Agent Engineering 101|07|Tree History
Agent 的历史不应只是一条线。Tree History 让会话可以分支、回放、压缩,并保留 active branch 的语义。
核心结论
配套代码仓库: github.com/llm-101/mini-agent-harness
读完本文,你应该能回答
- 为什么 Agent 历史不应该永远是一条线?
- branch、fork、replay 分别解决什么用户场景?
- summary 节点为什么也属于历史树?
- active branch 如何决定当前上下文?
本篇在系列中的位置
- 上一篇:06 Session Store 让会话可以持久化。
- 本篇:本文把持久会话从一条线扩展为可分支、可回放的树。
- 下一篇:08 Tool Runtime 会进入模型行动真实落地的边界。
贯穿例子
本系列会反复使用同一个任务来连接各章:
用户说:“帮我修复这个 repo 里的 failing tests。”
在这个任务里,Tree History 让用户可以从“第一次测试失败后”分叉出另一种修法,而不是把所有尝试挤进一条线性聊天记录。读者要关注的是:分支不是 UI 花样,而是长任务可回放、可比较、可恢复的状态结构。
- Tree History 用 entry id 和 parentId 表示消息之间的因果关系。active leaf 指向当前工作分支,getBranch 从叶子回溯得到本轮上下文。
- 长任务中经常需要从中间状态继续、撤回、分叉或压缩旧历史。线性数组只能追加,不能表达这些关系。
- 在
mini-agent-harness中,历史被建成树,是为了让 continue、fork、compact 和 replay 有共同的状态基础。
定义
Tree History 用 entry id 和 parentId 表示消息之间的因果关系。active leaf 指向当前工作分支,getBranch 从叶子回溯得到本轮上下文。
为什么要单独看这一层?
真实任务经常需要回退、换方案、比较路径。树形历史让这些动作有结构,而不是在一条线性聊天记录里靠文字解释。
边界
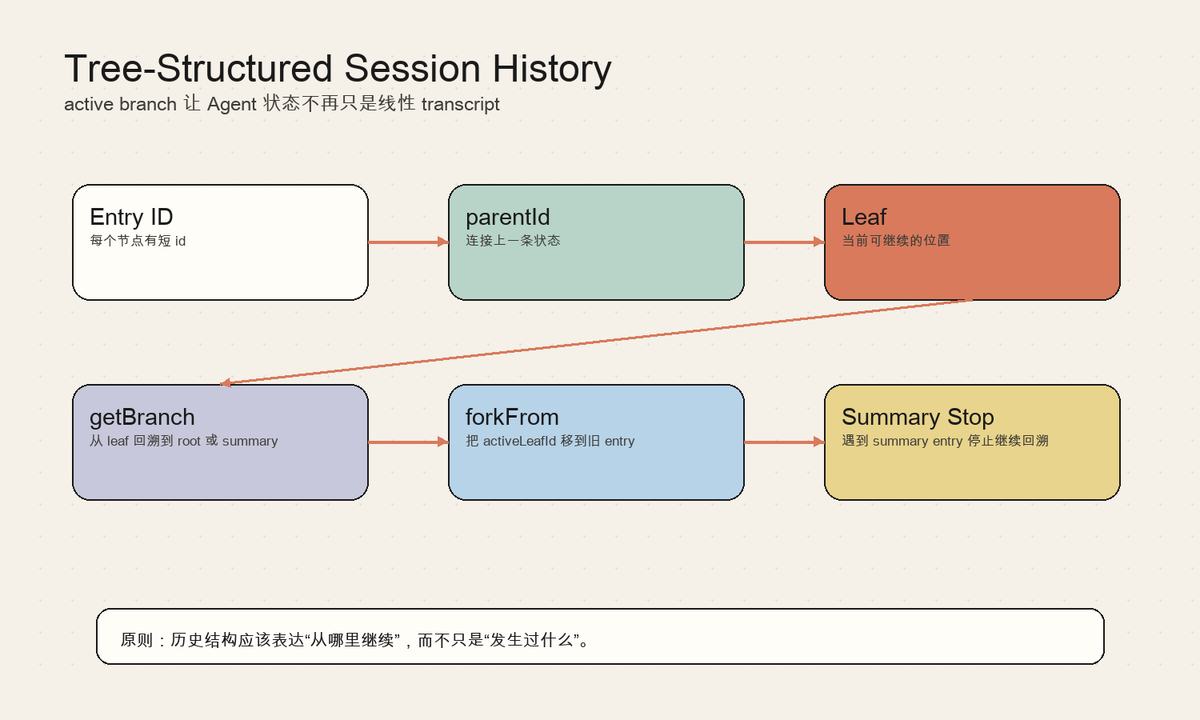
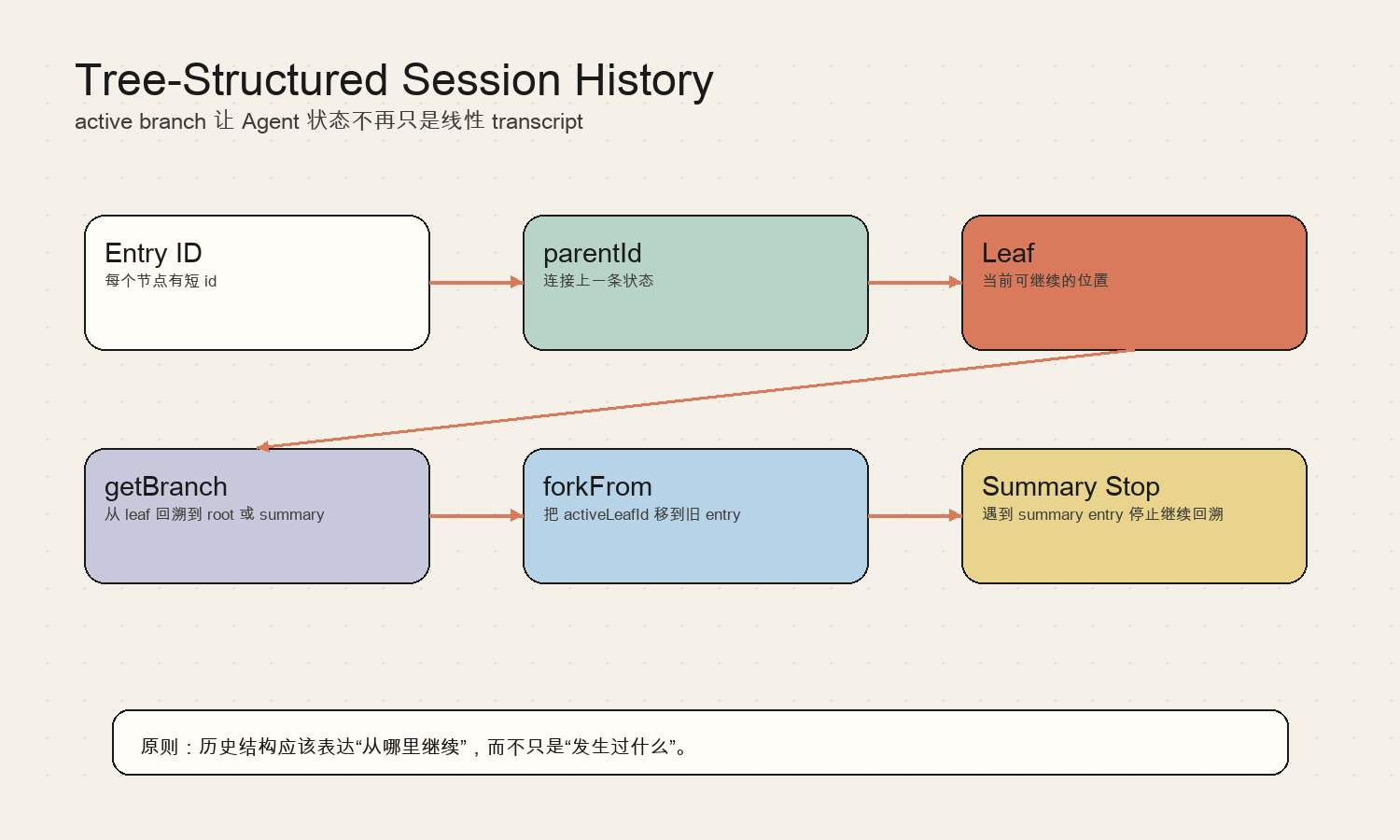
这一层的职责可以拆成几个稳定部分:
- Entry ID:每个节点有短 id
- parentId:连接上一条状态
- Leaf:当前可继续的位置
- getBranch:从 leaf 回溯到 root 或 summary
- forkFrom:把 activeLeafId 移到旧 entry
- Summary Stop:遇到 summary entry 停止继续回溯
这一层的边界可以用一个问题检验:如果它的内部实现变化,模型适配、工具执行、状态存储和产品外壳是否都不需要跟着重写?如果答案是否定的,说明这个边界还没有真正收束变化。
代码锚点
本篇主要对应这些模块:
src/session/session-tree.tssrc/session/jsonl-session-store.ts
阅读代码时建议先看类型,再看运行路径。
类型定义告诉你这一层暴露什么 contract;运行路径告诉你这个 contract 在 Agent 执行中何时被消费、何时被写回、何时被产品层看见。
运行流程
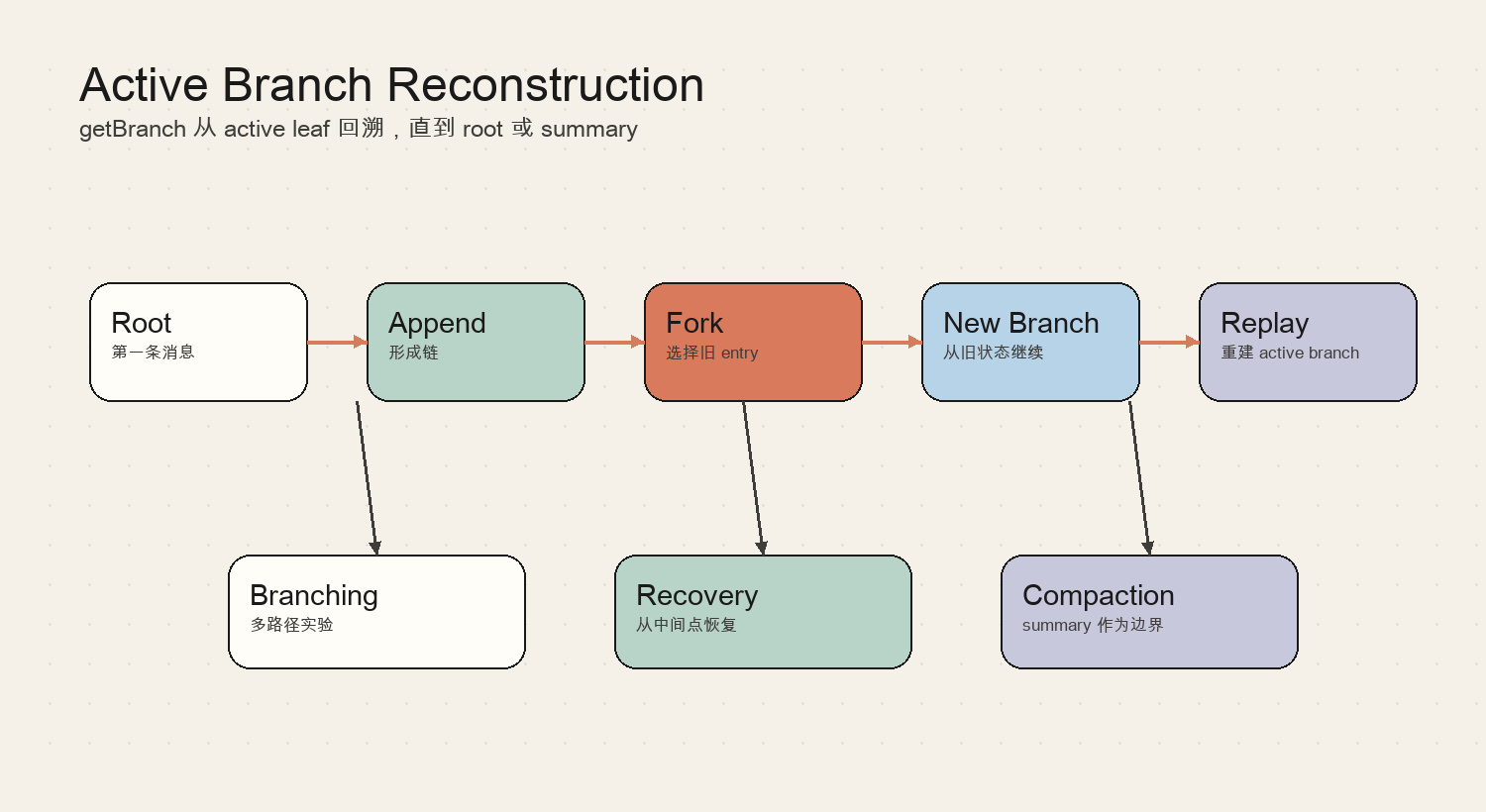
一次典型执行可以概括为:
- Root:第一条消息
- Append:形成链
- Fork:选择旧 entry
- New Branch:从旧状态继续
- Replay:重建 active branch
- Branching:多路径实验
- Recovery:从中间点恢复
- Compaction:summary 作为边界
这里最容易被忽略的是“中间态”。生产级 Agent 不是只关心最终答案;它还要在运行过程中展示进度、捕获错误、记录 usage、允许取消,并把可恢复状态写回 session。
读者抓手:为什么需要树,而不是一条聊天线
假设 Agent 修改代码后,用户说:“这个方向不对,回到运行测试之后,换一种修法。”
线性历史只能继续追加,难以表达“从中间某一点重新出发”。Tree History 可以把“运行测试之后”作为旧节点,从那里 fork 出新分支。
| 场景 | 线性历史的问题 | Tree History 的表达 |
|---|---|---|
| 回到旧方案 | 只能继续解释或覆盖 | 从旧节点 fork 新 branch |
| 比较两种修法 | 两套变更混在一条线里 | 两个 leaf 表示两个候选路径 |
| 压缩长历史 | 摘要不知道挂在哪里 | summary entry 成为树上的节点 |
| replay 调试 | 很难确定从哪里开始 | 从指定节点重放 active branch |
可迁移伪实现:树形历史
下面的伪代码是机制抽象,不对应真实 API 或文件结构。它只用来说明这一层的控制点:
function getBranch(entries, leafId) {
const branch = [];
for (let id = leafId; id; id = byId.get(id).parentId) {
const entry = byId.get(id);
branch.push(entry);
if (entry.type === "summary") break;
}
return branch.reverse();
}
这个草图的价值在于说明控制点,而不是提供可复制的库代码。
真正的工程实现还要处理错误、取消、并发、token 预算、日志、权限、序列化和 provider 差异。
工程原则
将这一层从 Agent 系统中拆出来,通常带来四个直接收益。
第一,可替换。
外部系统、模型 provider、工具集合或产品外壳变化时,核心运行时不必整体重写。
第二,可观测。
边界清晰后,事件、trace、usage、错误和状态迁移都有稳定落点。
第三,可恢复。
只要状态写入 session,运行时就可以在进程重启、工具失败或长任务中断后继续推理。
第四,可治理。
权限、脱敏、审批、路径保护和执行策略可以放在稳定 hook 或 runtime boundary 上,而不是只靠 prompt 约束。
和 Agent Harness 的关系
Agent = Model + Harness 这个公式的重点,不是把模型之外的所有东西都称为“工程杂活”。
相反,它提示我们:模型之外存在一套必须被设计的运行时系统。
Tree History 就是这套系统中的一个切面。它不替代模型能力,也不替代产品体验;它让模型能力可以被组织成可执行、可观察、可恢复、可治理的任务流程。
小结
Tree History 的核心价值,是把一类容易扩散的复杂性收束到明确边界中。
在 mini-agent-harness 中,这个边界被刻意写得较小,方便阅读和教学。但它对应的问题并不小:只要一个 Agent 要长期运行、调用工具、管理上下文、支持 UI、保存状态并处理失败,这个边界就会出现。
下一步可以继续沿着系列计划,把这些边界组合成完整 Agent Harness:模型边界、工具边界、状态边界、上下文边界、扩展边界和产品外壳边界。