Pi Agent 101|13|The Agent Harness Map
用一张总图把 Pi Agent 101 串起来:模型、工具、消息、会话、上下文、扩展、UI 和可观测性如何组成一个 Agent Harness。
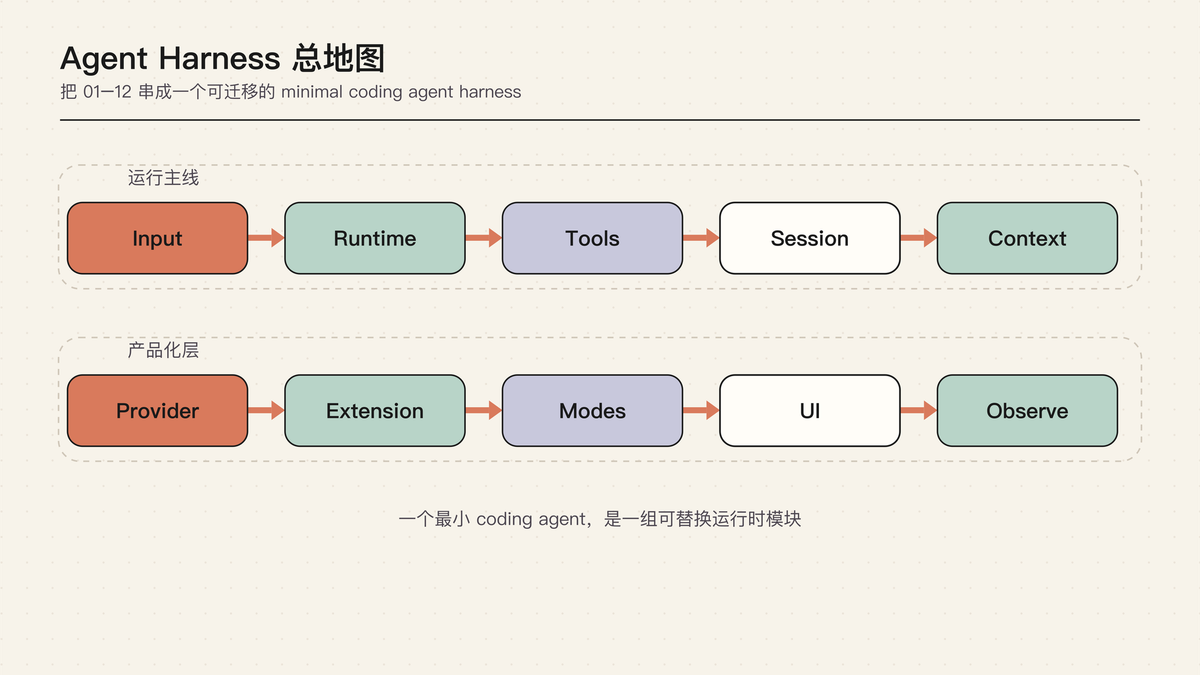
读完前面十二篇,你可能已经知道很多局部机制:Runtime、Message Flow、Tool Runtime、Session Tree、Compaction、Provider、Extension、TUI、Observability。
只记住一堆术语还不够。关键是形成一张总图:一个 Agent Harness 到底由哪些边界组成,这些边界怎么接在一起。
这篇就是总图。
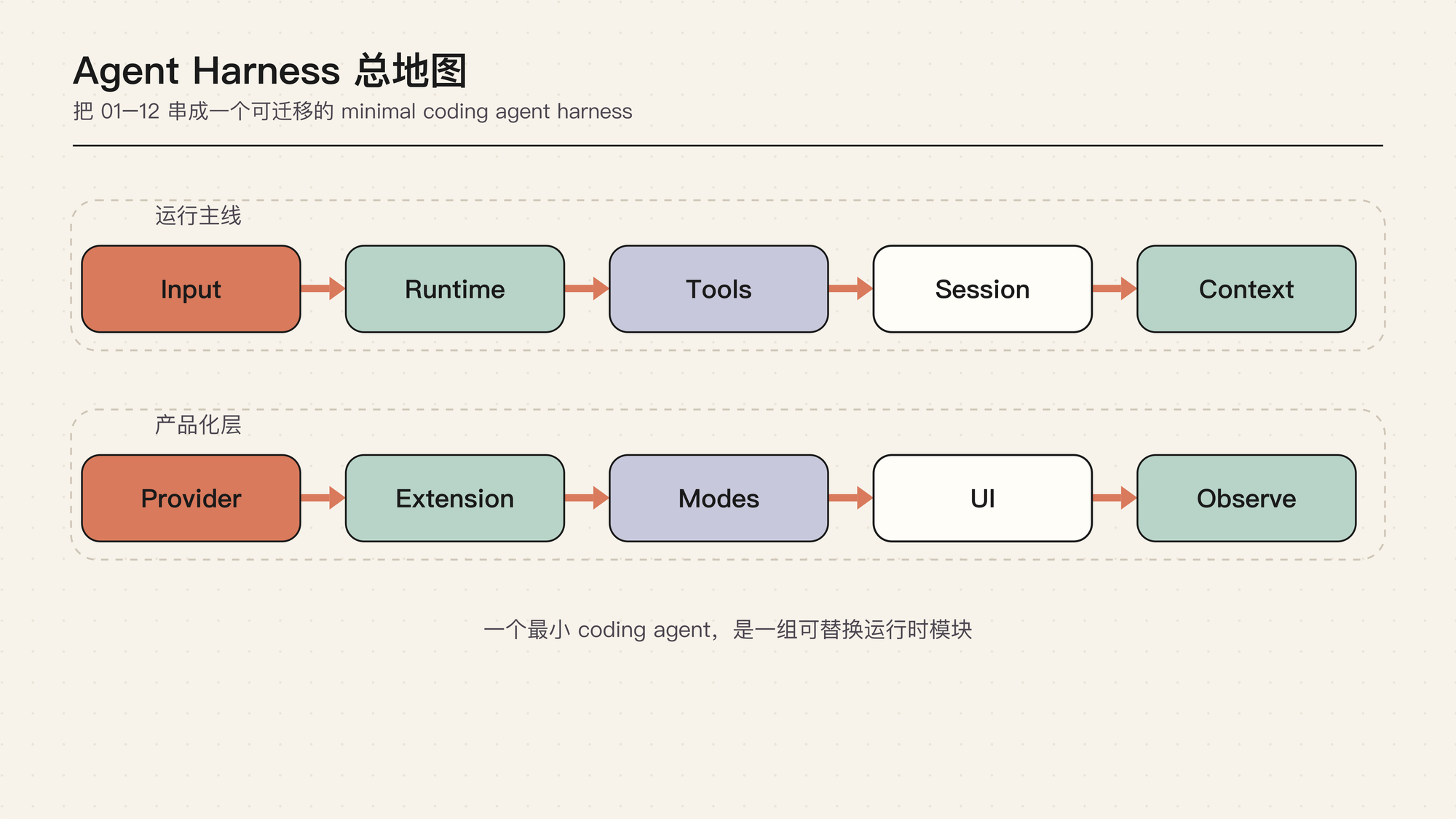
这张总地图不是在列模块,而是在告诉你:一个 agent 产品至少有四圈。模型是最内圈;runtime 负责让模型持续行动;状态和扩展让长任务可恢复、可压缩、可扩展;产品界面让用户能看见、介入和复盘。
如果只盯着模型能力,就会低估外圈系统的复杂度。真正的 Agent Harness,是把这四圈稳定接起来。
本文结构
Agent Harness 可以理解成让模型真正工作的底盘。模型负责思考和生成意图,Harness 负责组织上下文、执行工具、保存会话、处理错误、允许用户介入、把过程展示出来。没有 Harness,模型只是一个聊天接口;有了 Harness,模型才进入真实任务环境。
这一篇按机制展开:先看核心问题,再看运行路径、边界、设计取舍,以及它和 OpenClaw 的对应关系。
先看一条完整路径

这张图说明:Harness 让模型的意图穿过真实任务环境。
还是那个例子:用户说“修复这个失败测试”。
这句话进入 Pi 后,不会直接变成一次模型调用。它会经过一条链路:
- Mode adapter 接住用户输入
- AgentSession 准备运行环境
- Context builder 整理模型这一轮能看到什么
- Provider layer 调用模型并接收流式事件
- Agent loop 处理文本、tool call 和下一轮控制流
- Tool Runtime 执行 read/bash/edit/write
- Tool result 写回上下文
- Session Tree 记录完整过程
- Compaction 在历史太长时插入 checkpoint
- TUI/RPC/SDK 把事件展示或交给外部系统
- Observability 和 export 让过程可以复盘
这条链路就是 Agent Harness。
一组结构看完整系统

这张图说明:这五类结构拼起来,才是一个能持续做事的 agent。
- 边界:Agent Runtime
- 它解决的问题:一条用户消息先进入哪里,谁负责调度
- 对应文章:01
- 边界:Message Flow
- 它解决的问题:session 事实和模型上下文怎么分开
- 对应文章:02
- 边界:Session Turn Loop
- 它解决的问题:模型、工具、结果如何持续推进
- 对应文章:03
- 边界:Tool Runtime
- 它解决的问题:模型提出行动后,谁真正执行
- 对应文章:04
- 边界:Session Tree
- 它解决的问题:长任务如何分支、恢复、导出
- 对应文章:05
- 边界:Context Compaction
- 它解决的问题:上下文太长时怎么继续跑
- 对应文章:06
- 边界:Provider Abstraction
- 它解决的问题:不同模型厂商怎么变成统一事件流
- 对应文章:07
- 边界:Context Files and Skills
- 它解决的问题:system prompt 如何来自当前工作环境
- 对应文章:08
- 边界:Extension Runtime
- 它解决的问题:外部能力如何安全进入系统
- 对应文章:09
- 边界:Mode Adapters
- 它解决的问题:TUI、print、RPC、SDK 如何共用 runtime
- 对应文章:10
- 边界:Terminal UI Runtime
- 它解决的问题:终端如何承载流式 agent 体验
- 对应文章:11
- 边界:Observability and Sharing
- 它解决的问题:运行过程如何被复盘和分享
- 对应文章:12
主流 Agent 产品里的 Harness
Claude Code、Codex CLI、Cursor、OpenClaw 的形态不同,但底层问题很像。
Claude Code 更像终端里的完整 agent runtime。你看到的是命令行交互,底下是模型流、工具调用、文件操作、Bash、权限、session 和压缩。
Codex CLI 也类似,只是它的协议、事件和工具组织方式不同。用户看到的是一次任务,底下仍然是 turn loop 和 tool result 回填。
Cursor 把很多东西藏进 IDE。你不一定看到完整事件流,但它仍然要处理上下文选择、文件编辑、工具执行和模型状态。
OpenClaw 把问题进一步扩展到 channel、plugin、gateway、provider、media、voice 和 trajectory。它不是只有一个终端入口,而是一个更大的 agent 产品系统。所以理解 Pi 的底盘,再读 OpenClaw 的上层模块,会更容易分清主次。
最容易忽略的部分
如果你关心的是 2024–2025 年 agent 产品为什么都长得越来越像,Pi 这组文章给出的不是“某个项目的实现细节”,而是一组正在变成行业标准的边界。
第一,模型接入正在 adapter 化。产品不想在每个地方处理 Anthropic、OpenAI、Google、OpenRouter 的细节,而是把差异压进 provider layer。
第二,工具执行正在 runtime 化。tool calling 不再只是 prompt 技巧,而是一套包含 schema、权限、超时、并发、副作用、结果回填和审计的本地执行系统。
第三,会话正在从聊天记录变成状态树。长任务需要分支、恢复、压缩、导出和复盘,线性 message array 很难支撑这些能力。
第四,产品界面正在变成 observability layer。TUI、IDE、RPC、trajectory export 表面不同,本质上都在把 agent 的运行过程变成用户可以理解、可以介入、可以追责的证据链。
最小 Harness 怎么搭

这张图说明:先做底层运行机制,再做漂亮入口。
可以先从六个模块开始:
- Agent Runtime:推进 turn loop,接收模型输出,处理工具调用和中断。
- Context Builder:把 session、项目规则、skills、文件片段和摘要整理成模型这一轮可见的上下文。
- Tool Runtime:负责工具 schema、权限、执行、错误包装和结果回填。
- Session Store:保存运行事实,支持恢复、分支、压缩和导出。
- Provider Adapter:把不同模型厂商收口成统一事件流。
- Runtime Event Sink:把运行过程交给 TUI、RPC、日志或分享系统展示。
方向不是先堆功能,而是先把边界搭出来。很多 agent 项目失败,不是因为模型不够强,而是一开始就把这些边界混在一起。
最后一张心智图

这张图说明:越往外越接近产品体验,越往内越接近模型与执行。
可以把 Agent Harness 想成四圈。
最里面是模型:它负责生成文本和工具调用。
第二圈是 runtime:它负责 loop、消息、工具执行和上下文回填。
第三圈是状态和扩展:session、compaction、skills、extensions、provider registry。
最外圈是产品界面:TUI、RPC、SDK,以及 OpenClaw 的 channel、plugin、gateway、可观测和分享系统。
重点不在“谁又发布了一个 agent 产品”。更值得看的是:这些产品背后,哪些底层边界正在变成标准结构。Pi Agent 101 讲的就是这套结构。
OpenClaw 的对应问题
OpenClaw 里也会遇到类似问题:可以把这篇当成回看地图:channel、plugin、gateway、media、voice 是上层产品能力;Pi 这组文章讲的是下面那套 agent harness。先分清这两层,再看 OpenClaw 的模块关系,会少很多混乱。
回头看整个系列

这张图说明:系列不是散点知识,而是一条从运行到复盘的完整链路。
前四篇回答“agent 怎么跑”:Runtime、Message Flow、Turn Loop、Tool Runtime。中间四篇回答“长任务怎么撑住”:Session Tree、Context Compaction、Provider Abstraction、Context Files and Skills。后五篇回答“怎么做成产品”:Extension Runtime、Mode Adapters、Terminal UI Runtime、Observability,以及最后的总地图。
这组文章的价值不在 Pi 这个项目本身,而在它把一个本地 coding agent 的底盘拆成了可以迁移的边界。你可以不用 Pi,但很难绕开这些问题。只要你的产品想让模型读文件、跑工具、跨多轮完成任务、恢复历史、切换模型、接入插件、展示过程,这些边界就会重新出现。
实现里的 Harness 地图
把 Pi 整体连起来看,会发现 Agent Harness 不是某一个模块,而是一组协作边界:执行环境、模型与 provider、会话树、工具运行时、资源加载、事件与 hooks、队列、压缩、分支摘要、UI/协议出口。
这组边界共同解决一个问题:让模型在真实环境里持续工作。模型本身只产生文本和工具意图;Harness 负责组织上下文、执行工具、保存状态、处理错误、允许用户介入、让过程可观察。
如果用四圈理解,最内圈是模型,第二圈是 runtime,第三圈是 session / compaction / resources / extensions,最外圈是 TUI、RPC、export、share 这些产品界面。任何成熟 agent 产品,都很难绕开这四圈。
这组文章不是源码导读
Pi 只是一个很好的样板。真正值得记住的不是某个文件怎么写,而是一组可迁移问题:你的 agent 是否区分内部事实和模型视图?是否有工具执行边界?是否能保存分支历史?是否能压缩上下文而不破坏任务状态?是否能接多模型?是否能通过扩展加入能力?是否能让用户看见并复盘过程?
这些问题回答清楚了,才有 Agent Harness。否则只是一个会调用模型和工具的脚本。
如何判断
第一,这个系统有没有把模型、runtime、状态和产品界面分开。分不开,就很难扩展。
第二,长任务所需的能力是否齐全:工具执行、session 恢复、上下文压缩、provider 抽象、扩展机制、可观测性。少任何一块,系统都会在复杂任务里变脆。
第三,产品外壳是否复用底座。一个成熟的 agent 产品,可以有多个入口和渠道,但不应该有多套互相分叉的 agent loop。
小结
Pi Agent 101 的主线可以压缩成一句话:Agent Harness 把模型放进一个能行动、能记录、能恢复、能扩展、能被观察的运行环境里。
如果你只想做 demo,可以少很多东西。如果你想做一个真正能长时间运行、能被用户信任、能接进 OpenClaw 这类产品系统的 agent,这些边界迟早都要面对。