Agent Engineering 101|14|Policy Extensions
Policy Extensions 把权限、路径保护、plan mode 和高风险操作审批放在工具执行前后的稳定边界上。
核心结论
配套代码仓库: github.com/llm-101/mini-agent-harness
读完本文,你应该能回答
- 为什么权限不能只靠 prompt 约束?
- 路径保护、plan mode、审批分别解决什么风险?
- 危险工具调用前后应该经过哪些决策点?
- Policy Extension 如何和 Tool Runtime 协作?
本篇在系列中的位置
- 上一篇:13 Extensions 给出了通用扩展点。
- 本篇:本文聚焦治理:危险操作如何在稳定边界上被拦截、审批和记录。
- 下一篇:15 Interactive TUI 会说明这些运行时事件如何进入用户界面。
贯穿例子
本系列会反复使用同一个任务来连接各章:
用户说:“帮我修复这个 repo 里的 failing tests。”
在这个任务里,Policy Extensions 会在模型想运行删除命令、改受保护路径、上传文件或执行高风险 bash 前介入。读者要关注的是:治理必须落在工具边界和 hook 点上,而不是只写在 prompt 里。
- Policy Extension 是运行时治理层。它在 beforeToolCall、afterToolCall 或 beforeModelCall 等 hook 上检查、改写或拒绝高风险行为。
- Agent 能读写文件、运行 shell、调用 API 后,风险集中在工具执行边界。靠 prompt 约束不足以治理副作用。
- 在
mini-agent-harness中,Policy Extensions 借助 hook 介入工具执行前后,把风险控制放在副作用发生的位置。
定义
Policy Extension 是运行时治理层。它在 beforeToolCall、afterToolCall 或 beforeModelCall 等 hook 上检查、改写或拒绝高风险行为。
为什么要单独看这一层?
Agent 一旦能执行工具,就会产生副作用。权限、审批、路径保护和审计必须放在动作发生前后,而不是寄希望于模型永远遵守提示。
边界
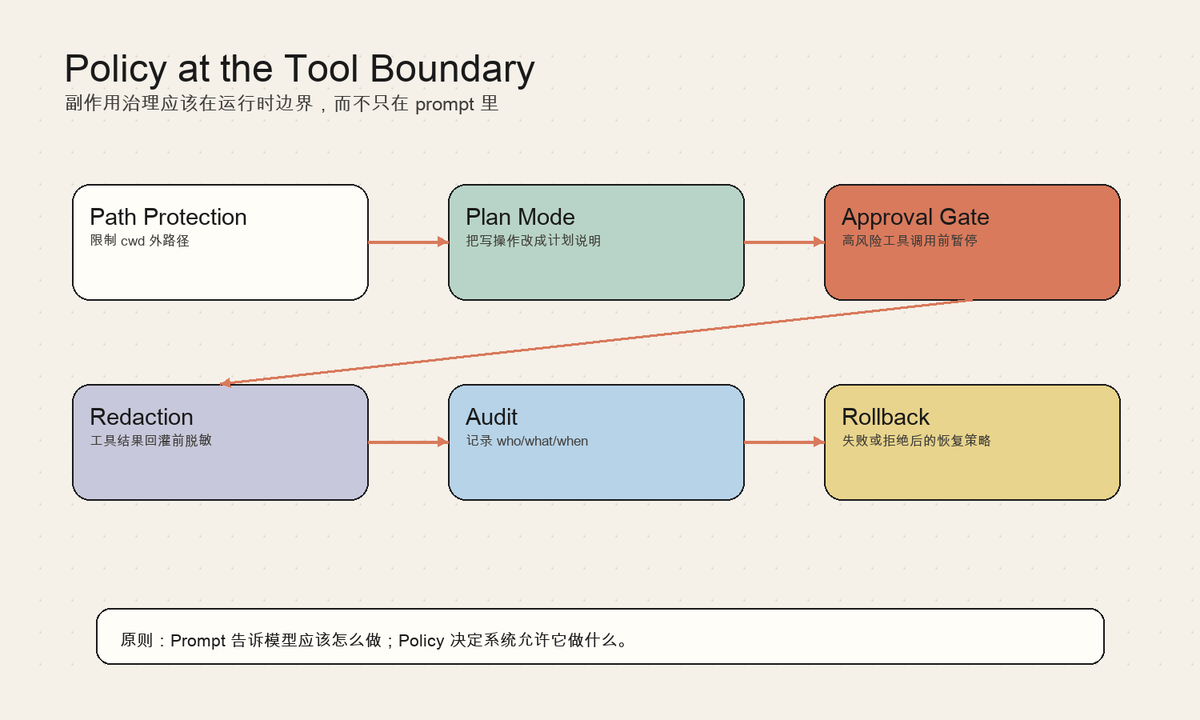
这一层的职责可以拆成几个稳定部分:
- Path Protection:限制 cwd 外路径
- Plan Mode:把写操作改成计划说明
- Approval Gate:高风险工具调用前暂停
- Redaction:工具结果回灌前脱敏
- Audit:记录 who/what/when
- Rollback:失败或拒绝后的恢复策略
这一层的边界可以用一个问题检验:如果它的内部实现变化,模型适配、工具执行、状态存储和产品外壳是否都不需要跟着重写?如果答案是否定的,说明这个边界还没有真正收束变化。
代码锚点
本篇主要对应这些模块:
src/extensions/extension-api.tssrc/tools/builtin.tssrc/core/agent-loop.ts
阅读代码时建议先看类型,再看运行路径。
类型定义告诉你这一层暴露什么 contract;运行路径告诉你这个 contract 在 Agent 执行中何时被消费、何时被写回、何时被产品层看见。
运行流程
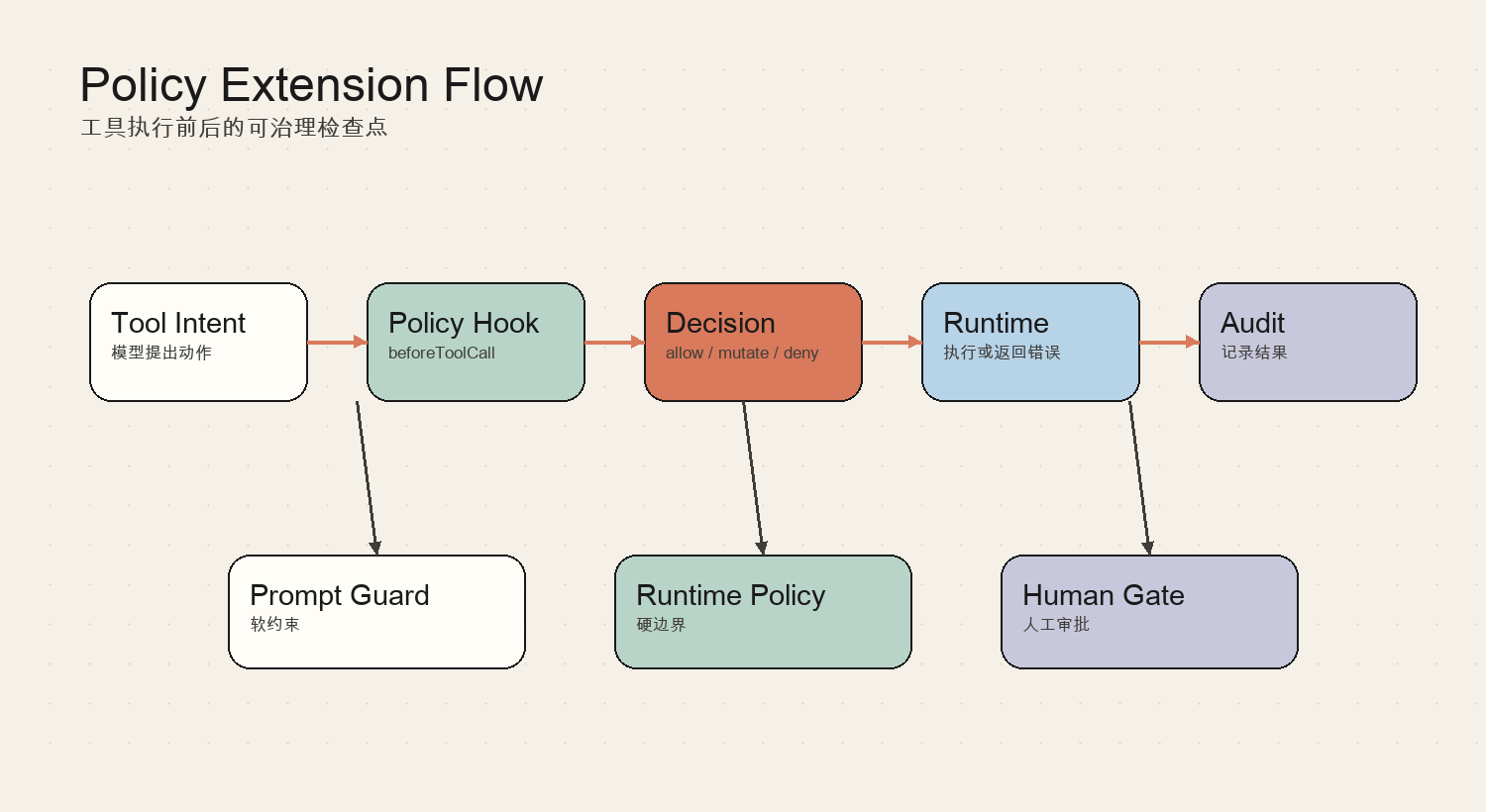
一次典型执行可以概括为:
- Tool Intent:模型提出动作
- Policy Hook:beforeToolCall
- Decision:allow / mutate / deny
- Runtime:执行或返回错误
- Audit:记录结果
- Prompt Guard:软约束
- Runtime Policy:硬边界
- Human Gate:人工审批
这里最容易被忽略的是“中间态”。生产级 Agent 不是只关心最终答案;它还要在运行过程中展示进度、捕获错误、记录 usage、允许取消,并把可恢复状态写回 session。
读者抓手:危险操作决策流水线
| 决策点 | 问题 | 可能结果 |
|---|---|---|
| 工具类型 | 这是 read、write、bash 还是 network? | 低风险直接执行,高风险进入下一步 |
| 目标范围 | 是否触碰受保护路径、密钥、系统目录? | allow / deny / ask |
| 命令语义 | 是否删除、覆盖、上传、安装或联网? | 要求确认或进入 plan mode |
| 用户意图 | 当前任务是否真的需要这个动作? | 拒绝无关动作 |
| 记录审计 | 执行前后是否留下 event 和 result? | 可追踪、可复盘 |
Policy Extension 不是让 Agent 变慢,而是把不可逆动作放到明确控制点上。
可迁移伪实现:策略拦截
下面的伪代码是机制抽象,不对应真实 API 或文件结构。它只用来说明这一层的控制点:
api.on("beforeToolCall", ({ toolName, input }) => {
if (isDangerous(toolName, input)) {
return { toolName, input: { ...input, denied: true } };
}
});
这个草图的价值在于说明控制点,而不是提供可复制的库代码。
真正的工程实现还要处理错误、取消、并发、token 预算、日志、权限、序列化和 provider 差异。
工程原则
将这一层从 Agent 系统中拆出来,通常带来四个直接收益。
第一,可替换。
外部系统、模型 provider、工具集合或产品外壳变化时,核心运行时不必整体重写。
第二,可观测。
边界清晰后,事件、trace、usage、错误和状态迁移都有稳定落点。
第三,可恢复。
只要状态写入 session,运行时就可以在进程重启、工具失败或长任务中断后继续推理。
第四,可治理。
权限、脱敏、审批、路径保护和执行策略可以放在稳定 hook 或 runtime boundary 上,而不是只靠 prompt 约束。
和 Agent Harness 的关系
Agent = Model + Harness 这个公式的重点,不是把模型之外的所有东西都称为“工程杂活”。
相反,它提示我们:模型之外存在一套必须被设计的运行时系统。
Policy Extensions 就是这套系统中的一个切面。它不替代模型能力,也不替代产品体验;它让模型能力可以被组织成可执行、可观察、可恢复、可治理的任务流程。
小结
Policy Extensions 的核心价值,是把一类容易扩散的复杂性收束到明确边界中。
在 mini-agent-harness 中,这个边界被刻意写得较小,方便阅读和教学。但它对应的问题并不小:只要一个 Agent 要长期运行、调用工具、管理上下文、支持 UI、保存状态并处理失败,这个边界就会出现。
下一步可以继续沿着系列计划,把这些边界组合成完整 Agent Harness:模型边界、工具边界、状态边界、上下文边界、扩展边界和产品外壳边界。