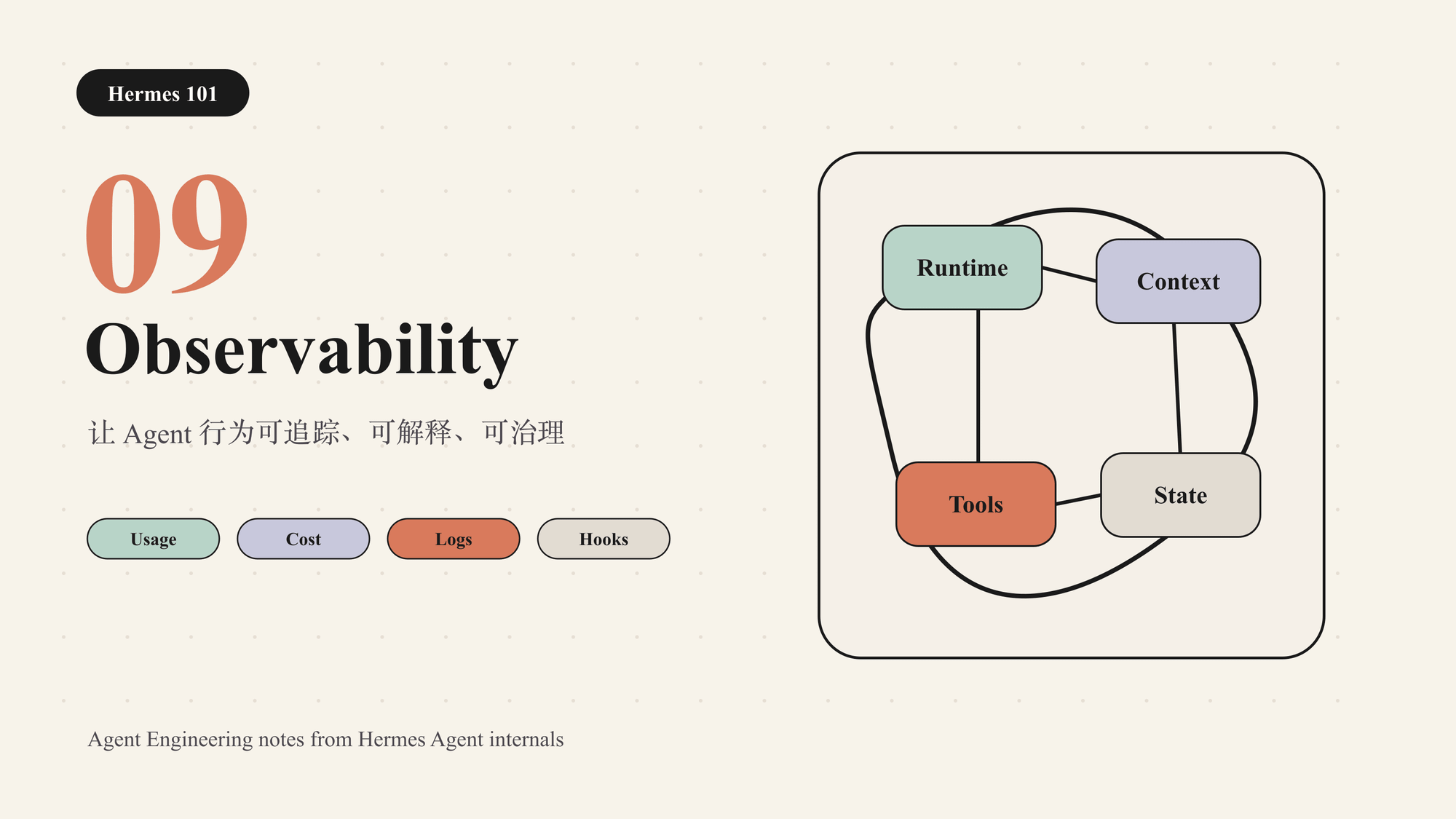
Agent 系统的可观测性很容易被低估。最小 demo 里,只要终端能打印模型输出,看起来就“可调试”。但一旦 Agent 开始调用工具、跨平台运行、长时间执行、委托子 Agent、上传图片、发布文章或修改外部系统,普通聊天记录就不够了。
Observability 要解决的问题是:当 Agent 做错、做慢、花费异常、上下文丢失或工具失败时,系统能不能解释发生了什么。
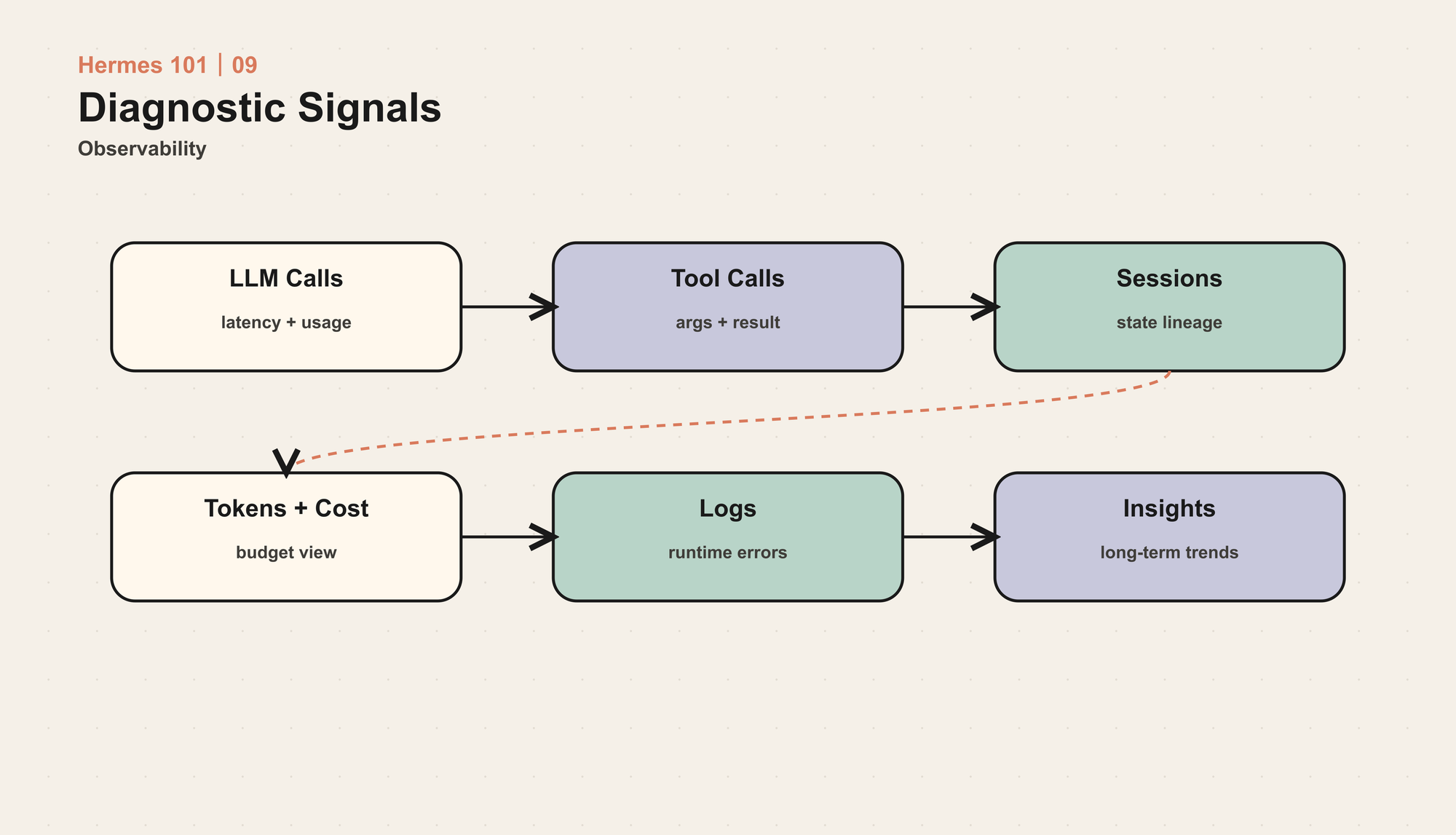
读完本文,你应该能回答
- 为什么 Agent 需要可观测性,而不只是日志?
- token、成本、工具调用、session、错误和平台事件分别应该如何记录?
- /usage、/insights、hooks 和 debug report 解决什么问题?
- mini-agent-harness 如何让一次失败变得可诊断?
本篇在系列中的位置
前几篇讨论能力如何执行,本篇讨论执行如何被看见。它是后面 Memory、Gateway、Cron、Delegation 等长期运行能力的运维底座。
贯穿案例
贯穿这个系列,可以一直带着同一个任务来读:用户说“帮我修复这个 repo 里的 failing tests”。不同章节会回答同一个任务在运行时的不同问题:入口怎样进入、上下文怎样准备、模型怎样决定下一步、工具怎样执行、状态怎样保存、失败后怎样恢复。
定义
Agent Observability 是对模型调用、工具调用、会话状态、token 与成本、平台消息、错误日志和生命周期事件的记录、聚合与诊断能力。
它和传统应用监控不同。传统服务多半有明确入口、请求、数据库和响应。Agent 的执行路径更动态:模型每轮可能选择不同工具;工具结果又进入下一轮推理;用户可以中断、恢复、分支;同一任务可能跨 CLI、Telegram、cron 和子 Agent。
因此 Agent 的 observability 必须同时覆盖 推理层 和 行动层。
Hermes 记录什么
Hermes 的可观测性从 SessionDB 开始。session 不只是历史消息;它还记录来源平台、模型、时间、父子关系、token 计数、成本估算、工具调用和消息索引。
这让系统能回答几类问题:
- 最近哪些 session 最活跃;
- 哪些模型和平台消耗最多 token;
- 哪些工具被调用最频繁;
- 某个任务为何触发压缩;
- 某次工具调用返回了什么错误;
- 当前 session 是否是压缩 continuation 或 branch;
- 成本是可估算、已知价格、订阅包含,还是未知。
在运行时,Hermes 会从 provider usage 中提取 canonical usage,包括 input、output、cache read/write、reasoning tokens 等字段。再结合模型价格表或 provider 信息,估算每次调用成本,并写回 session 数据。
一次失败应该怎样定位
把 failing tests 的例子放进来,Observability 至少要帮读者回答四个问题。
| 现象 | 需要看的信号 | 可能问题 | 下一步 |
|---|---|---|---|
| 模型一直绕圈 | turn 数、tool call 序列、相似计划重复 | Agent Loop 缺少终止或反思条件 | 限制轮数,要求总结已验证事实 |
| 工具调用失败 | tool error、stderr、权限记录 | Tool Runtime、权限或环境问题 | 检查命令、cwd、env、审批状态 |
| 回答忽略了项目规则 | system prompt、项目上下文注入记录 | Context Builder 缺失或顺序错误 | 检查 AGENTS/CLAUDE 加载路径 |
| 成本突然升高 | token 曲线、压缩触发点 | 历史过长或工具结果未裁剪 | 启用 compaction,裁剪大结果 |
| 平台回复错位置 | session key、delivery target、gateway event | Gateway session 映射错误 | 检查 adapter 和 runner 日志 |
没有这些信号,Agent 失败只会表现成“模型不行”。有了这些信号,问题才会被拆成模型、上下文、工具、权限、平台和运行时几个可处理的部分。
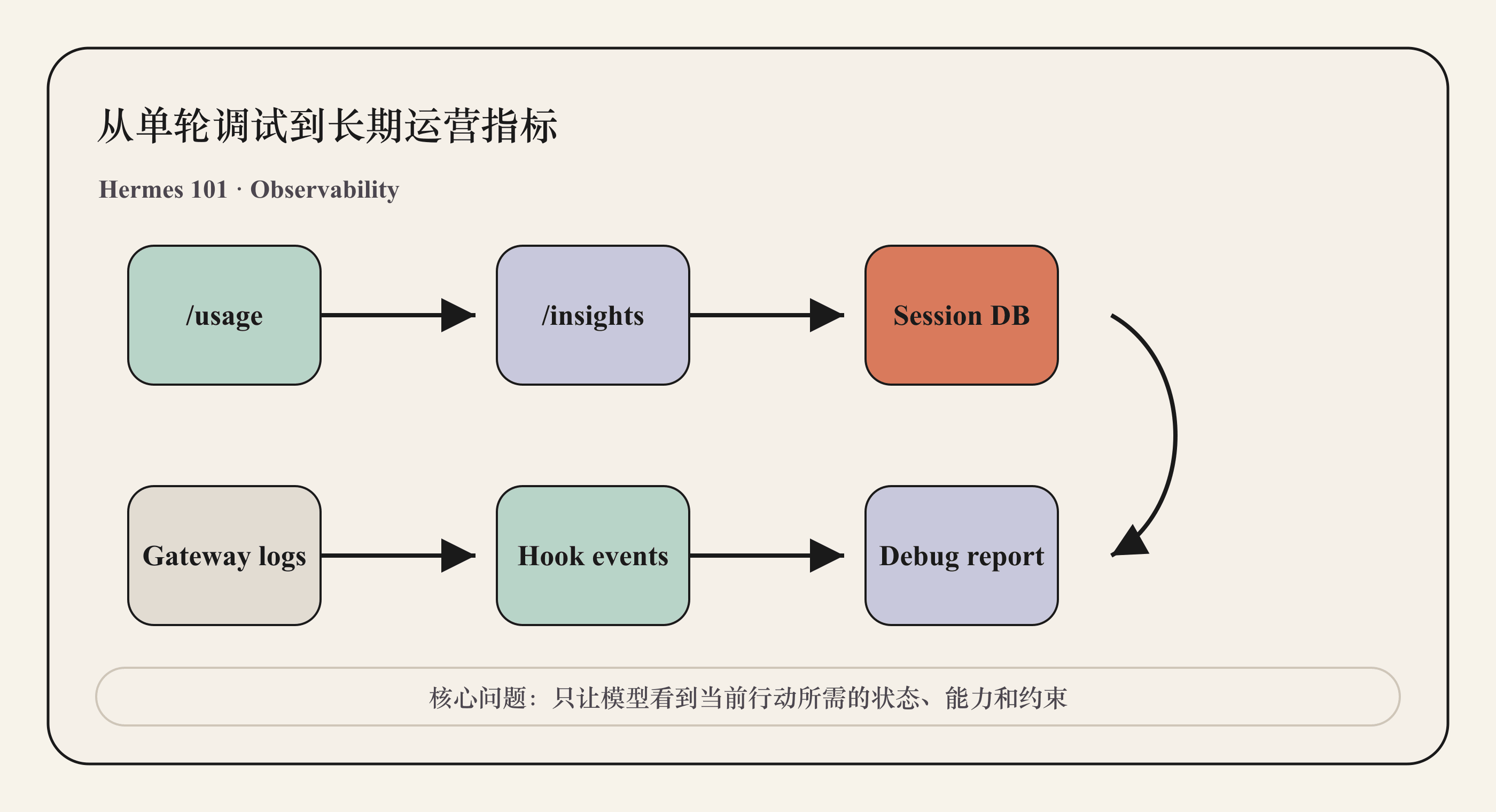
/usage 和 /insights
/usage 面向当前 session。它帮助用户理解这次会话已经用了多少消息、API call、token、reasoning tokens、缓存 token 和估算成本。它更像“当前任务仪表盘”。
/insights 面向历史数据。它从 SQLite session store 聚合过去若干天的会话,生成 token 消耗、成本估算、模型分布、平台分布、工具使用、技能使用和活动趋势。它回答的是运营问题:这个 Agent 在一段时间内到底怎样被使用。
一个简化的 insights 计算可以这样理解:
可迁移伪实现:Insights
下面的伪代码是机制抽象,不对应 Hermes 的真实 API 或文件结构。
type SessionUsage = {
sessionId: string
source: string
model: string
inputTokens: number
outputTokens: number
cacheReadTokens: number
cacheWriteTokens: number
reasoningTokens: number
estimatedCostUsd?: number
toolCalls: Record<string, number>
}
function generateInsights(sessions: SessionUsage[]) {
return {
overview: aggregateTokensAndCost(sessions),
models: groupByModel(sessions),
platforms: groupBySource(sessions),
tools: aggregateToolCalls(sessions),
activity: bucketByDay(sessions)
}
}
这里的关键不在报表格式,而在数据模型:如果 session 层没有结构化记录,后面只能从聊天文本里猜。
Logs、hooks 和 debug report
Observability 不能只依赖数据库字段。运行时错误、gateway 连接、平台投递失败、插件异常、MCP server 崩溃,都需要日志。
Hermes 提供 hermes logs 查看 agent、gateway 和错误日志;hermes debug 可以收集系统信息、近期日志和配置状态并生成调试报告。对跨平台 Agent 来说,这类诊断工具很重要,因为问题可能发生在模型 API、工具运行、消息平台、网络、权限或本地依赖任一层。
Hooks 则提供了可扩展的观测入口。Gateway hooks 可以监听 agent:start、agent:step、agent:end、session:start 等事件;plugin hooks 可以监听 pre_tool_call、post_tool_call、pre_llm_call 等事件。用户或团队可以把这些事件写入日志系统、发送到 webhook,或者用于长任务告警。
为什么 Agent 更难观测
Agent 的难点在于因果链很长。
一次失败可能不是模型“答错了”,而是:Context Builder 暴露了过期项目规则;工具 schema 让模型误以为某个能力可用;工具结果被截断,模型缺少错误细节;压缩摘要丢了关键约束;gateway session 恢复到了错误分支;插件 hook 修改了上下文;provider 返回的 usage 字段不完整。
如果系统只保存最终回答,就无法定位这些问题。
所以 Agent observability 至少要保留四条线索。
第一是 输入线索:本轮模型看到了什么系统提示、消息尾部、工具 schema 和检索内容。
第二是 行动线索:模型请求了哪些工具,参数是什么,工具返回什么,是否被审批、阻止或重试。
第三是 状态线索:session id、父子关系、压缩次数、当前模型、平台来源、成本和 token。
第四是 外部线索:gateway 日志、插件日志、MCP server 状态、网络错误和平台投递结果。
治理意义
Observability 也是治理层。企业或团队使用 Agent 时,不只关心它能不能完成任务,还关心它如何使用工具、是否访问了敏感系统、成本是否可控、错误是否可复现、谁触发了某次操作。
Hermes 的设计没有把 observability 放在最后当报表功能,而是让 session storage、usage tracking、hooks、logs、debug report 和 insights 共同构成诊断面。
小结
Agent 不是黑盒聊天窗口,而是一个会调用模型、执行工具、修改外部世界的运行系统。Observability 的目标,是让这个系统的推理、行动、状态和成本都能被追踪。没有可观测性,Agent 的成功不可复用,失败也不可解释。