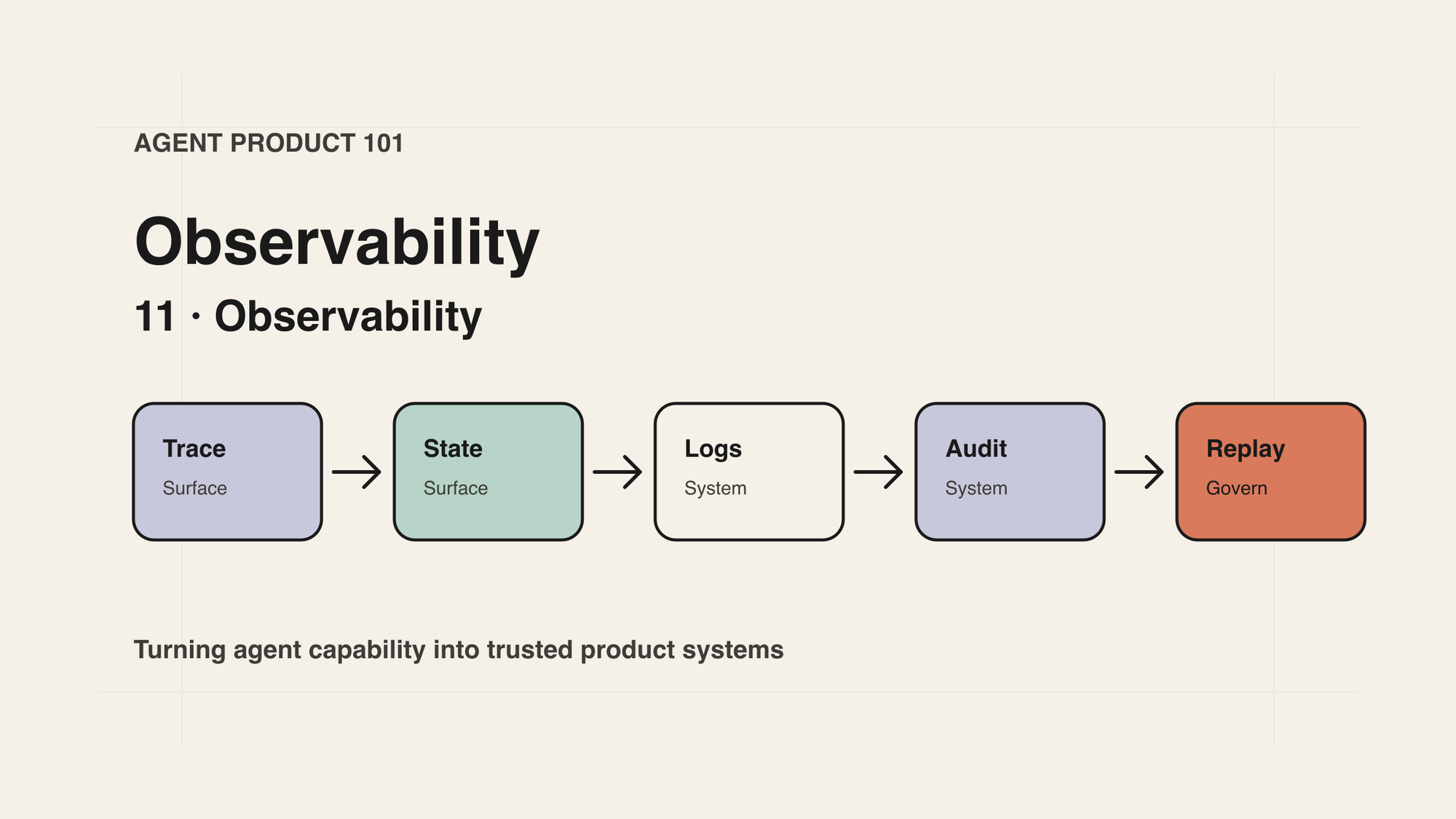
核心结论
Agent 产品的 Observability,不是“后台能不能查日志”,而是产品能不能回答四个问题:
- Agent 想做什么:目标、计划、下一步动作是否可见。
- Agent 做了什么:工具调用、状态变化、人类确认、外部副作用是否可追溯。
- Agent 为什么失败:问题发生在意图、上下文、权限、工具、外部系统,还是用户决策。
- Agent 现在怎么办:能否重试、回滚、接管、升级、继续或终止。
对产品经理来说,可观测性不是工程平台的附属能力,而是 Agent 产品能否被委托、被复盘、被治理、被持续改进的基础。
如果用户只看到“Agent 正在思考”和“已完成”,中间过程完全不可见,那么这个产品其实没有把任务交付给用户,只是把风险藏进了模型和后台系统里。Agent 越能行动,可观测性越不能只是内部日志;它必须变成用户体验、运营后台、企业治理和产品指标的一部分。
读完这一章,你应该获得什么
这一章希望帮助产品经理建立三个判断:
- 什么时候需要把 Agent 的过程展示给用户,什么时候只需要展示结果。
- 如何把 trace、状态、证据、审批和审计变成产品对象,而不是散落在日志里。
- 如何用可观测性改进指标、评估、可靠性和企业治理。
一句话:Observability 的目标不是“看得越多越好”,而是让不同角色在正确时机看到足够的信息,并能据此做出下一步决策。
为什么 Agent 产品比传统软件更需要可观测性
传统软件的流程通常由产品提前定义。用户点击一个按钮,系统执行一个确定动作,失败也大多有明确错误码。
Agent 产品不同。它会在任务过程中做计划、选工具、读取上下文、修改行动路径、等待人类输入、处理外部系统返回,并可能产生真实副作用。也就是说,Agent 的“执行过程”本身就是产品的一部分。
这带来三个变化:
| 变化 | 传统软件 | Agent 产品 | PM 需要补上的设计 |
|---|---|---|---|
| 流程 | 预定义流程 | 动态计划和调整 | 展示计划、状态和下一步 |
| 错误 | 常见错误可枚举 | 错误来源更分散 | 定位失败层级与恢复路径 |
| 责任 | 用户直接操作 | Agent 代表用户操作 | 明确授权、证据和审计 |
| 结果 | 系统状态可见 | 中间推理和工具过程不可见 | 让关键证据产品化 |
因此,Agent 可观测性不是把所有内部细节暴露出来,而是把“用户需要信任和控制的部分”显式呈现出来。
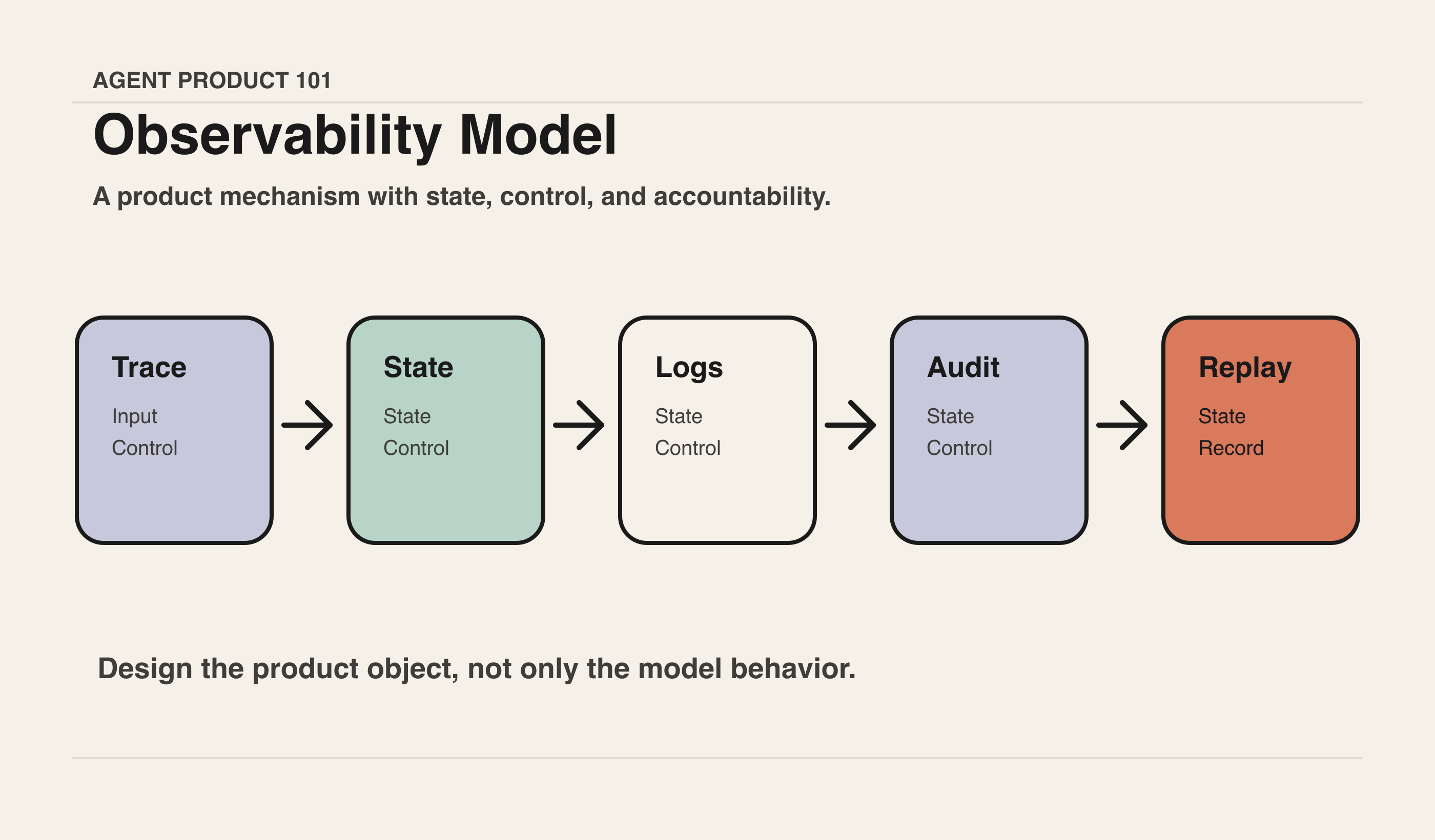
一个 PM 视角的可观测性模型
可以把 Agent Observability 拆成四层。
1. 用户可见层:让用户知道任务进行到哪了
用户不需要看到每一个 token,也不需要理解所有工具参数。用户真正需要的是:
- 当前目标:Agent 正在完成哪件事。
- 当前阶段:计划中、执行中、等待确认、阻塞、失败、完成。
- 下一步动作:接下来准备读什么、改什么、发什么、提交什么。
- 风险提示:下一步是否会产生外部后果。
- 用户入口:暂停、接管、确认、拒绝、回滚、重试。
这层的设计目标是降低不确定感,让用户知道“我是否需要介入”。
2. 任务 trace 层:让团队能复盘真实执行过程
trace 不是聊天记录。一个可复盘的 trace 至少要串起:
| 事件类型 | PM 应关心的问题 | 例子 |
|---|---|---|
| 用户输入 | 任务目标是否清楚 | 用户要求“帮我修复登录问题” |
| 计划 | Agent 是否选了合理路径 | 先查看报错,再定位文件,再生成 diff |
| 工具调用 | 系统实际做了什么 | 读取文件、运行测试、查询 CRM |
| 状态变化 | 任务是否可恢复 | running → waiting approval → done |
| 人类决策 | 谁批准了什么 | 用户确认发送邮件、reviewer 批准 PR |
| 产物 | 结果是否可验收 | diff、preview、report、ticket update |
| 错误 | 失败发生在哪里 | 权限不足、工具超时、测试失败 |
这层主要服务产品、工程、运营和支持团队。它让团队不再用“模型不稳定”解释所有问题,而能定位到底是上下文不足、权限设计差、工具质量差,还是用户入口不清楚。
3. 证据层:让结果能够被接受
Agent 说“我完成了”不等于任务完成。产品需要把结果和证据绑定在一起。
不同产品的证据形态不同:
| 产品类型 | 结果 | 需要的证据 |
|---|---|---|
| Developer Agent | 代码修改 | diff、测试结果、命令记录、PR 链接 |
| App Builder | 可运行应用 | preview、变更摘要、部署环境、回滚点 |
| Workflow Agent | 流程推进 | 审批记录、ticket 状态、通知对象 |
| CRM Agent | 客户记录更新 | 数据来源、字段变更、操作者、审计日志 |
| Research Agent | 报告 | 引用来源、检索范围、置信度、遗漏说明 |
证据层决定用户是否敢接受结果,也决定企业是否能审计结果。
4. 治理层:让组织能管理风险
当 Agent 进入团队和企业系统,可观测性必须服务治理:
- 谁创建了这个 Agent。
- 它连接了哪些系统。
- 它读取了哪些数据。
- 它代表谁执行了动作。
- 哪些动作经过审批。
- 哪些失败触发了升级。
- 哪些结果进入了业务系统。
这不是为了“管得更严”,而是为了让 Agent 从个人工具变成组织资产。
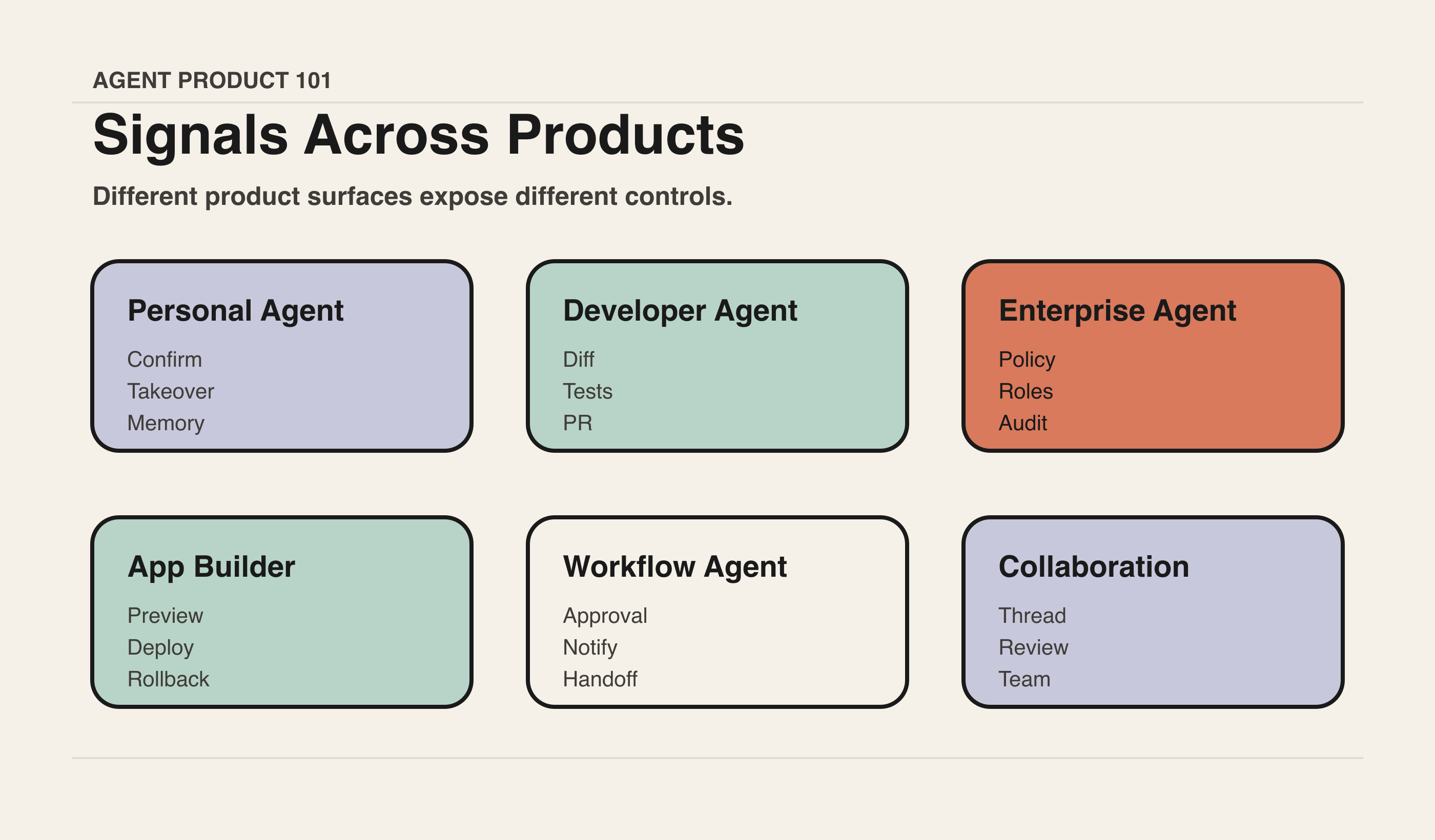
从真实产品看 Observability
Claude Code:本地 Agent 的可观测性在权限、文件和命令里
Claude Code 这类开发者 Agent 的关键不是多会聊天,而是它在本地环境里做了什么。用户需要知道:它读了哪些文件,准备修改哪里,执行了什么命令,哪些操作需要确认,最终 diff 是什么。
PM 可以从中学到:当 Agent 进入用户工作环境,过程透明度就是信任体验。不要只设计“生成答案”,要设计“行动前看计划、行动中看状态、行动后看证据”。
Codex Cloud / GitHub Copilot coding agent:把 Agent 过程放回工程协作流
云端 coding agent 的优势是任务可以排队、隔离执行、生成 PR,并进入 review 和 CI。可观测性不只是任务日志,而是 issue、branch、commit、PR、test、reviewer 共同组成的交付链路。
PM 可以从中学到:最好的可观测性不一定是新做一个复杂面板,而是把 Agent 的过程映射到用户已经理解的工作对象里。
Replit Agent:preview、日志和 rollback 让用户看到应用变化
App Builder 场景里,用户关心的不是 Agent 写了多少代码,而是应用是否真的能运行。preview、console、deployment、checkpoint 和 rollback 共同构成了可观测体验。
PM 可以从中学到:可观测性要围绕最终交付物设计。对 app builder 来说,preview 往往比文字解释更重要。
Slack / Copilot Studio / Agentforce:企业 Agent 要让团队和管理员看见
在企业场景中,可观测性不仅服务单个用户,也服务 reviewer、admin、compliance、业务 owner。Slack 的 thread 和 workflow、Copilot Studio 的治理与监控、Agentforce 的 CRM 对象和审计,都说明企业 Agent 必须把行为放进组织上下文。
PM 可以从中学到:当 Agent 影响团队流程,可观测性要分角色设计。用户看任务进展,管理员看权限和风险,业务 owner 看结果和责任。
产品判断表:哪些内容应该展示给谁
| 角色 | 最需要看到什么 | 不需要看到什么 | 产品形态 |
|---|---|---|---|
| 普通用户 | 目标、计划、下一步、证据、可操作按钮 | 原始日志、底层参数 | 任务时间线、状态卡、确认页 |
| Reviewer | 变更内容、风险、测试结果、审批历史 | 无关推理过程 | diff、preview、review panel |
| Admin | 权限、连接器、审计、异常、策略命中 | 每个用户的低风险细节 | 管理后台、审计日志、告警 |
| Support | 用户问题对应的 trace、失败原因、恢复建议 | 敏感数据全文 | 可脱敏 trace、错误分类 |
| 产品团队 | 成功率、卡点、接管率、失败分布 | 单次任务所有噪音 | funnel、cohort、failure taxonomy |
| 工程团队 | 工具调用、状态机、错误栈、重试记录 | 营销文案 | trace viewer、debug view |
一个常见错误是把工程日志直接端给用户。用户要的不是“更多信息”,而是“能做判断的信息”。
设计原则
原则一:先定义任务对象,再定义可观测对象
你要先回答:这个 Agent 的任务对象是什么?
- 是一个 chat thread?
- 是一个 project?
- 是一个 issue?
- 是一个 PR?
- 是一个 ticket?
- 是一个 CRM record?
- 是一个 workflow run?
任务对象不清楚,trace 就会散;trace 一散,状态、证据、恢复和审计都会变得困难。
原则二:不要展示所有过程,只展示决策相关过程
可观测性不是透明到让用户疲惫。PM 要区分三类信息:
| 信息类型 | 是否展示给用户 | 原因 |
|---|---|---|
| 影响用户决策的信息 | 必须展示 | 例如发送前确认、diff、付款金额 |
| 影响信任的信息 | 应该展示 | 例如数据来源、测试结果、失败原因 |
| 纯内部调试信息 | 默认不展示 | 例如底层调用细节、内部重试噪音 |
好的产品会把复杂过程折叠起来,只在风险、等待、失败、交付时展开。
原则三:把失败做成正常状态
Agent 产品不应该只有成功路径。可观测性必须覆盖:
- 需要澄清。
- 权限不足。
- 工具调用失败。
- 外部系统拒绝。
- 结果不满足验收标准。
- 用户长时间未确认。
- Agent 建议降低自主度。
如果失败状态不可见,用户会以为系统“卡住了”;如果失败原因不可见,团队会以为“模型又不行了”。
原则四:让 trace 连接指标和评估
Observability 不能停留在单次排查。它应该反哺产品改进:
- 哪类任务最常等待用户确认?
- 哪些工具调用最常失败?
- 哪些权限请求最常被拒绝?
- 哪些结果最常被用户撤销?
- 哪些失败样本应该进入 eval 回归集?
只有 trace 能连接单次任务和整体指标,产品团队才能知道该优化入口、权限、工具、模型、工作流还是文案。
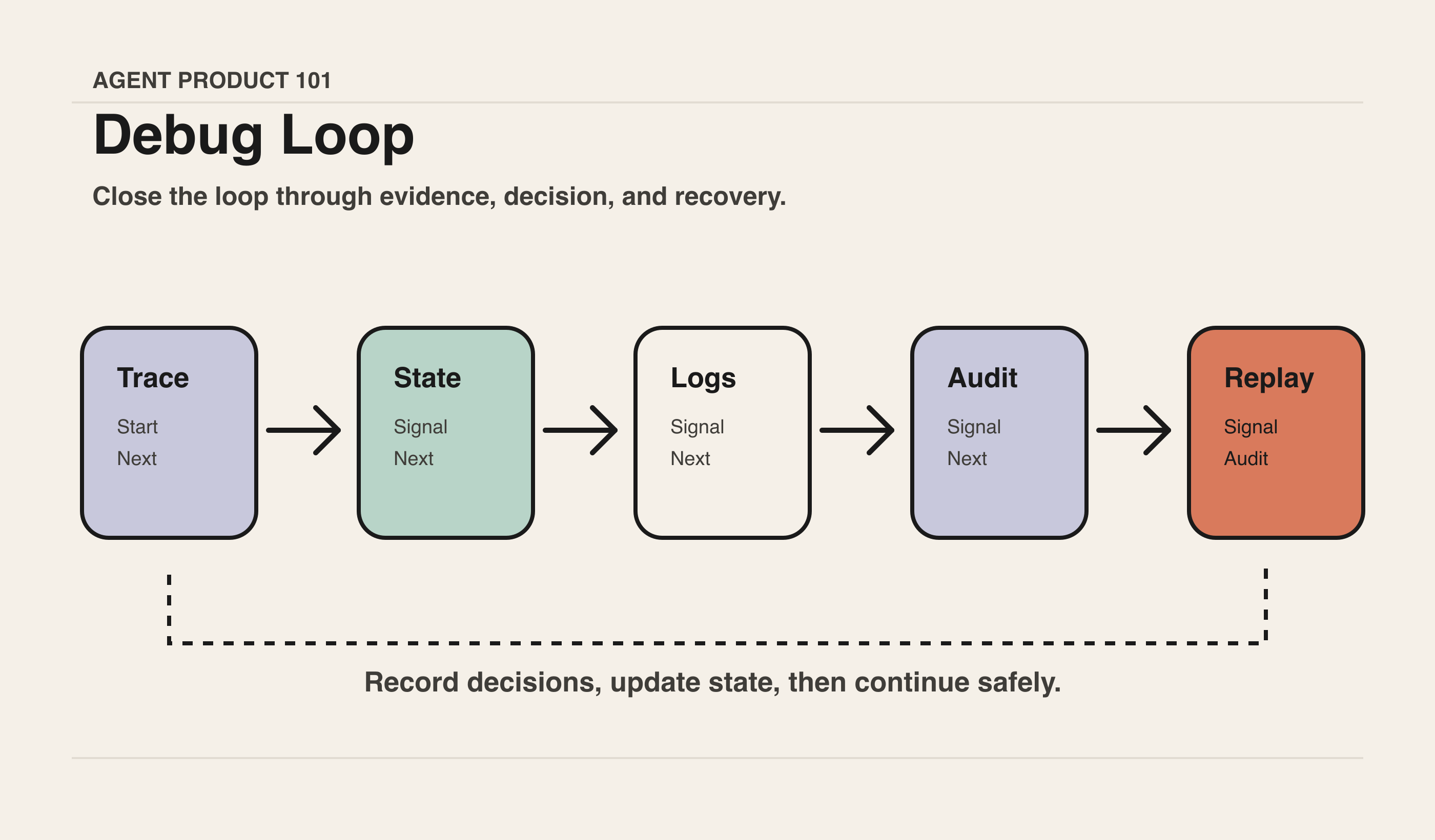
反例与误区
误区一:把聊天记录当作可观测性
聊天记录只能说明用户和 Agent 说了什么,不能完整说明系统做了什么。真正的可观测性需要记录状态、工具、审批、产物和错误。
误区二:只给工程师做日志
如果只有工程师能看懂,用户就无法信任,运营无法支持,管理员无法治理。Agent 可观测性必须按角色分层。
误区三:只在失败后提供 trace
很多控制应该发生在失败之前。比如高风险动作前展示 preview、diff、收件人、金额、影响范围。事后可追溯重要,事前可判断更重要。
误区四:为了透明而制造噪音
把每一步都推给用户,会让用户停止阅读,最后机械确认。可观测性应该围绕关键决策点设计,而不是把内部过程全部外露。
产品检查清单
设计或评审 Agent Observability 时,可以直接问:
- 这个 Agent 的 task object 是什么?
- 用户能否看到当前目标、阶段、下一步和阻塞原因?
- 高风险动作前是否展示足够证据,而不是只弹“确认”?
- trace 是否串起输入、计划、工具、状态、审批、产物和错误?
- 失败是否有可读原因和恢复路径?
- 不同角色是否有不同视图:用户、reviewer、admin、support、PM、工程?
- trace 是否能脱敏,是否支持企业审计?
- 可观测数据是否进入指标、eval 和可靠性改进?
- 用户是否能从可观测界面直接暂停、接管、重试或回滚?
- 产品是否避免把工程日志直接暴露给普通用户?
小结
Observability 的价值不是“多看一点日志”,而是让 Agent 的行动变得可理解、可判断、可恢复、可治理。
对产品经理来说,最重要的转变是:不要把 Agent 的执行过程当作后台细节。只要 Agent 会代表用户行动,过程就是产品体验的一部分。用户愿不愿意继续委托,企业敢不敢放进业务流程,团队能不能持续改进,都取决于这层是否设计清楚。
下一篇会进入 Reliability:当我们能看见 Agent 如何工作之后,产品才有可能系统性地限制失败影响、恢复状态,并提高真实交付稳定性。
参考资料
- https://docs.anthropic.com/en/docs/claude-code/overview
- https://developers.openai.com/codex/cloud
- https://docs.replit.com/core-concepts/agent
- https://docs.github.com/copilot/concepts/agents/coding-agent/about-coding-agent
- https://api.slack.com/admins/audit-logs
- https://learn.microsoft.com/en-us/microsoft-copilot-studio/
- https://www.salesforce.com/agentforce/