Memory 很容易被误解成“把更多聊天记录塞进上下文”。这不是 Hermes 的设计。真正的 Memory 是跨 session 仍然有价值的事实层:用户偏好、项目约定、环境细节、工具坑、长期稳定的工作方式。它不应该保存一次性进度,也不应该变成第二份聊天日志。
Memory 的目标,是让 Agent 在新会话里不从零开始,同时不破坏当前会话的上下文稳定性。
读完本文,你应该能回答
- Memory 为什么不是无限上下文?
- 哪些事实值得跨 session 保存,哪些只应该留在当前会话?
- Frozen Snapshot 怎样避免记忆在执行中漂移?
- mini-agent-harness 如何设计记忆的写入、召回和治理?
本篇在系列中的位置
Context 和 Compaction 解决当前 session 内的信息压力,本篇进入跨 session 的长期事实层。下一篇 Gateway 会展示这些长期状态如何跨平台接续。
贯穿案例
贯穿这个系列,可以一直带着同一个任务来读:用户说“帮我修复这个 repo 里的 failing tests”。不同章节会回答同一个任务在运行时的不同问题:入口怎样进入、上下文怎样准备、模型怎样决定下一步、工具怎样执行、状态怎样保存、失败后怎样恢复。
定义
Agent Memory 是 session 之外的长期事实存储。它把未来仍然有用的信息持久化,并在合适的边界重新注入运行时。
Hermes 有两层 memory。第一层是内置 Persistent Memory:MEMORY.md 保存 Agent 自己的笔记,USER.md 保存用户画像。它们在 session 启动时加载,渲染进 system prompt。第二层是外部 Memory Provider,例如 Honcho、Mem0、Supermemory 等,用于语义召回、用户建模或外部知识管理。
这两层不是替代关系。内置层负责小而精、一定要进入 prompt 的事实;外部 Provider 负责更大规模的检索与建模。
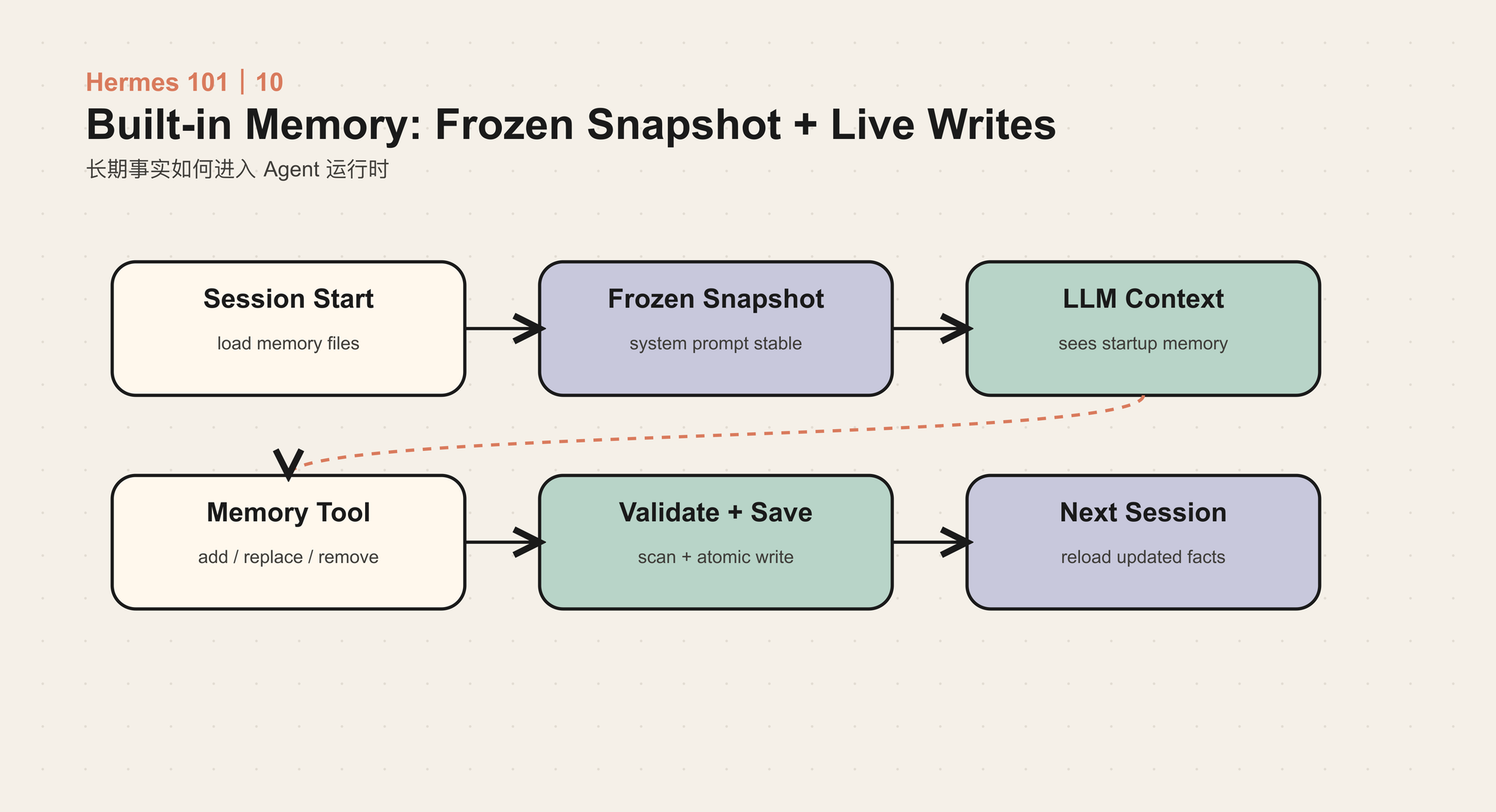
Frozen Snapshot
Hermes 的一个关键取舍是:memory 写入会立即落盘,但当前 session 的 system prompt 不会动态改变。
原因很简单。Agent 运行中如果不断修改 system prompt,会破坏 prompt cache,也会让模型在同一任务里看到前后不一致的规则。Hermes 因此区分两份状态:
- frozen snapshot:session 启动时注入上下文的 memory;
- live state:工具写入后已经落盘、下个 session 会看到的 memory。
这让 memory 同时具备持久性和运行时稳定性。
Should / Should Not Remember
Memory 的关键不是“能记多少”,而是“什么值得跨 session 影响未来行为”。
| 内容 | 是否应该进入 Memory | 理由 |
|---|---|---|
| 用户长期偏好“用中文回答” | 应该 | 会反复影响未来交互 |
| 项目固定测试命令 | 可以 | 如果长期稳定,能减少重复询问 |
| 本次 failing tests 的临时错误栈 | 不应该 | 属于当前 session,不应污染未来任务 |
| 某个 Skill 的适用坑点 | 不应该进 Memory | 应该写进 Skill,而不是事实记忆 |
| API key、credential path、secret | 不应该 | 隐私和安全风险 |
| “今天已经发布了第 10 篇” | 不应该 | 这是任务进度,不是长期事实 |
一个简单原则是:Memory 应该保存未来仍然成立的事实,而不是保存“我刚刚做了什么”。后者应该留在 session、日志或发布记录里。
Memory Tool 的边界
Hermes 的 memory tool 只做三件事:add、replace、remove。没有 read action,因为 memory 已经在 session 开始时进入上下文。
写入 memory 前,系统会做内容校验:不能为空、不能超出容量限制,也要过滤明显的 prompt injection、凭证窃取、后门指令和不可见字符。原因很直接:memory 未来会进入 system prompt,它的安全等级高于普通聊天消息。
外部 Provider
外部 Provider 不直接改写 system prompt。Hermes 会在每轮开始时调用 provider 的 prefetch,根据当前用户消息召回相关内容,再把结果包进受控的 <memory-context> 区块,追加到当前用户消息里。
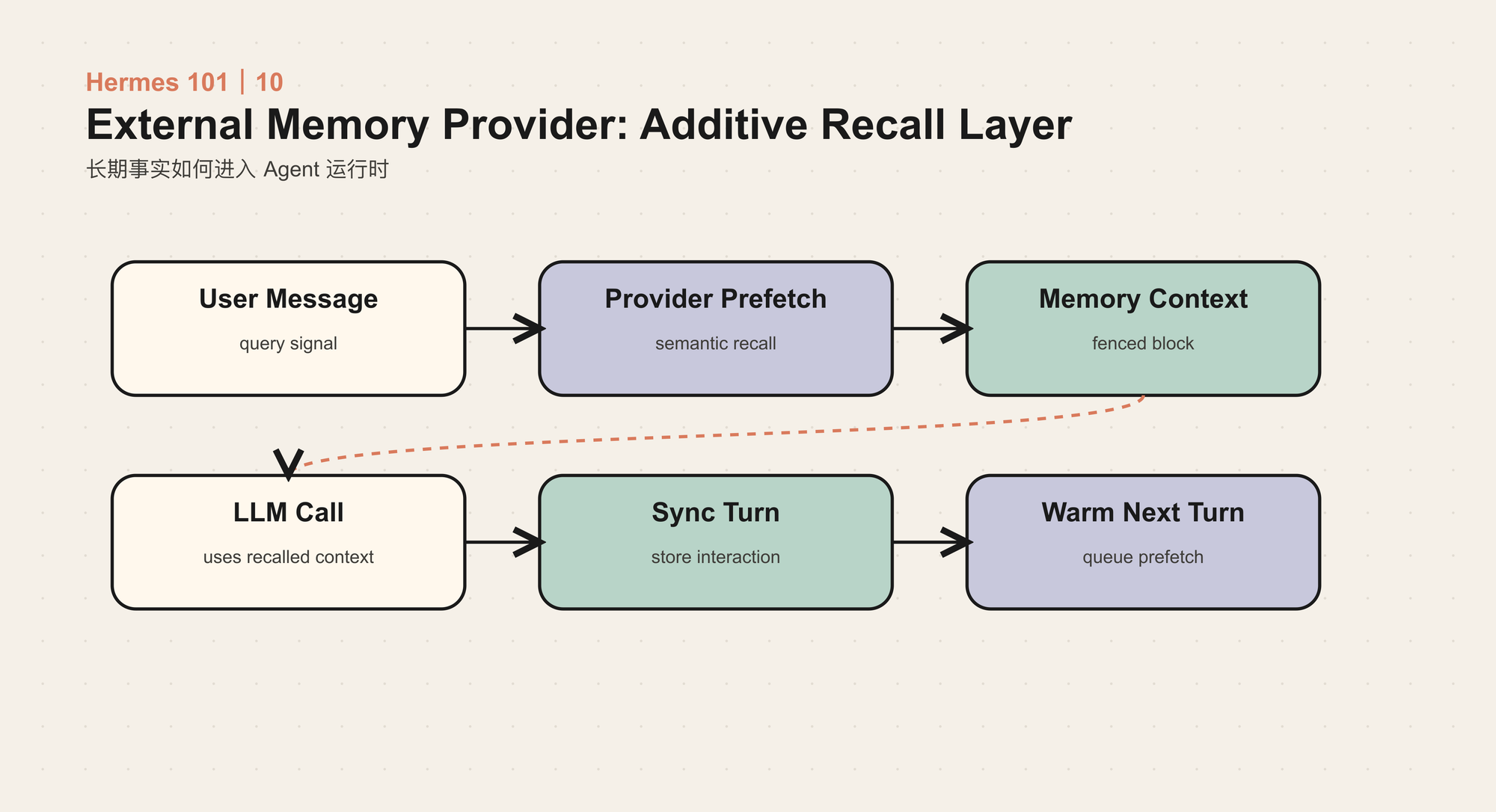
这样做有两个好处:第一,system prompt 仍然稳定;第二,召回内容被明确标记为“参考上下文”,不是新的用户指令。
可迁移伪实现:Memory
下面的伪代码是机制抽象,不对应 Hermes 的真实 API 或文件结构。学习框架不需要一开始接入复杂的向量库。最小版本只要实现五件事:
type MemoryTarget = "memory" | "user"
class MiniMemoryStore {
live: Record<MemoryTarget, string[]>
snapshot: Record<MemoryTarget, string>
load() {
this.live.memory = readEntries("MEMORY.md")
this.live.user = readEntries("USER.md")
this.snapshot.memory = render(this.live.memory)
this.snapshot.user = render(this.live.user)
}
systemPromptBlock() {
return [this.snapshot.memory, this.snapshot.user].filter(Boolean).join("\n\n")
}
add(target: MemoryTarget, content: string) {
validate(content)
this.live[target].push(content)
atomicWrite(target, this.live[target])
return this.live[target]
}
}
重点不是文件格式,而是 snapshot 语义:当前 session 看到的是启动时的 memory;工具写入影响下一个 session。
小结
Memory 不是无限上下文,而是长期事实治理。Hermes 的实现强调三点:小而精的内置记忆、稳定的 frozen snapshot、可插拔的外部召回层。理解这一层,才知道 Agent 为什么可以跨 session 变得更贴合用户,而不是只会复读最近几轮聊天。
参考资料
- Hermes Agent Documentation: https://hermes-agent.nousresearch.com/docs
- Hermes Agent GitHub: https://github.com/NousResearch/hermes-agent