核心结论
配套代码仓库: github.com/llm-101/mini-agent-harness
读完本文,你应该能回答
- 为什么 Agent 系统需要分层,而不是一个大 loop?
- Product Shell、Harness API、Agent Loop、Tool Runtime 等层分别承担什么?
- 依赖方向为什么比目录结构更重要?
- 一个小型 Harness 如何避免变成不可维护的脚本堆?
本篇在系列中的位置
- 上一篇:01 Agent Harness 定义了模型之外的运行时。
- 本篇:本文把这个运行时拆成从模型边界到产品外壳的层次。
- 下一篇:03 LLM Call 会进入最靠近模型 provider 的边界。
贯穿例子
本系列会反复使用同一个任务来连接各章:
用户说:“帮我修复这个 repo 里的 failing tests。”
在本文里,重点不是这个任务最终怎么修好,而是看清楚:当这个任务穿过 Layered Architecture 这一层时,Harness 需要承担什么责任,哪些状态要留下,哪些决策不能交给模型随意处理。
Agent Harness 不是一个单层模块。
它更像一组围绕模型调用展开的运行时边界:产品外壳、公共 API、Agent Loop、模型边界、工具边界、状态与上下文、资源与扩展。
分层架构的价值不是“看起来更工程化”,而是解决 Agent 系统最容易失控的几个问题:
- UI 变化不应该迫使你重写 Agent Loop。
- 模型 provider 变化不应该污染运行时核心。
- 工具执行错误不应该直接让整个 Agent 崩溃。
- 会话状态不应该只是一个越来越长的 messages 数组。
- Skills、prompt templates、policy hooks 不应该全部塞进一个巨大 system prompt。
- 事件、trace、usage、tool loader 这些产品体验应该来自稳定事件流,而不是从模型 SDK 临时拼出来。
mini-agent-harness 的架构刻意小,但它体现了一个生产级 Agent 系统的基本方向:
上层依赖稳定抽象;下层隐藏外部差异;运行时核心只面对内部 contract。
为什么 Agent 需要分层
很多早期 Agent demo 看起来像这样:
const response = await model.chat({ messages, tools });
if (response.tool_calls) {
for (const call of response.tool_calls) {
const result = await tools[call.name](call.arguments);
messages.push({ role: "tool", content: result });
}
}
这段代码可以跑。
但只要你继续往里面加功能,它很快会变成一团:
- 要支持 OpenAI 和 Anthropic 两种消息格式;
- 要支持 streaming;
- 要把工具调用渲染到 UI;
- 要允许用户取消运行;
- 要保存 session;
- 要在上下文过长时 compact;
- 要允许工具并行执行;
- 要接入 skills;
- 要在高风险工具调用前加 policy hook;
- 要让 CLI、TUI 和未来 SDK 复用同一套能力。
如果所有逻辑都堆在一个函数里,系统会出现三个问题。
第一,边界混乱。
UI 代码开始关心 provider 格式,模型适配器开始知道工具实现,工具错误直接影响产品渲染,会话状态散落在多个调用点。
第二,演进困难。
你想换模型,就要改 Agent Loop;你想换 UI,就要改工具执行;你想加权限系统,就要插进一堆临时代码。
第三,调试困难。
出错时你很难判断:到底是模型输出格式错了、工具参数错了、session 状态错了、context builder 漏了信息,还是 UI 渲染事件顺序错了。
所以 Agent Harness 的第一件事,就是把这些问题拆到不同层。
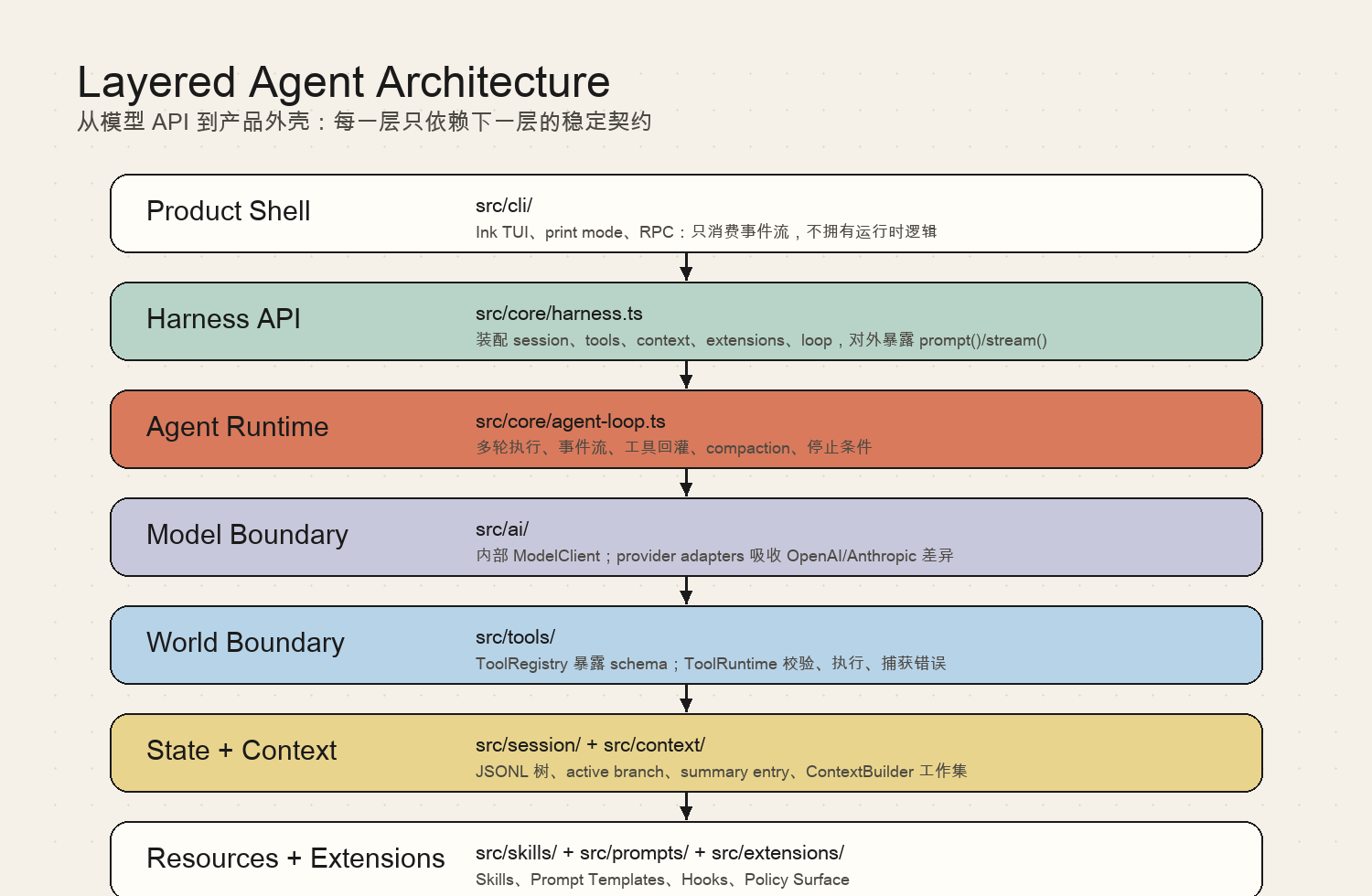
mini-agent-harness 的七层结构
当前仓库可以理解成七层。
Product Shell
→ Harness API
→ Agent Runtime
→ Model Boundary
→ Tool Boundary
→ State + Context
→ Resources + Extensions
这不是一个严格的“只能向下调用”的企业架构图,而是一个教学用的依赖方向图:每一层应该知道什么、不应该知道什么。
1. Product Shell:产品外壳
代码位置:src/cli/
Product Shell 是用户接触 Agent 的界面。
在这个仓库里,它包括:
print-mode.ts:一次性命令行输出,适合脚本和测试。interactive-mode.tsx:基于 Ink 的交互式终端 UI。rpc-mode.ts:面向自动化或外部调用的 RPC 形态。components/:消息列表、Markdown 渲染、输入框、状态栏、工具动画。
Product Shell 的关键原则是:
它可以消费运行时事件,但不应该拥有运行时逻辑。
也就是说,TUI 可以决定怎么显示 tool_call_start,但不应该决定工具怎么执行。
TUI 可以决定怎么渲染 message_update,但不应该直接解析 provider streaming 协议。
TUI 可以让用户按 Escape 取消任务,但取消信号应该进入运行时边界,而不是让 UI 自己猜 Agent 当前卡在哪里。
这也是为什么交互式界面通过 harness.stream() 获取事件流,而不是直接调用 model.stream()。
2. Harness API:公共入口
代码位置:src/core/harness.ts
MiniAgentHarness 是外部使用者看到的入口。
它负责装配系统,而不是执行所有细节。
构造函数里可以看到几个核心对象:
this.session = new JsonlSessionStore(options.sessionFile);
this.extensions = new ExtensionRuntime();
this.eventBus = new EventBus();
this.loop = new AgentLoop({
model: options.model ?? new EchoModelClient(),
tools: this.tools,
session: this.session,
contextBuilder: new ContextBuilder(),
systemPrompt: options.systemPrompt ?? defaultSystemPrompt,
cwd: options.cwd,
extensions: this.extensions,
compactionThreshold: options.compactionThreshold,
toolExecution: options.toolExecution,
eventBus: this.eventBus,
thinkingLevel: options.thinkingLevel,
});
这里的设计很重要。
MiniAgentHarness 不直接执行工具,不直接拼接上下文,不直接处理 provider streaming,也不直接渲染 UI。
它做的是“装配”:把模型、工具、状态、上下文、扩展和事件总线组合成一个可用的 Agent Runtime。
对外只暴露少数方法:
await harness.load();
await harness.prompt("summarize this repo");
for await (const event of harness.stream("run tests")) {
// UI or script consumes events
}
for await (const event of harness.continueStream()) {
// resume from current session state
}
这让上层产品不必理解所有内部模块。
3. Agent Runtime:运行时核心
代码位置:src/core/agent-loop.ts
AgentLoop 是系统的执行核心。
它不关心 UI 是 Ink、Web 还是 SDK,也不关心底层 provider 是 OpenAI-compatible 还是 Anthropic-compatible。
它只面对几类内部 contract:
ModelClientToolRegistry/ToolRuntimeJsonlSessionStoreContextBuilderExtensionRuntimeAgentEvent
runLoop() 的职责是推动状态前进:
append user message
→ maybe compact session
→ build context
→ call model
→ append assistant message
→ execute tool calls
→ append tool results
→ continue or stop
这看起来像 while loop,但它更接近一个小型运行时:
- 它维护 turn 生命周期。
- 它检查
AbortSignal。 - 它触发 extension hooks。
- 它处理 streaming message delta。
- 它记录 usage 和 trace。
- 它把 assistant message 和 tool result 写回 session。
- 它把运行过程转换成事件流。
这就是 Agent Runtime 和普通脚本的区别。
普通脚本只关心“执行完了吗”。
Agent Runtime 还要关心“执行过程中发生了什么、是否可以恢复、是否可以展示、是否可以治理”。
4. Model Boundary:模型边界
代码位置:src/ai/
模型边界的目标,是让 Agent Loop 不直接依赖任何 provider SDK。
内部接口在 src/types.ts:
export interface ModelClient {
complete(request: ModelRequest): Promise<ModelResponse>;
}
export interface ModelRequest {
systemPrompt: string;
messages: AgentMessage[];
tools: ToolSchema[];
thinkingLevel?: "none" | "low" | "medium" | "high";
}
这意味着 Agent Loop 只知道:给模型一个内部格式的请求,拿回内部格式的响应。
外部 provider 的差异由 src/ai/ 吸收。
例如:
EchoModelClient:无 API key 也能运行,适合教学和测试。LlmClient:把内部ModelRequestnormalize 成 provider 请求。OpenAICompatibleProvider:处理 OpenAI-compatible SSE、tool calls、usage。AnthropicCompatibleProvider:处理 Anthropic-style content blocks、tool use、thinking。
LlmClient 的核心逻辑很小:
private normalize(request: ModelRequest): NormalizedModelRequest {
return {
...request,
model: this.options.config.model,
temperature: this.options.config.temperature,
maxOutputTokens: this.options.config.maxOutputTokens,
tools: request.tools ?? [],
};
}
小不代表不重要。
这个边界决定了:
- 换模型时不重写 Agent Loop。
- provider streaming 差异不泄漏到 UI。
- tool call 格式差异不污染 session 层。
- usage / thinking / text delta 都能被归一化成运行时事件。
这和 Cursor 文章里“为不同模型定制 harness”的思想一致:模型差异真实存在,但应该由 harness 的适配层吸收。
5. Tool Boundary:工具边界
代码位置:src/tools/
工具边界负责把模型生成的工具调用意图,变成真实世界里的动作。
这里要区分两件事:
ToolRegistry:告诉模型有哪些工具,以及工具 schema 是什么。ToolRuntime:真正执行工具,处理参数校验、错误捕获和执行模式。
ToolRuntime 支持顺序执行和并行执行:
export type ToolExecutionMode = "sequential" | "parallel";
async executeAll(calls) {
if (this.mode === "parallel") {
return Promise.all(calls.map((call) => this.execute(call.name, call.input)));
}
// otherwise sequential
}
它还在执行前做 required 参数检查:
const validationError = validateRequiredParams(tool, input);
if (validationError) {
return { content: validationError, isError: true };
}
注意这里的错误处理方式。
工具参数错误不会直接 throw 到 Agent Loop 外面,而是变成 ToolResult,随后写回 tool message。
这意味着模型下一轮可以看到错误并尝试自我修正。
这正是 Harness 的职责:不是假设模型永远正确,而是设计一个能容纳错误、反馈错误、继续推进的运行时。
6. State + Context:状态与上下文
代码位置:
src/session/src/context/src/compaction/
State 和 Context 必须分开。
State 是系统保存的事实源。
Context 是本轮模型调用看到的工作集。
JsonlSessionStore 负责把消息和 summary 写入 JSONL 文件,并用 parent-child entry 结构支持 active branch。
这比一个普通 messages 数组更适合 Agent,因为 Agent 需要:
- 进程退出后恢复;
- 在长会话中 compact;
- 在未来支持 fork / branch;
- 区分普通 message 和 summary entry;
- 从 active leaf 重建当前分支。
ContextBuilder 则负责把当前需要给模型看的内容整理成工作集:
const messages = [...(input.dynamicMessages ?? []), ...input.messages];
return {
systemPrompt: input.systemPrompt,
messages,
tools: input.tools,
metadata: {
messageCount: messages.length,
toolCount: input.tools.length,
},
};
当前实现很小,但边界非常关键。
因为真正复杂的上下文工程都应该进入这个位置,而不是散落在模型调用前:
- 系统提示;
- 项目规则;
- skills;
- 当前会话分支;
- 工具 schema;
- 动态环境信息;
- 检索结果;
- compact summary。
7. Resources + Extensions:资源与扩展
代码位置:
src/skills/src/prompts/src/extensions/
这一层体现了 mini-agent-harness 的一个设计规则:
如果一个能力可以作为 hook、extension 或 skill 演示,就不要把它硬编码进 core。
SkillLoader 会扫描 SKILL.md,然后把技能格式化为 <skills> XML blocks 追加到 system prompt。
PromptTemplate 则让用户定义可复用的任务入口。
ExtensionRuntime 提供多个运行时 hook:
beforeContextBuild
beforeModelCall
afterModelCall
beforeToolCall
afterToolCall
这些 hook 可以承载很多生产系统里的能力:
- 权限检查;
- 路径保护;
- 动态上下文注入;
- telemetry;
- tool result 改写;
- prompt guardrail;
- plan mode;
- policy enforcement。
这样做的好处是,Agent Loop 仍然保持小而清晰。
依赖方向:不要让细节穿透边界
分层架构最容易犯的错误,是“目录分层了,但依赖没分层”。
也就是说,代码看起来有 cli/、core/、ai/、tools/,但实际上 UI 直接 import provider SDK,model adapter 直接写 session,tool runtime 直接调用 React component。
这不是真分层,只是文件夹分类。
真正重要的是依赖方向。
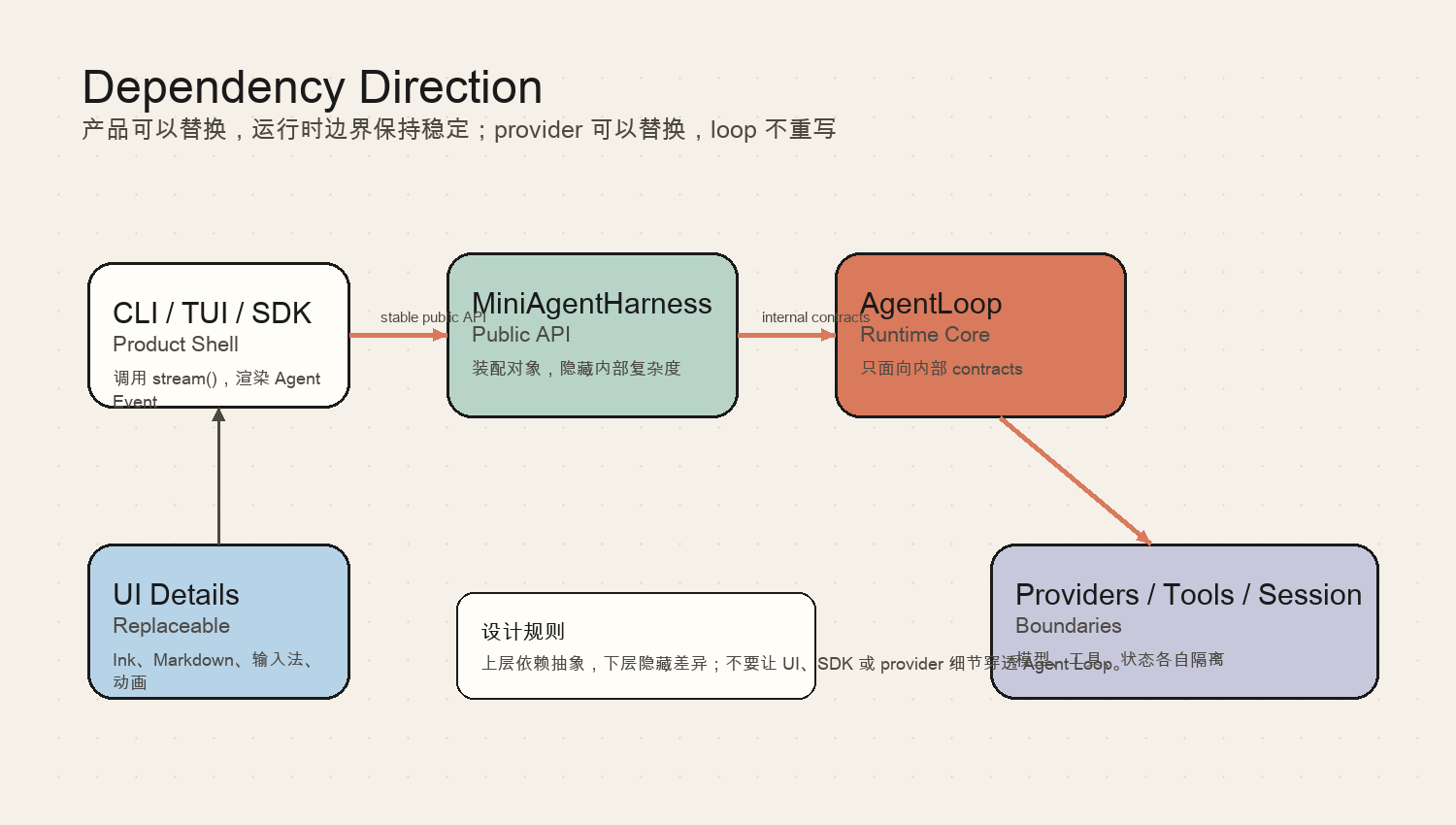
在 mini-agent-harness 中,方向大致是:
CLI / TUI / RPC
→ MiniAgentHarness
→ AgentLoop
→ internal contracts
→ Model provider adapters
→ Tool runtime
→ Session store
→ Context builder
→ Extensions
Product Shell 可以替换。
Provider 可以替换。
Tool 可以增加。
Session store 未来可以从 JSONL 换成数据库。
但 Agent Loop 依然应该面对稳定内部 contract。
这就是分层的意义。
事件流是 Product Shell 和 Runtime 的协议
mini-agent-harness 中最关键的边界之一,是 AgentEvent。
Agent Runtime 不返回一坨最终字符串,而是持续发出事件。
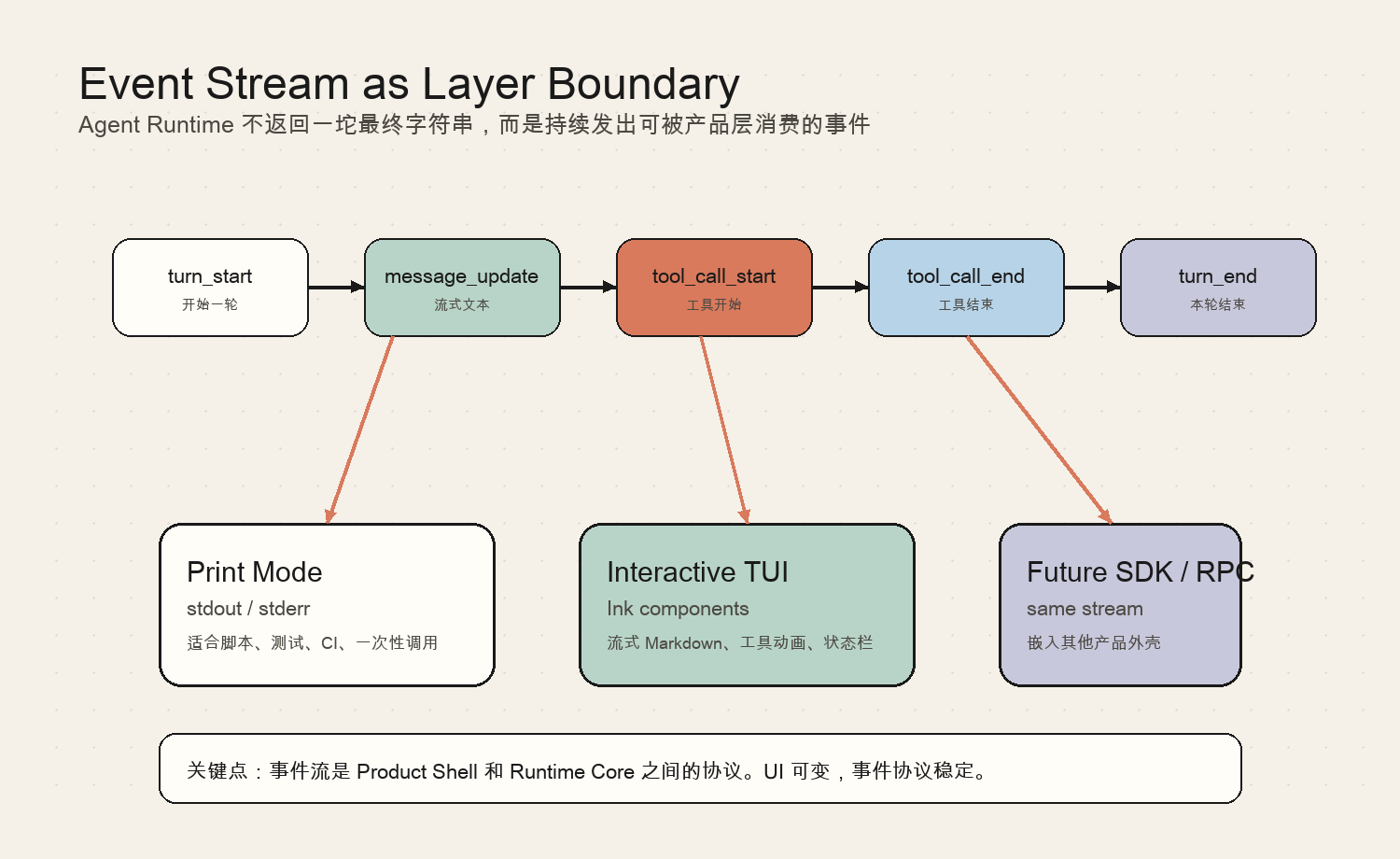
这让不同 Product Shell 可以复用同一个 Runtime:
- print mode 把事件打印到 stdout / stderr;
- interactive TUI 把事件渲染成 Markdown、工具动画和状态栏;
- 未来 SDK / RPC 可以把事件转成 JSON stream;
- Web UI 可以把事件转成 SSE / WebSocket 消息。
事件流是一个非常重要的设计点。
如果 Runtime 只返回最终答案,产品层就看不到:
- 当前是否开始新 turn;
- 模型是否正在 streaming;
- tool call 何时开始;
- tool call 输入是什么;
- tool call 何时结束;
- 是否触发了 compaction;
- usage 是否更新;
- 是否处于 thinking 状态。
一旦这些信息不可见,UI 就只能猜。
而一个需要猜运行时状态的 UI,最终会把运行时逻辑复制到产品层。
所以,事件流不只是“方便显示进度”。
它是 Product Shell 和 Agent Runtime 之间的协议。
和定义文章的对应关系
这一篇讨论的是分层,但它仍然和 Cursor、OpenAI、Anthropic、Martin Fowler 的 harness 定义直接相关。
OpenAI 把 harness 称为模型周围的控制平面。控制平面之所以可控,是因为 agent loop、tool routing、approvals、tracing、recovery 和 run state 有明确边界。
Cursor 强调不同模型需要不同 harness 定制。分层架构让这种定制落在 model boundary、prompt、tool schema 和 evaluation 层,而不是污染 UI 或 session。
Anthropic 讨论 long-running agents 时强调 initializer agent、coding agent、progress file、git history 等环境管理机制。这些能力需要落到 state、context、resources 和 workflow 层,而不是只靠 compaction。
Martin Fowler 讨论 user harness 时强调 guides 和 sensors。放在这套架构里,guides 可以是 skills、prompt templates、rules、context files;sensors 可以是 tests、linters、tool result、trace、review agent 或 extension hook。
也就是说,外部文章讨论的 harness 能力,最终都需要一个分层架构来承载。
没有分层,harness 会变成越来越长的 prompt 和越来越大的 loop 函数。
有分层,harness 才能持续演进。
这篇文章的代码锚点
如果你想按代码理解这一篇,可以按这个顺序读:
docs/architecture.md- 总览当前仓库的分层说明和事件流。
src/core/harness.ts- 看公共 API 如何装配各层。
src/core/agent-loop.ts- 看运行时核心如何只面对内部 contract。
src/types.ts- 看 message、tool、model request、model response 的基础类型。
src/ai/llm-client.ts- 看 provider 差异如何被 normalize。
src/tools/tool-runtime.ts- 看工具边界如何处理 schema、执行、错误和并发。
src/context/context-builder.ts- 看 context boundary 为什么应该独立存在。
src/cli/components/App.tsx- 看 Product Shell 如何消费事件,而不是拥有 Runtime。
小结
Agent Harness 的分层架构可以用一句话总结:
Product Shell 负责呈现,Harness API 负责装配,Agent Runtime 负责推进,Model / Tool / State / Context / Extension 各自负责一个稳定边界。
这套结构的目的不是追求抽象本身,而是让 Agent 系统可以被理解、调试、替换和扩展。
在下一篇里,我们会继续往下拆第一条关键边界:LLM Call。
模型调用看起来只是 await model.complete(request),但真正的工程问题在于:如何设计一个稳定的内部模型接口,让 OpenAI-compatible、Anthropic-compatible、streaming、tool calls、usage、thinking 和错误语义都被隔离在边界层里。