核心结论
Agent 产品的 Reliability,不是承诺“Agent 永远正确”,而是承诺:即使 Agent 出错、工具失败、权限不足、用户中断、外部系统异常,产品仍然能限制损失、保留状态、给出恢复路径,并让用户最终验收结果。
对产品经理来说,可靠性不是一个工程质量词,而是一组明确的产品设计问题:
- 失败会影响多大范围?
- 用户什么时候能发现偏离?
- 已完成的部分能不能保留?
- 错误动作能不能撤销?
- 任务能不能重试或交给人?
- 最终结果如何确认真的可用?
Agent 越像“替用户做事的人”,可靠性就越不能只依赖模型能力。一个成熟产品必须假设失败一定会发生,然后把失败做成可管理、可恢复、可学习的正常路径。
读者收益
读完这一章,你应该能判断:
- 一个 Agent 产品的失败是否被控制在合理边界内。
- 哪些任务可以自动重试,哪些任务必须停下来等人。
- 如何把 checkpoint、rollback、retry、fallback、acceptance check 变成 PM 能评审的产品机制。
- 为什么提高自主等级之前,必须先补齐可靠性能力。
Agent 为什么天然更容易“不可靠”
传统软件的不可靠,通常来自系统 bug、网络错误、数据异常或用户误操作。Agent 产品还会多出几类风险:
| 风险来源 | 表现 | PM 需要设计什么 |
|---|---|---|
| 意图理解偏差 | Agent 做了用户没想要的事 | 澄清、计划确认、范围限制 |
| 上下文缺失 | 漏读文件、漏看记录、引用过期信息 | 上下文来源展示、缺口提示 |
| 工具调用失败 | API 报错、命令失败、外部系统超时 | 重试、降级、错误分类 |
| 中间状态漂移 | 做着做着偏离目标 | 里程碑检查、用户接管 |
| 外部副作用 | 发错邮件、改错记录、部署错误版本 | 审批、回滚、审计 |
| 验收不完整 | Agent 说完成,但结果不可用 | acceptance checks、测试、preview |
这意味着 Agent Reliability 的核心不是“少失败”,而是“失败后产品仍然站得住”。
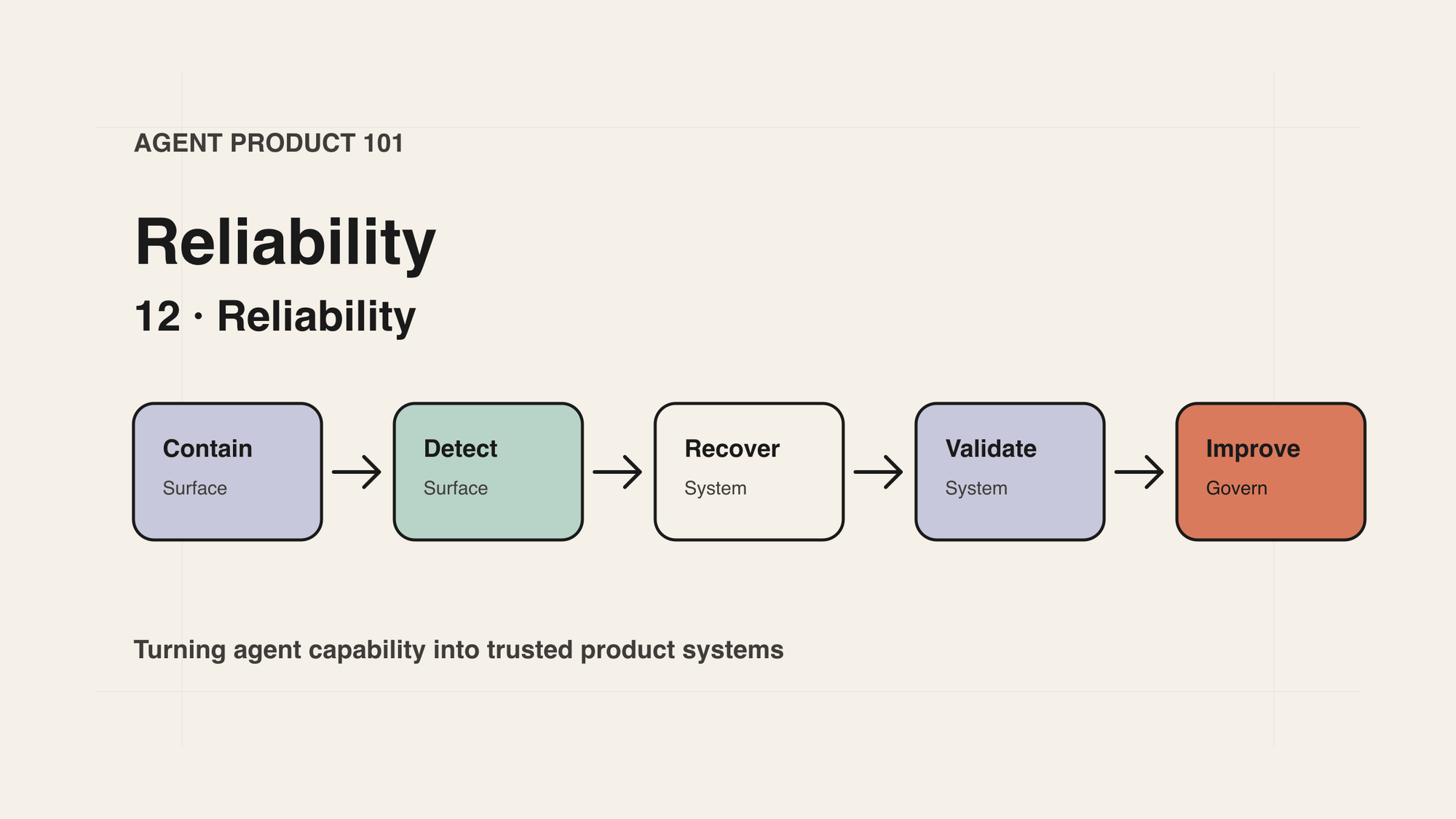
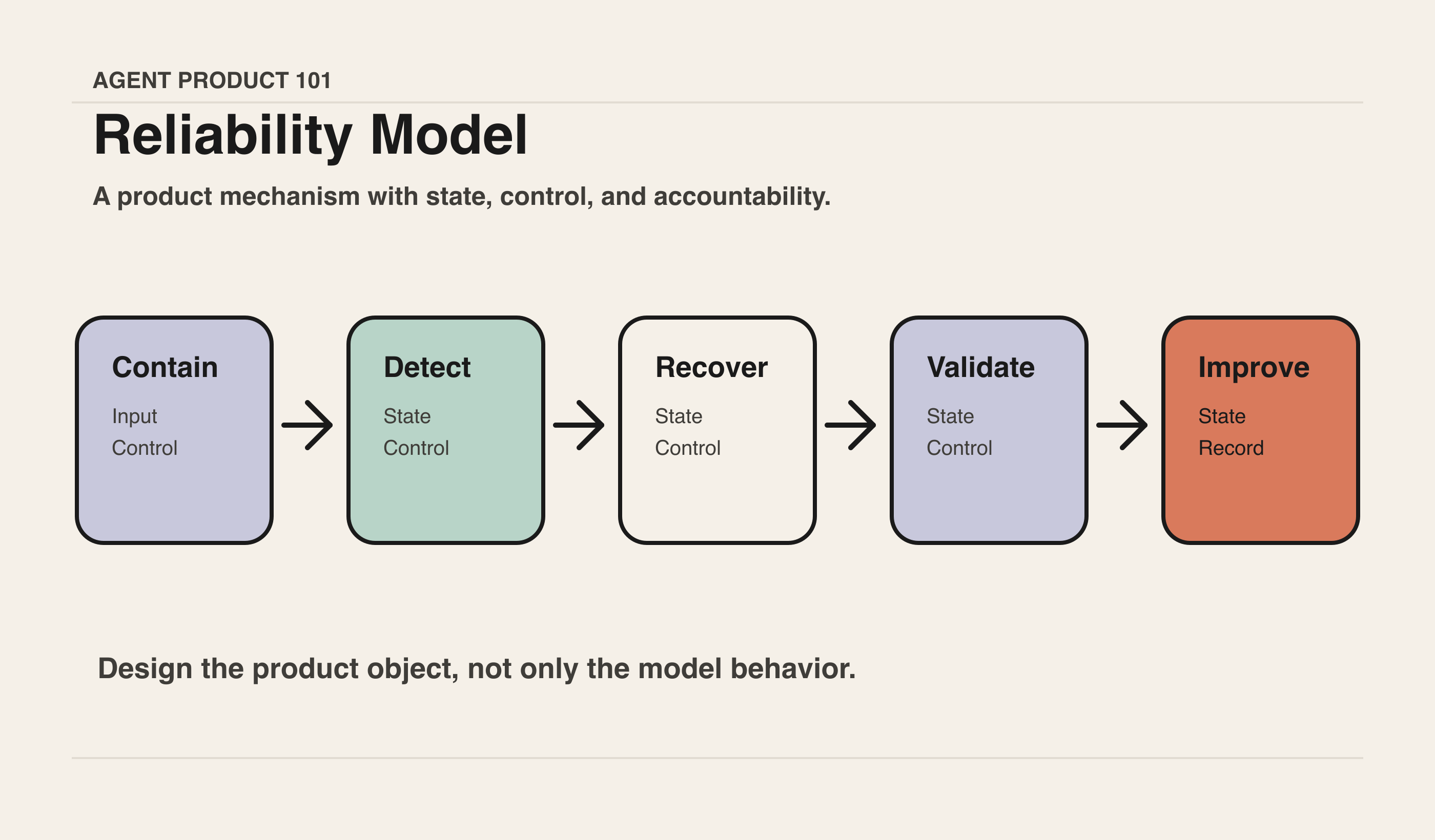
一个 PM 可用的可靠性模型
可以把可靠性拆成五个产品层。
1. 限制影响范围:先控制 blast radius
在 Agent 还不够稳定时,最重要的不是让它做更多,而是限制它一次能造成多大影响。
常见的产品手段包括:
- 默认在 sandbox、draft、branch、preview、staging 环境中执行。
- 对外部系统写入设置权限边界。
- 对批量动作设置数量上限。
- 对高风险动作要求人类确认。
- 对长任务设置最大时长和超时状态。
- 对不确定任务要求先生成计划或草稿。
产品判断:如果一个动作不可逆、影响外部用户、涉及钱或生产数据,就不应该直接自动执行。
2. 保留中间状态:不要让用户从头再来
Agent 任务常常是多步任务。失败时,用户最痛苦的不是“它错了”,而是“我必须重新解释、重新开始、重新等待”。
可靠产品应该保留:
- 用户原始目标。
- Agent 当前计划。
- 已完成步骤。
- 生成的草稿、diff、preview、报告。
- 工具调用结果。
- 失败原因。
- 下一步可选路径。
这就是 checkpoint 的产品价值:让失败不是归零,而是回到一个可理解的中间点。
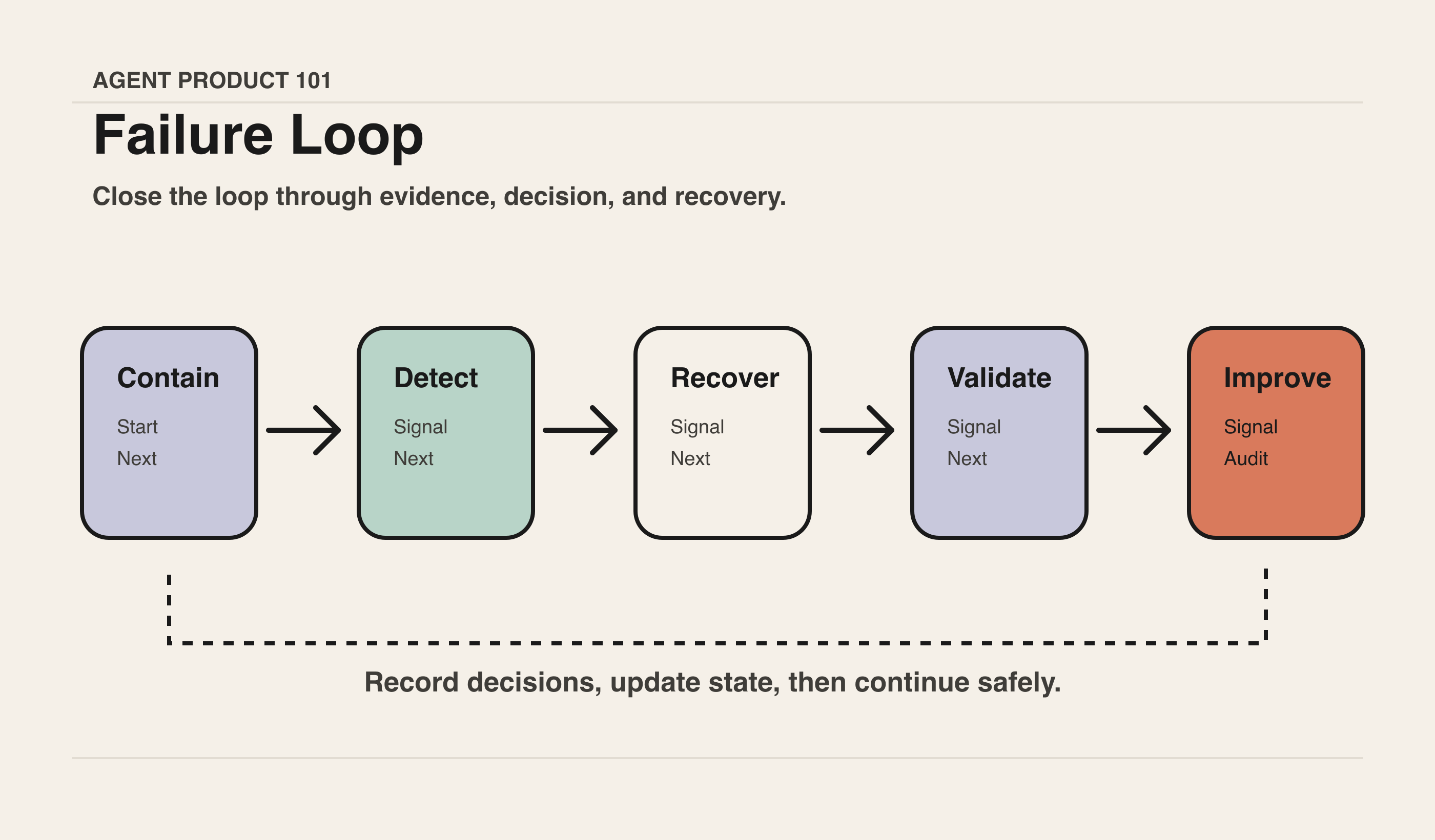
3. 分类失败:不同失败需要不同恢复路径
不要把所有失败都显示成“Something went wrong”。PM 至少要区分:
| 失败类型 | 用户看到什么 | 推荐恢复路径 |
|---|---|---|
| 信息不足 | 需要补充哪些输入 | 询问用户、提供选项 |
| 权限不足 | 缺少哪个权限,为什么需要 | 请求授权、换低风险路径 |
| 工具失败 | 哪个工具失败,是否临时问题 | 自动重试、稍后再试、切换工具 |
| 结果不合格 | 哪个验收项没通过 | 继续修复、回滚到 checkpoint |
| 风险升高 | 当前动作超出原授权 | 降低自主度、请求审批 |
| 外部系统拒绝 | 对方系统返回什么限制 | 修改输入、交给人处理 |
失败分类越清楚,产品越能给出“下一步”,而不是把用户困在错误信息里。
4. 设计恢复动作:retry、rollback、handoff、stop
可靠性不是只有自动重试。不同场景需要不同恢复方式:
| 恢复动作 | 适合场景 | 不适合场景 |
|---|---|---|
| Retry 重试 | 临时网络、外部服务超时、可幂等动作 | 已经产生不可逆副作用 |
| Rollback 回滚 | 文件修改、版本变更、草稿更新、配置变更 | 已发送邮件、已完成付款 |
| Handoff 接管 | 低置信度、高风险、权限冲突、用户偏好不明确 | 简单可自动修复错误 |
| Ask 澄清 | 目标模糊、信息缺失、选择依赖用户判断 | 系统内部故障 |
| Stop 停止 | 风险超出授权、重复失败、无法验证结果 | 仍有安全低风险路径 |
PM 的任务是把这些恢复动作设计成用户能理解的选项,而不是后台策略。
5. 验收结果:不要让“完成”只由 Agent 自己宣布
Agent 说完成,只是一个信号,不是验收。
不同产品需要不同验收机制:
| 产品类型 | 验收方式 |
|---|---|
| Coding Agent | 测试通过、diff 可审查、PR 可 review |
| App Builder | preview 可运行、关键路径可点击、可回滚 |
| Workflow Agent | ticket 状态正确、审批记录完整、通知送达 |
| CRM Agent | 字段变更正确、数据来源可追溯、权限合规 |
| Research Agent | 引用可信、覆盖范围明确、结论与证据匹配 |
没有验收机制,可靠性就只剩模型自信。
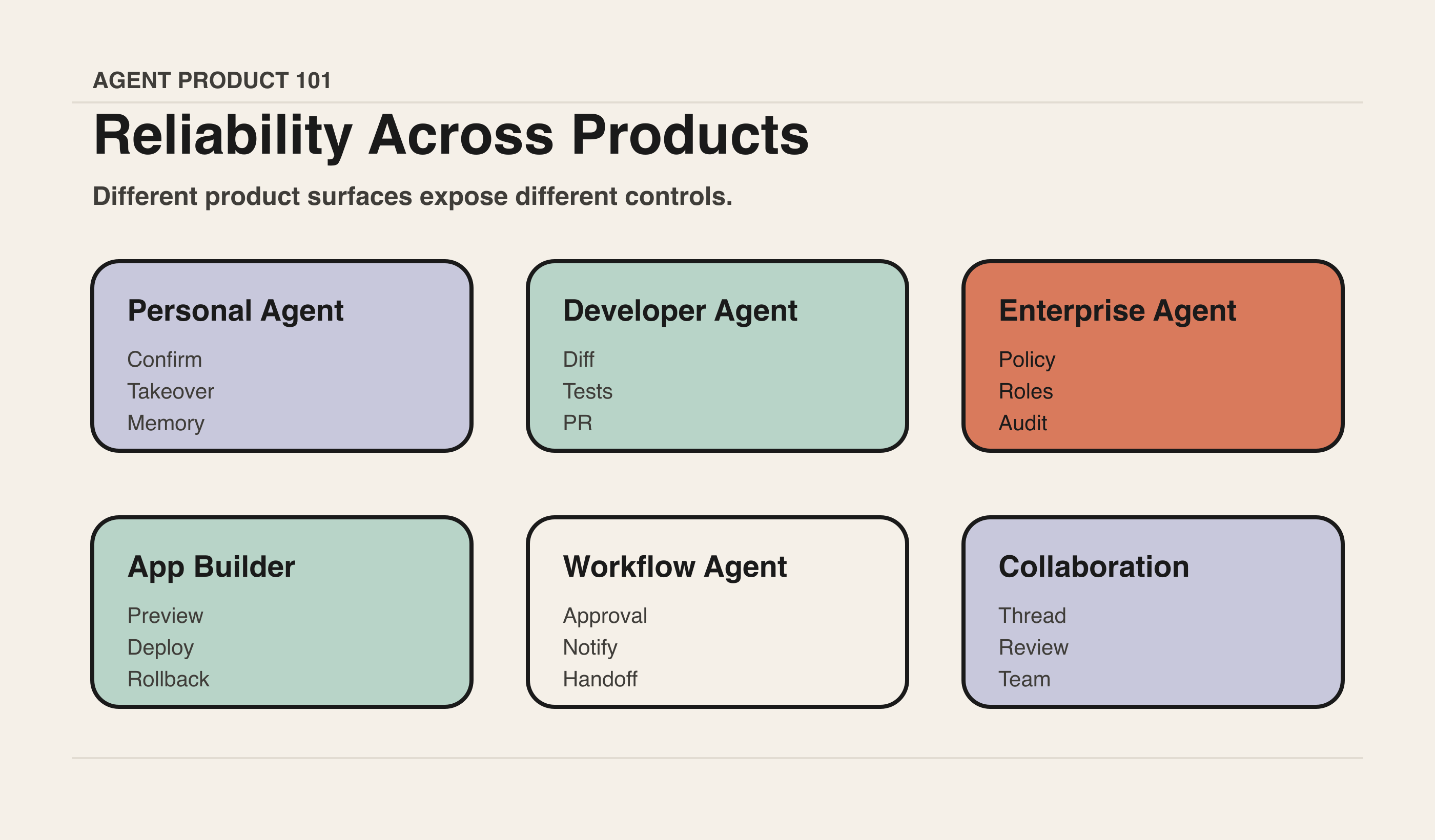
从真实产品看 Reliability
Replit Agent:checkpoint 和 rollback 是 App Builder 的安全感
Replit Agent 这类产品让用户从自然语言走到可运行应用。过程中一定会出现生成不符合预期、改坏已有功能、预览失败等情况。checkpoint、preview、日志和 rollback 让用户敢于尝试,因为错了不是完全失控。
PM 启发:在创造型 Agent 产品里,用户愿意多试几次的前提是恢复成本低。
Claude Code / Cursor:developer agent 的可靠性来自工程护栏
开发者 Agent 可以更大胆,是因为工程工作流天然有 diff、test、git、branch、review、CI 这些护栏。Agent 可以改代码,但用户能看到 diff;Agent 可以跑命令,但过程能记录;Agent 可以提交 PR,但 merge 仍有组织策略。
PM 启发:不要把可靠性都押在模型上,要复用用户所在领域已有的验证和恢复机制。
Codex Cloud / GitHub Copilot coding agent:长任务可靠性来自隔离和交付对象
云端 coding agent 把任务放在隔离环境中执行,输出通常回到 PR、CI、review。即使任务失败,失败也被限制在一个工作单元里,不会直接污染主流程。
PM 启发:可靠性往往不是一个按钮,而是任务容器、执行环境、产物类型和协作流程的组合。
Copilot Studio / Agentforce:企业可靠性来自治理与生命周期
企业 Agent 的失败影响可能触达客户、收入、合规和内部流程。因此可靠性必须包括 identity、connector、policy、approval、audit、monitoring、version、environment、rollback。
PM 启发:企业场景里,“可靠”不是用户感觉顺畅,而是组织能证明风险被管理。
产品判断表:这个任务应该如何提高可靠性
| 任务特征 | 默认策略 | 可靠性机制 |
|---|---|---|
| 低风险、可撤销 | 可以自动执行 | 状态记录、简单重试 |
| 低风险、耗时长 | 后台执行 | 进度、通知、checkpoint |
| 中风险、可审查 | 先产出草稿或 diff | preview、review、acceptance check |
| 高风险、可恢复 | 必须确认后执行 | 审批、回滚、审计 |
| 高风险、不可恢复 | 默认不自动执行 | 人类接管、强确认、策略限制 |
| 外部系统不稳定 | 谨慎自动化 | retry、fallback、超时、降级 |
如果一个任务同时具备“高风险、不可逆、难验证”,就不应该追求高自主度。
设计原则
原则一:先定义失败,再定义成功
很多 Agent 产品只设计 happy path:用户输入任务,Agent 完成任务。但可靠性评审应该先问:
- 如果用户目标不清楚怎么办?
- 如果权限不够怎么办?
- 如果工具返回错误怎么办?
- 如果 Agent 中途偏离怎么办?
- 如果用户不接受结果怎么办?
- 如果外部系统已经被写入怎么办?
能回答这些问题,才说明产品真正准备好了承接任务。
原则二:把恢复路径做成界面,不要只做成后台逻辑
用户应该能看到并选择:
- 回到上一个 checkpoint。
- 保留当前草稿并重新尝试。
- 修改目标后继续。
- 只接受部分结果。
- 交给人工处理。
- 终止任务并导出记录。
恢复路径越清楚,用户越不怕委托。
原则三:高风险动作必须有证据和停顿点
确认不是“你确定吗”。一个有效确认至少要包含:
- 即将执行的动作。
- 影响对象。
- 数据来源或判断依据。
- 预期结果。
- 可撤销性。
- 不执行时的替代路径。
没有证据的确认,只是在把责任转嫁给用户。
原则四:可靠性指标要看任务结果,而不是系统调用成功
API 调用成功不代表任务成功。PM 应关注:
- 任务完成率。
- 用户接受率。
- 结果撤销率。
- 人工接管率。
- 重试后成功率。
- 回滚率。
- 失败原因分布。
- 高风险动作拦截率。
- 从失败到恢复的时间。
这些指标比“调用成功率”更能说明 Agent 产品是否可靠。
常见误区
误区一:把可靠性等同于模型准确率
模型准确率重要,但不是全部。权限、上下文、工具、状态、工作流、验收、恢复都可能决定任务是否成功。
误区二:失败后只给用户道歉
“抱歉,我失败了”不是恢复路径。用户需要知道哪里失败、已完成什么、还能怎么继续。
误区三:无限自动重试
重试不是万能解。对不可幂等、有外部副作用的动作,重复执行可能放大错误。PM 必须定义哪些动作可以安全重试。
误区四:把回滚当成工程细节
回滚是用户信任的一部分。尤其在 app builder、developer agent、workflow agent 中,回滚入口应该是产品体验的一部分。
误区五:为了效率跳过验收
越是自动化,越需要验收。否则团队只是在更快地产生无法接受的结果。
产品检查清单
评审 Agent Reliability 时,可以逐项检查:
- 是否定义了每类任务的最大影响范围?
- 高风险动作是否默认进入草稿、预览、分支或审批?
- 长任务是否有 checkpoint 和可恢复状态?
- 失败是否被分类,而不是统一显示通用错误?
- 每类失败是否有明确下一步:retry、rollback、ask、handoff、stop?
- 哪些动作可安全重试,哪些动作绝不能自动重试?
- 用户能否保留部分成果,而不是失败后清空任务?
- 是否有结果验收机制,而不是 Agent 自己宣布完成?
- 是否记录失败原因、恢复路径、回滚率和用户接受率?
- 提高自主等级之前,可靠性机制是否已经成熟?
小结
Reliability 的本质不是让 Agent 永远正确,而是让产品在 Agent 不正确时仍然可控。
一个可靠的 Agent 产品应该做到:低风险任务自动推进,高风险任务停下来;中间状态可保存,错误结果可回滚;失败原因可理解,恢复路径可执行;最终结果可验证,而不是只听 Agent 自己说完成。
下一篇会进入 Platform:当可靠性机制稳定之后,Agent 才可能从单个功能升级为可创建、可连接、可治理、可运营的平台能力。
参考资料
- https://docs.replit.com/core-concepts/agent/checkpoints-and-rollbacks
- https://docs.anthropic.com/en/docs/claude-code/overview
- https://developers.openai.com/codex/cloud
- https://docs.github.com/actions
- https://cursor.com/docs/agent/overview
- https://learn.microsoft.com/en-us/microsoft-copilot-studio/security-and-governance
- https://www.salesforce.com/agentforce/