OpenClaw 101|13|Security and Operations
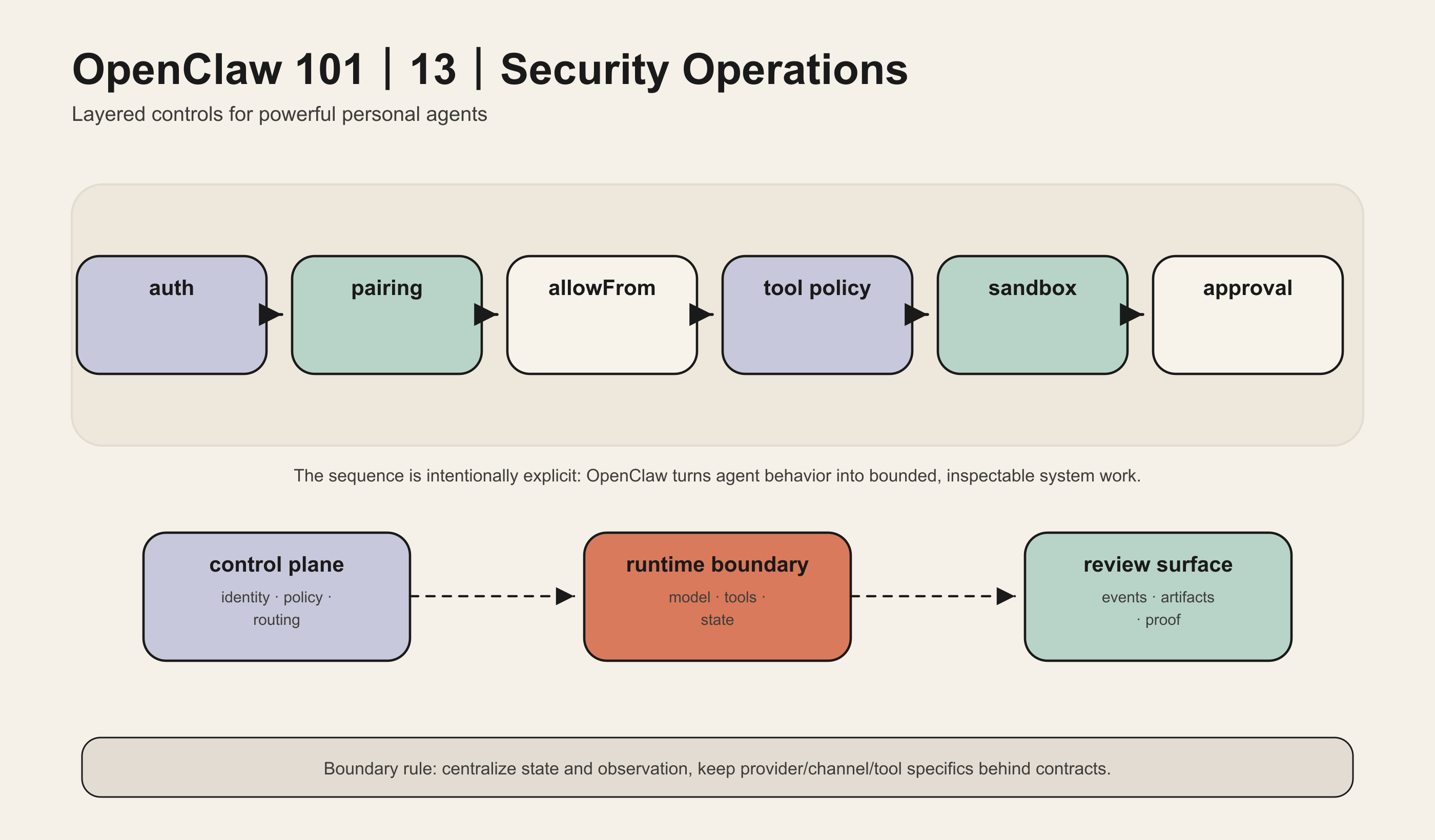
一个能读文件、跑命令、发消息、调用设备的 Agent 必须有分层安全:auth、pairing、allowFrom、tool policy、sandbox、approval 和 audit。
OpenClaw 101 是一组面向 Agent Engineering 的系统拆解文章。它不把 OpenClaw 当成单一聊天产品,而是把它当作一个长期运行的 Personal Agent OS 来观察。
这一篇讲 Security and Operations。Personal Agent OS 的能力越强,安全边界越重要。安全不是一个开关,而是一组互补的控制层。
读完本文,你应该能回答
- Personal Agent OS 的主要风险面在哪里?
- auth、permission、sandbox、audit 各自解决什么问题?
- 为什么运维能力会影响安全?
- 如何避免插件、工具和渠道互相扩大权限?
本篇在系列中的位置
治理篇,解释当 Agent 能跨渠道和设备行动时,安全不再是附加功能。OpenClaw 101 的主线是:先看控制面,再看执行面和状态边界,再进入上下文、能力系统、长期记忆、自动化、真实设备、扩展和 QA。下一篇进入 Building Extensions,看安全边界如何影响插件和扩展设计。
贯穿案例
后文会反复使用同一个任务来落地抽象机制:用户在手机上对 OpenClaw 说:“帮我看一下这个 repo 的测试为什么失败;如果需要跑命令就先做,修好后在聊天里提醒我。”
在本篇中,重点观察这个任务在 Security and Operations 这一层会遇到的边界:谁接收它,谁拥有状态,谁能触发工具,谁记录结果,以及失败后从哪里恢复。
安全控制表
| 环节 | 读者应该抓住的问题 |
|---|---|
| Authentication | 确认是谁或哪个节点正在接入 |
| Authorization | 决定这个入口能做哪些动作 |
| Sandbox | 限制工具和命令的执行范围 |
| Audit | 记录谁在何时触发了什么副作用 |
| Operations | 健康检查、重启、配置和错误恢复 |
核心判断
Gateway auth 管入口,pairing 管设备,allowFrom 管消息来源,tool policy 管模型可见动作,sandbox/approval 管主机副作用。
如果只看表面,很多 Agent 框架都像是“模型 + 工具 + UI”。但真正决定系统稳定性的,是这些边界如何被拆开:谁拥有状态,谁能触发副作用,谁负责恢复,谁暴露观察面,谁承担长期维护成本。
在 OpenClaw 里,Security and Operations 不是一个孤立模块,而是 Gateway、Session、Context、Tools、Plugins、Memory 之间的连接点。理解这个连接点,比记住某个命令或配置项更重要。
运行路径
一条真实消息进入系统后,大致会经过这些步骤:
- 限制哪些聊天 sender 可以触发 Agent。
- Gateway connect 做 auth 和 device pairing。
- Secrets 通过配置引用,而不是写进文章、prompt 或源码。
- Tool policy 在模型调用前裁剪可见工具。
- Sandbox 限制文件和进程边界。
- Exec approvals 对高风险 shell 命令做人类确认或 allowlist。
- security audit、doctor、status 帮助检查配置和运行状态。
- launchd/systemd 等 supervisor 负责长期运行和恢复。
这些步骤看起来很多,但它们解决的是同一个问题:让 Agent 的行为从“模型临场发挥”变成“系统可控制、可观察、可恢复的运行过程”。
可迁移伪实现:Security and Operations
下面的伪代码是机制抽象,不对应 OpenClaw 的真实 API 或文件结构。
function authorizeTurn(input, runtime) {
assertAllowedSender(input.sender)
assertGatewayAuth(runtime.connection)
const tools = filterTools({
profile: runtime.profile,
sandbox: runtime.sandbox,
channel: input.channel,
})
return { tools, approvalPolicy: loadExecPolicy() }
}
这段伪代码的重点不是函数名,而是边界:输入先被标准化,状态通过明确的 store 或 lane 管理,副作用通过 runtime 或 policy 执行,结果再回到 transcript、event stream 或 delivery target。
设计取舍
- YOLO 模式适合受控开发环境,不适合公开入口。
- 过宽工具暴露不仅危险,也浪费上下文。
- 安全配置要能被解释;否则用户无法知道 Agent 为什么能做或不能做某事。
这些取舍解释了 OpenClaw 为什么不像一个最小 demo。最小 demo 追求路径短,长期系统追求边界清晰。路径短会让第一个 demo 很快跑起来;边界清晰才会让系统在多渠道、长会话、多人入口、插件扩展和自动化场景下不崩。
评估清单
评估任何 Agent 框架的 Security and Operations 设计,可以看这几个问题:
- 这个层级是否有明确 owner,还是散落在多个客户端或插件里?
- 它是否把状态、权限、运行时副作用和展示逻辑分开?
- 它是否能被观测、被调试、被回放?
- 它失败时是否有恢复路径,而不是只给用户一个模型错误?
- 它是否避免把 provider/channel/tool 的私有细节写死进 core?
如果这些问题没有答案,系统一旦从单用户 demo 走向真实使用,很快就会在上下文污染、重复副作用、权限失控、长任务丢失和调试困难中付出代价。
下一篇
下一篇继续拆 Building Extensions。OpenClaw 101 的主线会继续沿着 Personal Agent OS 的边界往下走:从运行时,到状态,到能力系统,再到安全、扩展和 QA。
References
- Security
- Exec approvals
- Sandbox vs tool policy vs elevated
- Secrets
- Gateway configuration