent 每走一步,都不是简单地“接着聊”。从模型调用的角度看,它通常要把系统提示、工具定义、项目规则、历史消息、工具结果、读过的文件和这一次的新输入重新组织起来,再发给模型。
这里有两点。
第一,输入上下文会越来越长。
第二,其中相当一部分内容,每一轮其实都差不多。
如果这些稳定内容每次都重新 prefill,成本会涨,首 token 延迟会涨;在订阅产品里,也更容易体现为额度消耗、限流或等待。
所以 Prompt Cache 会变得重要。
Prompt Cache 不是锦上添花的性能优化。对 Claude Code、Codex 这类 coding agent 来说,缓存命中率不是优化项,而是架构约束。
Coding Agent 贵在哪里
普通短聊天里,输入和输出通常都不长。用户关心的是回答好不好,往往不会太在意每一轮背后到底重发了多少上下文。
Coding agent 不一样。
它要理解项目规则,要知道有哪些工具,要记住之前读过哪些文件,要带上工具调用结果,还要把当前任务状态交给模型。一次两次还好,任务一长,上下文会迅速膨胀。
这里可以拆成两笔账。
第一类是 token 成本。 长上下文本身就意味着更多输入 token。对 API 用户来说,这会直接反映到账单里;对订阅用户来说,它不一定以账单形式出现,但往往会体现在额度消耗、限流、等待和可用任务量上。
第二类是时间成本,也就是 TTFT,time to first token。 模型在开始输出第一个 token 之前,要先处理完整输入上下文。上下文越长,prefill 越重,首 token 就越容易变慢。
所以任务一长,agent 的难点就会从“模型会不会写代码”,转到上下文怎么组织:
哪些上下文每轮都必须带?
哪些内容是稳定的?
哪些内容每轮都在变?
稳定的前缀能不能不要反复算?
Prompt Cache 解决的就是这个问题:稳定前缀能不能不要反复算。
要理解 Prompt Cache,得先从 KV Cache 说起。
Attention 里的 Q、K、V
Transformer 里的 attention 可以粗略理解成一个检索过程。
每个 token 会产生三类向量:
- Query:我现在想找什么信息
- Key:我这里有什么信息,可以被别人匹配
- Value:如果别人匹配到了我,应该取走什么内容
生成下一个 token 时,模型会用当前位置的 Query 去和上下文里已有 token 的 Key 做匹配,然后对对应的 Value 加权求和。原论文里把 attention 描述成 query 到一组 key-value pairs 的映射,Q/K/V 这套说法就来自这里。
麻烦在于,自回归模型生成文本时不是一次吐完整段,而是一 token 一 token 往外写:
输入 prompt -> 预测第 1 个新 token
prompt + token1 -> 预测 token2
prompt + token1 + token2 -> 预测 token3
...
如果什么都不缓存,每生成一个新 token,模型都要重新为全部历史 token 计算一遍 Key 和 Value。生成到第 1000 个 token 时,前面那 999 个 token 的中间结果已经被重复算了很多次。
这很浪费。
KV Cache:同一次生成里,历史 token 不要重复算
KV Cache 的做法并不复杂:每一层 attention 第一次处理某个 token 时,把它产生的 Key 和 Value 存下来。下一步生成时,模型只需要计算当前 token 的 q_t、k_t、v_t,再把当前 k_t / v_t 和历史 K/V 拼在一起做 attention。
没有 KV Cache 时:
每一步都重新计算:
K(1..t), V(1..t)
有 KV Cache 时:
K_cache = [K1, K2, ..., Kt-1]
V_cache = [V1, V2, ..., Vt-1]
当前步只计算 q_t, k_t, v_t
把 k_t, v_t 和历史 K_cache / V_cache 拼起来
用 q_t 去 attend [K_cache, k_t] / [V_cache, v_t]
然后把 k_t, v_t 留在 cache 里,供下一步继续复用
KV Cache 能加速生成,就是因为它减少了同一次请求、同一次生成里的重复计算,尤其是 decode 阶段的重复计算。
但 KV Cache 不是免费的。它会占 GPU 显存或内存。batch size 越大、层数越多、head 数越多、序列越长,cache 就越大。
Hugging Face 的 Transformers 文档里把 cache 策略分成 Dynamic Cache、Static Cache、Quantized Cache 等,讨论的也是速度、内存和编译兼容性之间的取舍。
所以 KV Cache 解决的是一个推理内部问题:
同一次生成里,历史 token 已经算过的 K/V 不要重复算。
Prompt Cache 解决的是另一个问题。

Prompt Cache:多次请求之间,稳定前缀不要重复处理
很多人第一次听 Prompt Cache,会以为它是在缓存模型回答。像网页缓存一样:同样的问题来了,直接把上次答案返回。
不是。
Prompt Cache 缓存的不是回答,而是 prompt 前缀经过 prefill 后得到的中间态。 你可以把它理解成 attention 层的 KV tensors 或等价状态。
下一次请求如果开头那段 prompt 完全一样,服务商就可以跳过这段前缀的 prefill 计算。
这里有两个阶段要分清:
prefill:处理输入 prompt,把整段上下文先喂进模型
decode:一个 token 一个 token 生成输出
- KV Cache 主要让 decode 阶段别重复算历史 token。
- Prompt Cache 主要让下一次 API 请求别重复 prefill 同一段长前缀。
一个 coding agent 的请求,常常长得像这样:
system prompt
tool definitions
project rules
AGENTS.md / CLAUDE.md
conversation history
tool results
new user message
如果前面几万 tokens 都没变,只有最后的新消息变了,前面那部分就不应该每次都重新算。Prompt Cache 就是在服务商推理层把这件事产品化。
OpenAI 文档给出的实践建议很明确:prompt caching 依赖 exact prefix match。静态内容放在开头,动态内容放在末尾。工具、schema、图片、音频、结构化输出格式,都会影响缓存命中。
OpenAI 还会基于 prompt 初始前缀的 hash 做路由,让相似请求尽量落到有缓存的机器上。
Anthropic 的机制更显式一些。它有两种方式:一种是在请求顶层加 cache_control,让系统自动把 cache breakpoint 放到最后一个可缓存 block;另一种是在具体 block 上显式设置 cache_control breakpoint。
缓存对象不是某个孤立片段,而是从请求开头到 breakpoint 为止的完整 prefix,顺序是 tools、system、messages。
所以 breakpoint 要放在稳定内容之后。如果 breakpoint 所在 block 本身每轮都变,后续请求就很难命中。默认 ephemeral cache 是 5 分钟 TTL,也支持 1 小时 TTL。写入和读取的价格不同:写入比普通输入 token 贵,读取则便宜很多。
实现细节每家不同,但工程原则是同一个:
prefix 越稳定,命中率越高;变化越靠前,代价越大。
为什么 Agent 比普通聊天更依赖 Prompt Cache
短对话不一定特别依赖 Prompt Cache。几轮对话、几千 tokens,就算每次重新 prefill,用户可能也感觉不到太大差别。
但只要进入长文档问答、RAG、客服系统或 coding agent,情况就变了。只要有大量稳定前缀,Prompt Cache 就会直接影响成本和延迟。
Agent 尤其典型。它不是只把“你刚刚说了什么”发给模型,而是把运行它所需要的世界重新拼出来:
- 系统提示
- 工具定义
- 工具调用协议
- MCP server 信息
- 项目规则
- 之前读过的文件内容
- 历史对话
- 工具结果
- 当前任务状态
- 新的用户输入
Claude Code 文档里也直接说明,每次你发消息,它都会发起新的 API 请求;模型在请求之间不记得任何内容,所以 Claude Code 会重新发送完整上下文。
这也是为什么长程 agent 任务里,Prompt Cache 的收益会非常大。2026 年一篇关于 long-horizon agentic tasks 的评测显示,在 OpenAI、Anthropic、Google 三家 provider 上,prompt caching 可以让 API 成本降低约 40% 到 80%,TTFT 也就是 time to first token 改善 13% 到 31%。
这不是对所有 agent 的通用承诺,而是在特定 long-horizon agent benchmark 下的测量结果。但它说明了一个方向:上下文越长、稳定前缀越大,Prompt Cache 的收益越明显。
这个数字背后的直觉很简单:agent 的大部分上下文,在很多轮里都是相同的。每一轮新增的内容,可能只有最后几百或几千 tokens。稳定前缀越能复用,收益就越明显。
但前提是,你真的有稳定前缀。
稳定前缀怎样影响 Agent 架构
Prompt Cache 最容易被低估的一点是:它会反过来塑造 agent harness 的设计方式。
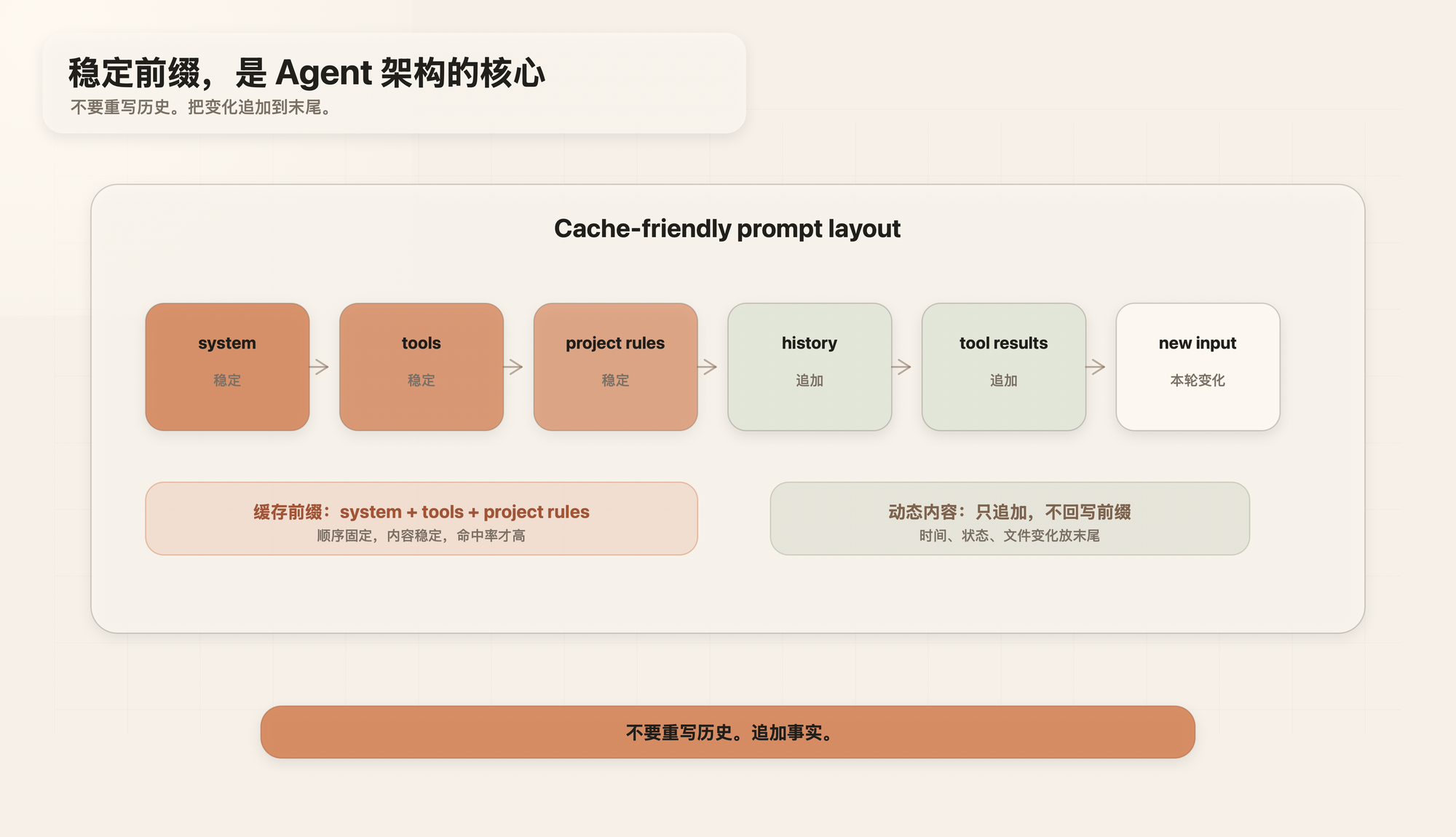
一个 cache-friendly 的 agent,不应该每一轮都重新组织 prompt。它应该把稳定的东西放在前面,把变化追加到后面。
稳定内容包括:
system prompt
tool definitions
structured output schemas
sandbox configuration
project rules
long-term instructions
动态内容包括:
当前时间
本轮用户输入
临时状态
刚刚执行的工具结果
文件变更提醒
任务阶段变化
一种常见错误,是每一轮都修改 system prompt。比如把当前时间、当前任务阶段、最新文件状态都塞回系统提示里。
这样看起来语义上很干净,但工程上会破坏前缀。变化越靠前,代价越大。
这时不要改前缀,直接追加消息:
前缀保持不变
新的状态变化作为 message / tool result 追加到末尾
Claude Code 就是这么做的。文件发生变化时,它不会回头改历史里已经读过的文件内容,而是追加一个 system reminder。Plan Mode 也不是靠切换工具集实现,而是保留稳定工具表,把模式变化放到工具或消息层。
这是 Prompt Cache 带来的设计哲学:
不要重写历史。追加事实。
Claude Code 怎么设计缓存友好的上下文
Claude Code 的公开文档和工程文章里,能看到一套围绕缓存设计的上下文顺序。
它的大致上下文顺序是:
静态 system prompt
工具定义
CLAUDE.md
session context
conversation messages
前面的内容越稳定,缓存收益越大。
system prompt 和 tools 放最前面
系统提示和工具定义属于高复用内容。它们通常很长,而且每一轮都要出现。所以它们必须稳定。
Claude Code 团队提过一些真实踩坑:在静态 system prompt 里放时间戳、非确定性地打乱工具顺序、修改工具参数,都会破坏 Prompt Cache。
所以,“按需只给模型当前需要的工具”听起来省 tokens,但未必划算。因为 tools array 本身在 cached prefix 里。你这轮删一个工具,下轮加回来,prefix 就变了。
工具表保持稳定,调用权限交给选择机制。
不要中途换模型和 effort level
Claude Code 文档明确说,模型和 effort level 都是 cache key 的一部分。中途从一个模型切到另一个模型,即使 prompt 内容完全一样,也需要为新模型重新建立缓存。
这点有点反直觉。
你可能觉得:“这个任务太贵了,我切到便宜模型继续跑。”但如果当前会话已经积累了 100k tokens 的缓存,切模型会让这些缓存失效。新模型要重新 prefill 整段上下文。便宜模型未必真的更便宜。
所以长任务最好在开始前确定:
模型
effort / thinking level
MCP servers
工具集
沙箱配置
不要做到一半再改底层配置。
CLAUDE.md 要短、稳、项目级
CLAUDE.md 适合放你本来每次都要重复告诉模型的东西:
怎么 build
怎么 test
项目结构
编码约定
必须遵守的规则
但它不适合写成项目百科全书。
太长的 CLAUDE.md 会让每一轮上下文变重。太动态的 CLAUDE.md 会降低缓存稳定性。局部规则、多步骤流程、只在部分目录生效的知识,更适合放到 skill、path-scoped rule 或按需加载的文件里。
一个好的 CLAUDE.md 应该短、准、稳定。
compact 要在自然断点用
Compaction 会用 summary 替换历史消息,所以它天然会改变 conversation layer。它能控制上下文长度,但也会带来缓存上的损失。
还有一个细节:cache-safe compaction 不是随便另起一个 summarization prompt。Claude Code 生成 summary 时,会复用当前会话的 system prompt、tools 和 history,只把 summarization instruction 追加到末尾。这样生成 summary 的那次请求还能读已有 cache。compact 之后改变的是 conversation layer。
这不是说不要 compact。长任务不 compact,上下文会越来越长,注意力会分散,成本也会越来越高。问题在于时机。
可以把 compact 放在子任务结束后。比如功能写完、测试跑完、准备进入下一阶段时。不要等 auto-compaction 在任务中间突然触发。
如果只是想回到早先路线,rewind 往往比 compact 更 cache-friendly,因为它是截断回之前已经存在过、可能已经缓存过的 prefix。
监控 cache read 和 cache creation
Agent 的缓存命中率应该像错误率、延迟和成本一样被监控。
Anthropic / Claude 侧可以看:
cache_read_input_tokens
cache_creation_input_tokens
OpenAI 侧可以看:
cached_tokens
如果 cache read 很高,说明缓存工作正常。如果 cache creation 连续偏高,通常不是“流量正常波动”,而是 prefix 在变。常见原因包括:
system prompt 里有时间戳
工具顺序不稳定
schema key 顺序变化
MCP server 中途连接或断开
模型或 effort 变了
随机 UUID 放进了前缀
这类问题已经超出计费范围。它说明 agent harness 的上下文组织方式不稳定。

Codex 和 OpenAI Agent 的缓存设计
OpenAI 侧的原则和 Anthropic 很像:尽量稳定前缀,减少中途结构变化。
OpenAI Prompt Caching 201 里提到,Codex CLI 会保持这些内容的顺序稳定:
system instructions
tool definitions
sandbox configuration
environment context
运行时配置如果发生变化,agent loop 倾向于 append 新消息,而不是修改原始 prefix。
这和 Claude Code 是同一个方向。
tools 和 schema 不要频繁变化
OpenAI 文档也强调,tools、schema 和它们的顺序都会进入 cached prefix。schema key 顺序变化、工具顺序变化、instructions 变化,都可能让缓存失效。
所以不要为了“省一点工具定义 token”频繁改 tools array。
可以这样做:
保留稳定 tools array
用 allowed_tools / tool_choice 限制本轮可调用工具
这会多带一点工具定义,但换来的是稳定缓存。对长程 agent 来说,这笔账常常是划算的。
Claude Code / MCP 场景下,还可以用 tool search 减少完整工具定义对 prefix 的占用,但工具集合本身仍要保持稳定。
AGENTS.md 管稳定项目知识
Codex 用 AGENTS.md 承载项目级指导。官方文档建议把 repo layout、运行方式、build/test/lint 命令、工程约定、PR 预期、约束和 done definition 写进去。
但 AGENTS.md 也不应该写成百科全书。
它的作用不是替代文档库,而是把每次 agent 工作都需要的稳定知识放到上下文前部。短而准确,比长而模糊更有用。
一个实用判断是:
如果你愿意每次开新 session 都手动重复这句话,它就适合进 AGENTS.md。 如果它只在某个任务、某个目录、某个阶段有用,就不要塞进全局前缀。
prompt_cache_key 是路由提示,不是魔法
OpenAI 的 prompt_cache_key 可以帮助相似请求路由到更可能有缓存的机器。可以把它理解成一种“路由粘性”提示。
但它不能修复不稳定 prefix。
如果 prompt 前缀每轮都变,再好的 key 也救不了。反过来,如果 key 设计得太粗,流量可能超过单个 prefix+key 组合的承载,溢出到其他机器;太细,又会把本来可以共享缓存的请求打散。
coding agent 的经验做法通常是按用户、会话或 bucket 分组,而不是所有请求共用一个 key,也不是每个请求都随机生成一个 key。
compaction 和缓存有天然张力
Context engineering 和 prompt caching 之间天然有冲突。
为了让模型保持专注,你想 drop、summarize、compact 早期 turns。 为了让缓存命中,你又希望 prefix 尽量不变。
这没有固定答案。好的 agent 需要用 evals 找平衡点:什么时候 compact、保留多少原文、summary 怎么写、哪些工具结果必须原样保留、哪些可以压缩。
不能只看单轮 token 数。要看总成本、TTFT、cache hit rate 和任务质量。
几个容易误解的点
第一,Prompt Cache 不是 response cache。
它不会把模型回答存起来,也不是“同样问题直接返回上次答案”的网页缓存。
Prompt Cache 复用的是 prompt prefix 的中间态,主要跳过重复的 prefill 计算;输出 token 仍然会重新生成。cache 与否不应该改变输出生成逻辑。相同输入是否得到完全一致的结果,取决于采样参数、seed 和服务端实现,而不是 Prompt Cache 本身。
第二,短 prompt 不一定省钱。
如果一个 prompt 只有 900 tokens,在 OpenAI 的 1024 token 门槛下可能永远不会命中缓存。某些情况下,把稳定前缀扩到 1100 tokens,并让它在后续高频命中,总成本反而可能更低。
第三,便宜模型不一定便宜。
如果一个长会话已经在某个模型上建立了大量缓存,中途切到另一个更便宜的模型,可能要重新处理整段上下文。账要按整个任务算,不要只看单 token 单价。
第四,动态工具集会破坏缓存。
临时增删工具看似聪明,实际可能让 cached prefix 频繁变化。Claude Code 和 Codex 的共同经验都是:工具定义尽量稳定,调用权限用选择机制控制。
第五,cache miss 不一定是 bug,但连续 cache creation 偏高是信号。
TTL 过期、冷启动、路由变化都会导致 cache miss。但如果一个长会话里 cache creation 连续偏高,就该查架构了:前缀里一定有什么东西在动。
落地检查清单
写 agent,或者深度使用 Claude Code / Codex 时,可以按这份清单检查。
- 静态内容:system prompt、工具定义、schema、项目规则放在最前面,顺序固定。
- 动态内容:当前时间、用户输入、临时状态、文件变更放到末尾消息里。
- 工具集:不要中途增删;OpenAI 侧用 allowed_tools / tool_choice 控制本轮可用工具;Claude Code / MCP 场景下用 tool search 减少完整工具定义占用,但工具集合保持稳定。
- 模型和 effort:任务开始前选定,不要中途切。
- 项目规则:Claude 用 CLAUDE.md,Codex 用 AGENTS.md,保持短、准、稳。
- compaction:在自然断点做,不要让 auto-compaction 在重要步骤中间触发。
- TTL:短间隔用默认缓存;长间隔、side-agent、用户可能离开时,在服务商支持的前提下考虑更长 TTL。
- 监控:OpenAI 看 cached_tokens;Anthropic 看 cache_read_input_tokens 和 cache_creation_input_tokens。
- 并发:首个请求要先建立 cache;平行请求太早发出,可能都 miss。
- 调试:先查时间戳、随机 ID、工具顺序、schema key 顺序、MCP 状态、模型和 effort 是否变化。
一句话总结
KV Cache 解决的是:同一次生成里,历史 token 不要重复算。
Prompt Cache 解决的是:多次请求之间,稳定 prompt 前缀不要重复 prefill。
Agent 很容易吃到 Prompt Cache 的收益。原因也简单:它每一步都要重发完整上下文,而这些上下文的大部分本来就应该是稳定的。
所以好的 agent harness 不应该频繁重写 prompt。它应该把系统提示、工具定义、项目规则这些稳定内容固定在前面,把变化追加到消息末尾。
它也不应该频繁动态增删工具,而应该保持工具表稳定,再用选择机制控制本轮能调用什么。
Claude Code 和 Codex 的共同经验其实很朴素:
缓存命中率来自稳定前缀。
前缀越稳定,agent 越便宜、越快;变化越靠前,代价越大。
参考资料:
- Attention Is All You Need: https://arxiv.org/abs/1706.03762
- Hugging Face Transformers KV Cache docs: https://huggingface.co/docs/transformers/en/kv_cache
- Hugging Face cache explanation: https://huggingface.co/docs/transformers/cache_explanation
- OpenAI Prompt Caching docs: https://developers.openai.com/api/docs/guides/prompt-caching
- OpenAI Prompt Caching 201: https://developers.openai.com/cookbook/examples/prompt_caching_201
- Anthropic Prompt Caching docs: https://platform.claude.com/docs/en/build-with-claude/prompt-caching
- Claude Code prompt caching docs: https://code.claude.com/docs/en/prompt-caching
- Claude Code prompt caching engineering notes: https://claude.com/blog/lessons-from-building-claude-code-prompt-caching-is-everything
- Anthropic Claude Code best practices: https://www.anthropic.com/engineering/claude-code-best-practices
- OpenAI Codex AGENTS.md docs: https://developers.openai.com/codex/guides/agents-md
- OpenAI Codex best practices: https://developers.openai.com/codex/learn/best-practices
- An Evaluation of Prompt Caching for Long-Horizon Agentic Tasks: https://arxiv.org/abs/2601.06007