Pi Agent 101|07|Provider Abstraction
Pi 把 Model、API、Provider 和流式事件分开,让 agent layer 不依赖具体厂商协议。
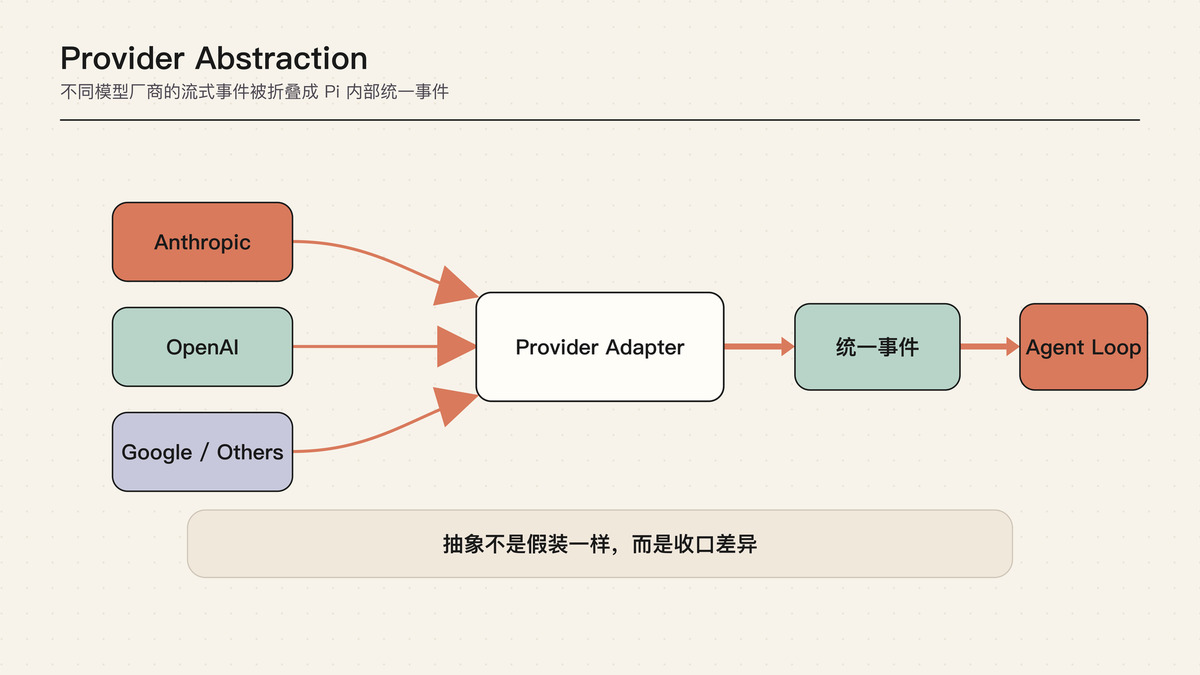
上一篇讲的是怎么管理模型这一轮能看到的上下文。这一篇换一个平行问题:模型本身怎么接进来?
不同模型厂商像不同插座。你当然可以给每个插座单独做一套电器,但 agent runtime 会被这些差异拖垮。
Pi 的做法是做一层转接头。上层只关心“给我一串统一的模型事件”,下层再去处理 OpenAI、Anthropic、Google 或其他 provider 的细节。
这也是理解 OpenClaw provider 层的入口:上层产品不应该到处关心每个厂商的 stream 细节,它需要的是一条稳定的模型事件流。
Agent runtime 不应该到处写 if provider == openai 或 if provider == anthropic。模型 厂商差异 很多:消息格式、tool call streaming、thinking、cache、session affinity、transport、错误形式都不同。如果这些差异泄漏到 agent loop,系统会很快失控。
Pi 把这件事收口成 Model / API / Provider 三层,再用统一的 assistant event stream 给上层消费。
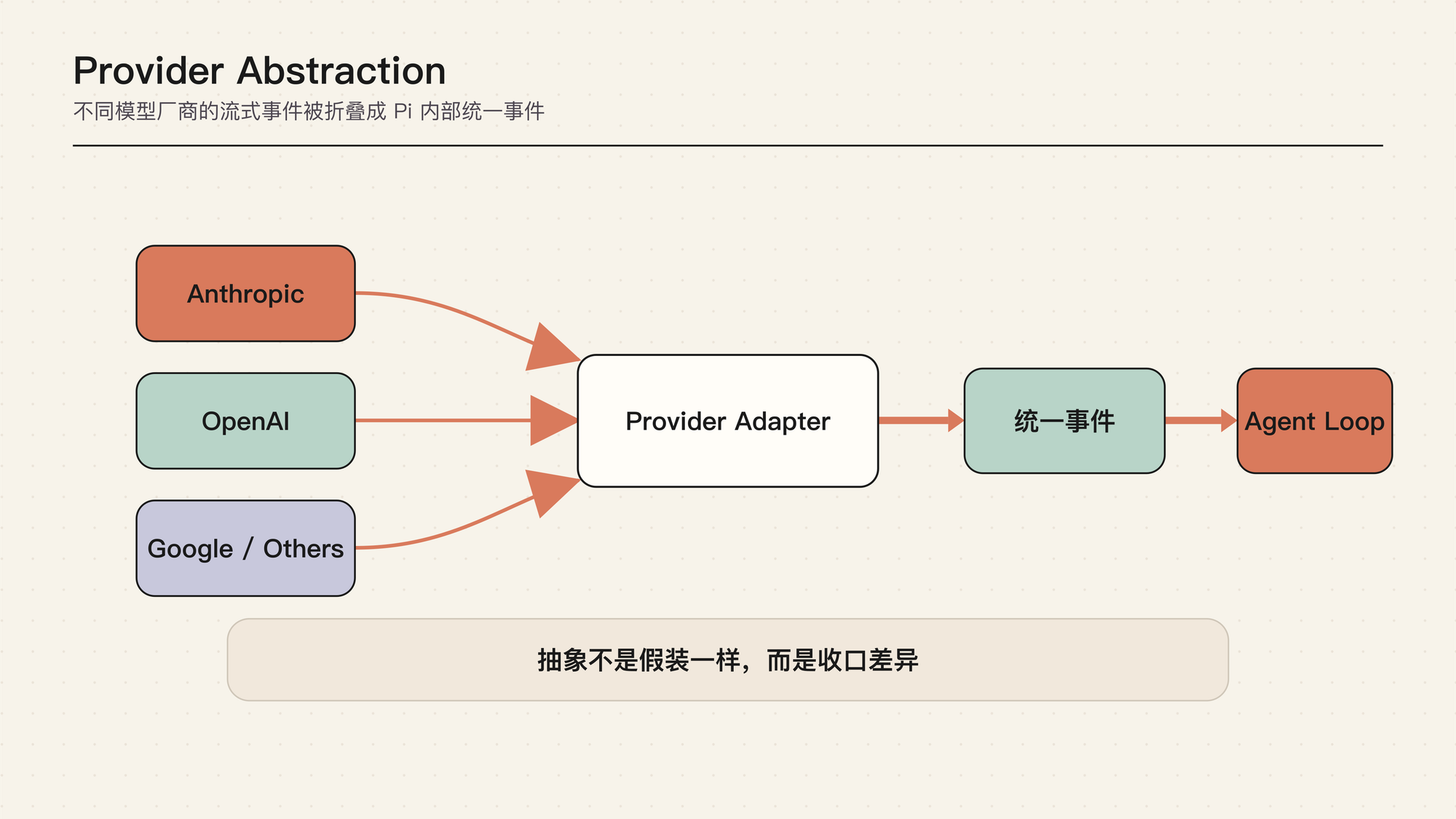
这张图的重点是“统一”而不是“抹平”。不同模型厂商的 API、stream event、tool call 格式、reasoning 支持、上下文窗口、错误码和计费信息都不同。Provider Abstraction 不是假装它们一样,而是把差异放到明确位置。
上层 runtime 不应该到处写“如果是某厂商就这样处理”。更稳的方式是让 adapter 把厂商事件转成统一的 runtime event,再把无法统一的能力放进 capability / compatibility 描述。
本文结构
不同模型厂商的接口并不一样:消息格式、工具调用、推理参数、错误码、上下文窗口都可能不同。Provider Abstraction 的目标不是抹平所有差异,而是把差异关在适配层里,让 Agent 的主流程仍然用统一方式工作。
这一篇按机制展开:先看核心问题,再看运行路径、边界、设计取舍,以及它和 OpenClaw 的对应关系。
阅读目标
- 理解 Model、API、Provider 三层为什么要分开
- 看清 stream / streamSimple 和统一事件协议的价值
- 学会把 provider 兼容差异放进 metadata 和 adapter,而不是散落在 runtime
三层抽象

这张图说明:模型是谁、怎么认证、怎么调用,要分层处理。
- Model:描述模型能力、上下文窗口、成本、reasoning、compat 等
- API:描述调用协议,例如 OpenAI-compatible、Anthropic Messages、Google 等
- Provider:描述账号/厂商来源,例如 OpenAI、Anthropic、OpenRouter、Copilot 等
一个 provider 可以支持多个 API;多个 provider 也可以复用同一种 API 适配器。这样 agent layer 只需要说“我要用这个 model stream 一段 assistant message”,不用知道底层协议细节。
主流 Agent 产品里的 Provider Abstraction
很多读者关心 Claude Code、Cursor、Copilot 这些产品到底怎么接不同模型。答案通常不是“每个地方都写一套 OpenAI/Anthropic 分支”,而是把差异尽量压到 provider adapter 里。
一个具体例子是 tool calling 的流式返回。Anthropic 的 Messages API 会流出 tool_use content block,工具名和输入会随着 block 逐步完成;OpenAI 风格接口通常流出 tool_calls delta,函数名、参数 JSON 也可能被分片吐出来。上层 agent loop 如果直接消费这些原始事件,就会到处充满厂商判断。
Pi 的做法是把这些差异归一化成统一的 assistant event:比如 toolcall_start、toolcall_delta、toolcall_end。到了 agent loop 这一层,它只知道“模型正在提出一个工具调用”,不需要知道底下是 Anthropic 的 tool_use,还是 OpenAI 的 tool_calls。这就是“转接头”比喻真正落地的地方。
放到“修复失败测试”的例子里,模型可能先输出一段解释,再流式生成一个 bash 工具调用。Anthropic 和 OpenAI 把这个工具调用吐出来的方式不一样,但 agent loop 不应该在意。它只需要收到同一种内部事件:工具名是什么,参数是不是完整,什么时候可以交给 Tool Runtime 执行。
统一流式事件

这张图说明:上层 loop 不应该关心底下是哪个厂商的原始事件格式。
Pi 把 provider 的 SSE、WebSocket 或 SDK stream 归一化成统一事件:start、text_start、text_delta、thinking_delta、toolcall_delta、done、error 等。上层 agent loop 不消费厂商原始事件,而是消费 assistant message reducer 协议。
这带来两个好处:第一,TUI、agent loop、session persistence 都消费同一种事件;第二,provider 错误也能事件化,形成可恢复的 assistant error message,而不是随机 throw。
把厂商差异收进 compat flags

这张图说明:抽象不是假装一样,而是把差异放在明确位置。
OpenAI-compatible 生态尤其复杂:不同厂商对 developer role、reasoning effort、max tokens 字段、tool result name、cache control 等支持不同。Pi 把这些差异放进 compat flags,让转换逻辑集中处理。
这是 provider abstraction 的关键原则:抽象不是假装所有模型一样,而是把差异收口到明确位置。
设计边界
如果自己做 harness,不要让上层到处判断模型厂商。把 provider 差异收口到 adapter:模型能力、stream event、tool call、reasoning、usage、错误和重试策略都在这一层归一化。上层消费的是统一事件流,而不是厂商 API 细节。
抽象层最容易犯的错

这张图说明:坏抽象会让上层产品到处处理厂商细节。
第一种错,是抽象太薄。上层仍然到处知道厂商细节,最后每接一个模型都要改 agent loop、tool runtime 和 UI。第二种错,是抽象太厚。为了统一接口,隐藏了模型能力差异,导致 reasoning、tool calling、JSON mode、cache、文件输入这些能力不能被正确利用。
好的 provider abstraction 应该让上层少关心厂商细节,同时保留足够的能力描述。比如模型是否支持 tool call,是否支持 thinking,最大上下文是多少,某些 stop reason 如何解释,错误是否可重试。
它如何影响用户体验

这张图说明:用户感知到的是稳定切换和清楚错误,不是底层 API 名字。
用户感受到的不是 provider adapter,而是“为什么换了模型之后工具调用坏了”“为什么流式输出突然没有 thinking”“为什么同样任务在一个模型下能继续,在另一个模型下上下文溢出”。
Provider Abstraction 做得好,这些差异会被 runtime 明确处理;做得差,差异会一路漏到产品界面,最后变成用户自己排查的神秘问题。
设计取舍
Provider 差异。Pi 的选择是:metadata + adapter。可复用的原则是:不要污染 agent loop。
Streaming。Pi 的选择是:统一 assistant event stream。可复用的原则是:上层只依赖稳定事件协议。
Provider 加载。Pi 的选择是:lazy loading。可复用的原则是:CLI 冷启动和可选依赖更安全。
Cache/session。Pi 的选择是:sessionId/cacheRetention 统一传入。可复用的原则是:厂商语义在 adapter 中翻译。
OpenClaw 的对应问题
OpenClaw 里也会遇到类似问题:这一篇对应 provider、model router 和多模型接入。OpenClaw 上层可能接不同模型渠道,但 channel、plugin、gateway 不应该到处关心 Anthropic 的 tool_use 或 OpenAI 的 tool_calls。这些差异应该收在 provider 层,给上层一条稳定事件流。
实现里的 Provider 分层
Pi 没有把“模型厂商”直接写进 agent loop。它把模型信息、API 协议实现、认证配置分成几层:模型描述自己是谁、上下文窗口多大、支持哪些能力;API provider 负责某类协议怎么调用;运行时的 model registry 决定当前有哪些模型可用、认证从哪里来、请求头怎么合并。
这样做的好处是,上层 AgentSession 不需要到处判断“如果是某个厂商就怎样”。它只拿到一个模型对象和统一的流式事件。厂商差异被收进 provider adapter 和 capability/compat 描述里。
这不是为了把所有模型假装成一样,而是把差异放在正确位置。不同模型可能支持不同 tool calling 格式、reasoning、缓存、上下文窗口、stop reason 和错误码。抽象层要让上层少关心细节,同时不能隐藏真正影响行为的能力差异。
Provider 分层与用户体验
用户感受到的不是 provider abstraction,而是换模型后的稳定性。同样的任务,为什么一个模型能调用工具,另一个模型工具格式出错?为什么一个模型上下文够用,另一个溢出?为什么某个模型能显示 thinking,另一个不能?
如果 provider 层做得不好,这些差异会一路漏到 UI 和用户心智里。做得好,runtime 会在模型选择、认证、请求、错误恢复和事件流上给出一致体验。
所以 Provider Abstraction 的核心不是“支持很多模型”,而是:让多模型能力进入同一套 agent runtime,而不污染上层产品逻辑。
如何判断
第一,上层看到的是统一事件,还是厂商事件。统一事件能让 agent loop 和 UI 稳定;厂商事件泄漏太多,系统会难以维护。
第二,能力差异有没有被显式表达。不同模型的上下文窗口、工具调用、reasoning、缓存、输入格式都不同,不能靠默认假设。
第三,错误和 stop reason 有没有归一化。模型停止、工具调用失败、限流、认证过期、上下文溢出,在产品上应该给出不同处理。
一句话总结
agent loop 不应该认识每个厂商的小脾气,provider adapter 才应该。
小结
Pi 的 Provider Abstraction 不是为了做一个“万能 SDK”,而是为了保护 agent runtime 的边界。模型厂商会变,协议会变,但 agent loop 最好只看到稳定的消息、工具和事件。