Agent Engineering 101|03|LLM Call
LLM Call 是 Agent Harness 和模型 provider 之间的边界层。它不是一段 prompt,而是 provider、model、messages、tools、streaming、usage、stop reason 与输出契约组成的一次可观测推理请求。
核心结论
配套代码仓库: github.com/llm-101/mini-agent-harness
读完本文,你应该能回答
- LLM Call 和普通 API 调用有什么区别?
- 为什么 Agent Loop 不应该直接依赖 provider SDK?
- streaming、usage、stop reason、tool call 为什么要归一化?
- 模型边界做错后,复杂性会怎样扩散到整个系统?
本篇在系列中的位置
- 上一篇:02 Layered Architecture 给出了整体分层。
- 本篇:本文进入模型边界:Harness 如何把 provider 差异收束成稳定接口。
- 下一篇:04 Agent Loop 会使用这个稳定模型接口推动多轮行动。
贯穿例子
本系列会反复使用同一个任务来连接各章:
用户说:“帮我修复这个 repo 里的 failing tests。”
在这个任务里,LLM Call 负责把“先看测试、再运行命令、再判断失败”的推理请求组织成稳定的模型输入;同时把 provider 返回的文本、工具调用、usage 和停止原因还原成 Harness 能理解的统一输出。读者要关注的是:换模型 provider 时,修测试这条任务路径不应该重写 Agent Loop。
- LLM Call 是 Harness 调度的一次模型推理请求。它包含系统提示、消息列表、工具 schema、模型参数、provider-specific 选项、streaming 协议、usage 元数据和停止原因。
- 如果 Agent Loop 直接调用 provider SDK,模型差异会进入运行时核心:OpenAI-compatible 的 SSE chunk、Anthropic 的 content block、工具调用参数增量、usage 上报时机和 thinking 预算都会变成 loop 的分支。
- 在
mini-agent-harness中,这一层被写成单独的模型边界,目的就是让 Agent Loop 面对统一 contract,而不是面对 provider SDK。
定义
LLM Call 是 Harness 调度的一次模型推理请求。它包含系统提示、消息列表、工具 schema、模型参数、provider-specific 选项、streaming 协议、usage 元数据和停止原因。
为什么要单独看这一层?
模型 provider 的差异会持续变化:消息格式、streaming chunk、工具调用表达、usage 上报和停止原因都不完全一样。把这些差异留在 LLM Call 层,Agent Loop 才能只处理“下一步意图”和“统一结果”。
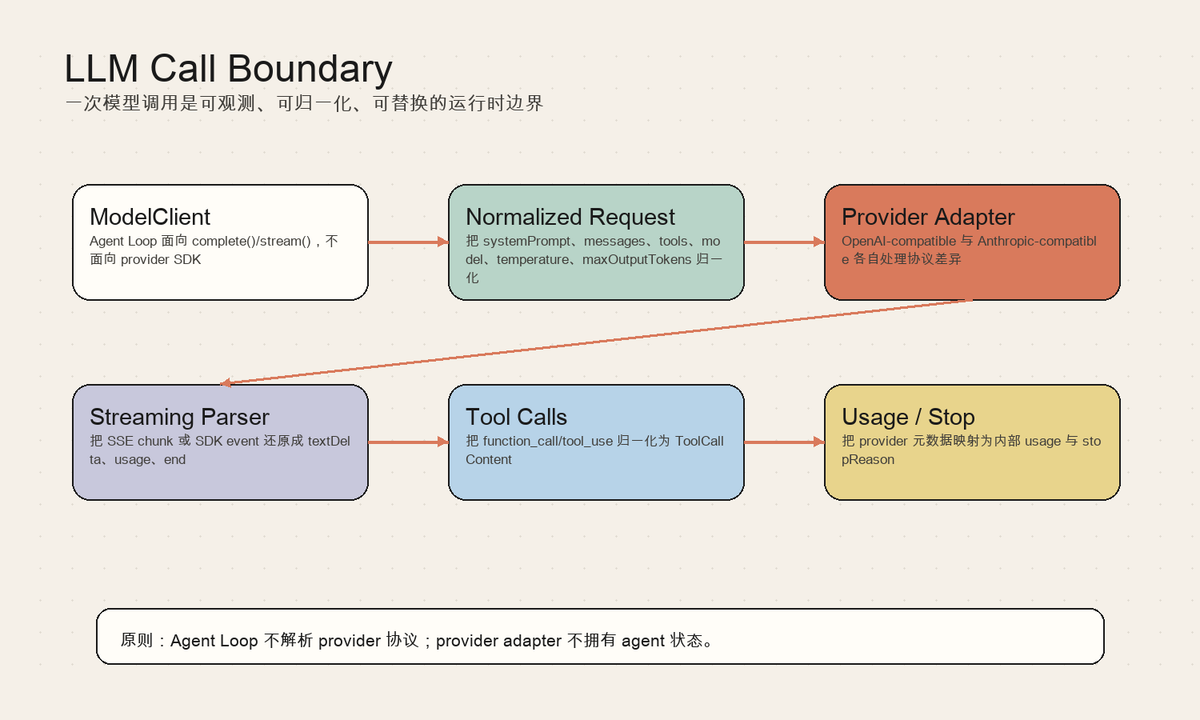
边界
这一层的职责可以拆成几个稳定部分:
- ModelClient:Agent Loop 面向 complete()/stream(),不面向 provider SDK
- Normalized Request:把 systemPrompt、messages、tools、model、temperature、maxOutputTokens 归一化
- Provider Adapter:OpenAI-compatible 与 Anthropic-compatible 各自处理协议差异
- Streaming Parser:把 SSE chunk 或 SDK event 还原成 textDelta、usage、end
- Tool Calls:把 function_call/tool_use 归一化为 ToolCallContent
- Usage / Stop:把 provider 元数据映射为内部 usage 与 stopReason
这一层的边界可以用一个问题检验:如果它的内部实现变化,模型适配、工具执行、状态存储和产品外壳是否都不需要跟着重写?如果答案是否定的,说明这个边界还没有真正收束变化。
代码锚点
本篇主要对应这些模块:
src/ai/types.tssrc/ai/llm-client.tssrc/ai/providers/openai-compatible.tssrc/ai/providers/anthropic-compatible.tssrc/cli/model-from-env.ts
阅读代码时建议先看类型,再看运行路径。
类型定义告诉你这一层暴露什么 contract;运行路径告诉你这个 contract 在 Agent 执行中何时被消费、何时被写回、何时被产品层看见。
运行流程
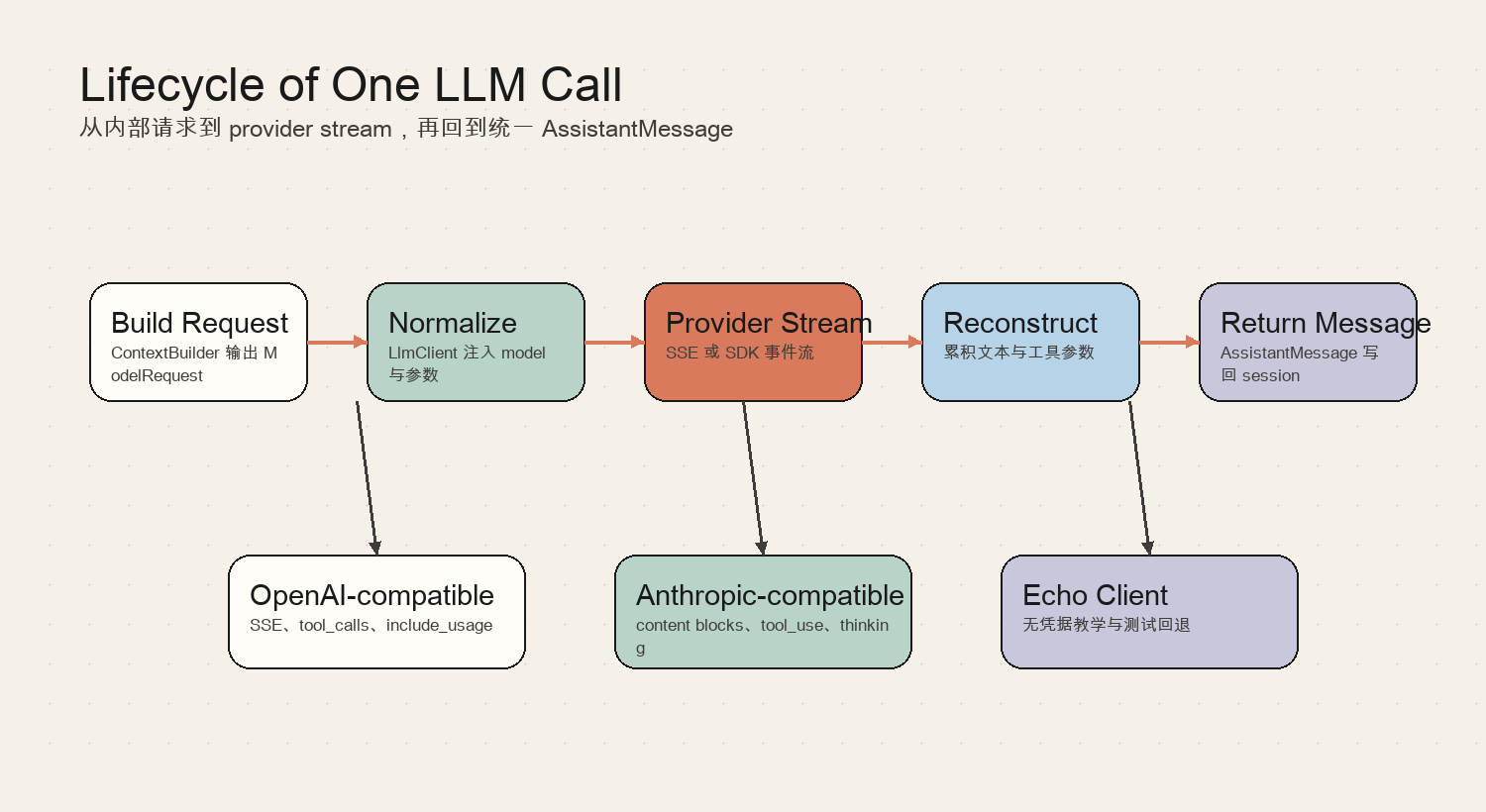
一次典型执行可以概括为:
- Build Request:ContextBuilder 输出 ModelRequest
- Normalize:LlmClient 注入 model 与参数
- Provider Stream:SSE 或 SDK 事件流
- Reconstruct:累积文本与工具参数
- Return Message:AssistantMessage 写回 session
- OpenAI-compatible:SSE、tool_calls、include_usage
- Anthropic-compatible:content blocks、tool_use、thinking
- Echo Client:无凭据教学与测试回退
这里最容易被忽略的是“中间态”。生产级 Agent 不是只关心最终答案;它还要在运行过程中展示进度、捕获错误、记录 usage、允许取消,并把可恢复状态写回 session。
读者抓手:provider 差异应该停在哪里
| 差异 | 如果进入 Agent Loop | 如果停在 LLM Call 边界 |
|---|---|---|
| OpenAI-compatible SSE chunk | loop 需要理解 choices[].delta |
adapter 输出统一的 text/tool/usage event |
| Anthropic content block | loop 需要理解 tool_use / tool_result |
adapter 输出统一的 assistant message |
| usage 上报时机 | UI、日志、状态各写一套兼容逻辑 | LLM Call 统一记录 usage event |
| stop reason | 每个 provider 一套停止条件 | loop 只判断 normalized stop reason |
| 工具参数增量 | tool runtime 被迫处理 provider chunk | LLM Call 先还原成稳定 ToolCall |
判断这一层是否设计正确,可以看一个问题:换模型 provider 时,Agent Loop 是否需要改。如果需要,模型边界还不够干净。
可迁移伪实现:模型调用边界
下面的伪代码是机制抽象,不对应真实 API 或文件结构。它只用来说明这一层的控制点:
async function callModel(request: ModelRequest) {
const normalized = normalize(request, config);
for await (const event of provider.stream(normalized)) {
if (event.type === "textDelta") yield message_update(event.text);
if (event.type === "usage") recordUsage(event.usage);
}
return reconstructAssistantMessage();
}
这个草图的价值在于说明控制点,而不是提供可复制的库代码。
真正的工程实现还要处理错误、取消、并发、token 预算、日志、权限、序列化和 provider 差异。
工程原则
将这一层从 Agent 系统中拆出来,通常带来四个直接收益。
第一,可替换。
外部系统、模型 provider、工具集合或产品外壳变化时,核心运行时不必整体重写。
第二,可观测。
边界清晰后,事件、trace、usage、错误和状态迁移都有稳定落点。
第三,可恢复。
只要状态写入 session,运行时就可以在进程重启、工具失败或长任务中断后继续推理。
第四,可治理。
权限、脱敏、审批、路径保护和执行策略可以放在稳定 hook 或 runtime boundary 上,而不是只靠 prompt 约束。
和 Agent Harness 的关系
Agent = Model + Harness 这个公式的重点,不是把模型之外的所有东西都称为“工程杂活”。
相反,它提示我们:模型之外存在一套必须被设计的运行时系统。
LLM Call 就是这套系统中的一个切面。它不替代模型能力,也不替代产品体验;它让模型能力可以被组织成可执行、可观察、可恢复、可治理的任务流程。
小结
LLM Call 的核心价值,是把一类容易扩散的复杂性收束到明确边界中。
在 mini-agent-harness 中,这个边界被刻意写得较小,方便阅读和教学。但它对应的问题并不小:只要一个 Agent 要长期运行、调用工具、管理上下文、支持 UI、保存状态并处理失败,这个边界就会出现。
下一步可以继续沿着系列计划,把这些边界组合成完整 Agent Harness:模型边界、工具边界、状态边界、上下文边界、扩展边界和产品外壳边界。
参考资料
- OpenAI Agents / Responses API 文档:用于理解现代模型调用、工具调用和结构化响应的运行时边界。
- Anthropic Claude Messages / Tool Use / Agent Skills 文档:用于理解 content blocks、tool_use/tool_result、stop reason、Skills 与长任务上下文管理。
- Model Context Protocol Specification:用于理解工具、资源和 prompts 的连接层边界。
- Martin Fowler, “Agent = Model + Harness”:用于理解模型之外的 harness 概念。