OpenClaw 101|01|Personal Agent OS
OpenClaw 不只是聊天机器人外壳,而是一套 Personal Agent OS:用 Gateway、Session、Agent Runtime、Context 和 Capability System 组织长期运行的个人 Agent。
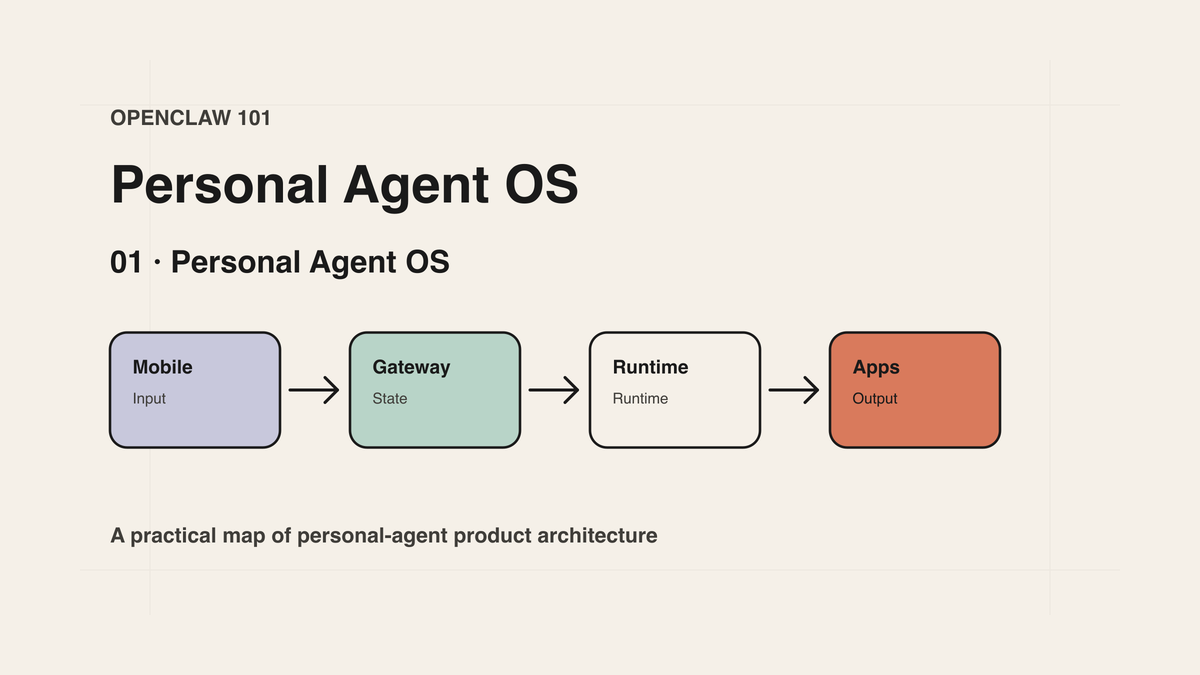
如果把 Agent 理解成“一个模型,加上一组工具,再套一个循环”,我们很快会撞到天花板。
这个定义适合解释 demo,却解释不了真实使用中的问题:
- 用户从 Telegram、Slack、Discord、iMessage、Web UI、CLI 同时找它,谁拥有上下文?
- 模型一边流式输出,一边调用工具,一边又收到新消息,谁来决定排队、打断、合并?
- Agent 读过的文件、跑过的命令、保存过的记忆,哪些应该进下一轮 context?
- 一个能发消息、读文件、跑 shell、连移动设备的系统,安全边界在哪里?
- 长期运行几周之后,session、memory、logs、plugins、credentials 谁来维护?
OpenClaw 有趣的地方,不在于它又做了一个聊天助手,而在于它把这些问题当成系统问题处理。它更接近一个 Personal Agent OS:一个常驻的个人 Agent 操作层,把模型、工具、消息渠道、设备节点、记忆、自动化和扩展能力组织在一起。
这篇先建立总图。后面的文章再一层一层拆。
读完本文,你应该能回答
- 为什么 OpenClaw 更像 Personal Agent OS,而不是聊天机器人外壳?
- Gateway、Session、Agent Runtime、Context、Capability System 分别解决什么问题?
- 一个长期运行的个人 Agent 最容易在哪些边界上失控?
- 后面 14 篇应该按什么主线阅读?
本篇在系列中的位置
总览篇,建立整套系统的五层模型。OpenClaw 101 的主线是:先看控制面,再看执行面和状态边界,再进入上下文、能力系统、长期记忆、自动化、真实设备、扩展和 QA。下一篇进入 Gateway,解释为什么所有入口都要先汇聚到常驻控制面。
贯穿案例
后文会反复使用同一个任务来落地抽象机制:用户在手机上对 OpenClaw 说:“帮我看一下这个 repo 的测试为什么失败;如果需要跑命令就先做,修好后在聊天里提醒我。”
在本篇中,重点观察这个任务在 Personal Agent OS 这一层会遇到的边界:谁接收它,谁拥有状态,谁能触发工具,谁记录结果,以及失败后从哪里恢复。
阅读地图
| 环节 | 读者应该抓住的问题 |
|---|---|
| 用户入口 | 手机/聊天渠道里发起一个真实任务 |
| 控制面 | Gateway 接收、鉴权、路由并创建 run |
| 状态边界 | Session 决定历史、并发和隐私边界 |
| 执行面 | Agent Runtime 组装 context、调用模型和工具 |
| 长期性 | Memory、Automation、Nodes、QA 让系统持续运行 |
核心判断
OpenClaw 的核心不是“聊天 UI”,而是五个边界:
- Gateway:常驻控制面,连接渠道、客户端、节点、自动化和 Agent Runtime。
- Session:状态边界,决定一条消息进入哪段历史、哪条队列、哪个 transcript。
- Agent Runtime:执行面,负责 context assembly、model inference、tool execution、streaming 和 persistence。
- Context:每一轮真正发给模型的全部输入,包括 system prompt、历史、工具 schema、工具结果、workspace 注入和 compacted summary。
- Capability System:能力系统,由 tools、skills、plugins 组成。tools 让 Agent 行动,skills 教 Agent 方法,plugins 扩展运行时。
这五层合起来,才构成一个可以长期运行的个人 Agent 系统。
为什么需要 OS 层
一个单文件 Agent 循环大概长这样:
下面的伪代码是机制抽象,不对应 OpenClaw 的真实 API 或文件结构。
while (true) {
const input = await readUserMessage()
const context = [...history, input]
const output = await model.generate({ context, tools })
if (output.toolCall) {
const result = await callTool(output.toolCall)
history.push(result)
continue
}
await sendReply(output.text)
history.push(output)
}
这段代码很适合教学,因为它展示了 Agent 的最小骨架:input、model、tool、reply。
但真实的个人助手不是这样工作的。
真实世界里的输入不是一个 stdin,而是多个渠道:私聊、群聊、频道、Web UI、CLI、自动化任务、webhook、移动设备事件。真实世界里的输出也不是一个 print,而是有消息长度限制、threading、reply target、附件、撤回、编辑、typing indicator、流式草稿和失败重试。
更麻烦的是,真实用户不会等 Agent 做完一件事再说下一句。用户会追加信息、纠正方向、发图片、在另一个渠道继续问、要求停下、让它把结果发到群里。与此同时,后台 cron 可能在跑,另一个 session 可能在做长任务,某个插件可能在拦截工具调用,memory flush 可能在 compaction 前静默执行。
所以 Personal Agent 需要一个 OS layer:
- 统一接入输入输出。
- 统一管理状态和并发。
- 统一构建模型上下文。
- 统一执行工具和扩展。
- 统一处理安全、权限、日志、恢复。
OpenClaw 的设计可以从这个角度理解。
五层心智模型
OpenClaw 可以被压缩成一张五层图:
Channels / Apps / Nodes / Automation
↓
Gateway
↓
Session
↓
Agent Runtime
↓
Models / Tools / Plugins / Memory
更准确一点:
Inbound message
-> Gateway routing
-> session key
-> queue policy
-> context assembly
-> model inference
-> tool execution
-> streaming events
-> transcript persistence
-> outbound delivery
每一层解决的问题不同。
Gateway 解决“世界如何进来、结果如何出去”。
Session 解决“这属于哪段对话、是否允许并发、历史存在哪里”。
Agent Runtime 解决“这一轮怎么跑完”。
Context 解决“模型到底看到了什么”。
Capability System 解决“Agent 能做什么,以及这些能力如何被安全地暴露”。
Gateway:常驻控制面
OpenClaw 的 Gateway 是一个长期运行的 daemon。它维护渠道连接,暴露 WebSocket API,让 CLI、Control UI、macOS/iOS/Android 节点、自动化任务都能连到同一个控制面。
这点非常关键。很多 Agent demo 是“进程即会话”:打开一个 CLI,聊完就结束。OpenClaw 的心智模型更像“进程即服务”:Gateway 作为常驻中心,持续拥有连接、session store、transcripts、presence、health、cron、节点能力和事件流。
Gateway 的职责包括:
- 维护消息渠道连接。
- 接收客户端 request,推送 server events。
- 处理 connect handshake、auth、pairing。
- 为 side-effecting methods 做 idempotency。
- 把 inbound message 路由到对应 session。
- 启动 Agent run,并把 lifecycle、assistant、tool events 流式发回客户端。
- 管理节点能力,比如 screen、camera、location、canvas。
这使得 OpenClaw 不依赖某个单一 UI。CLI、Web UI、移动 App、聊天渠道、自动化任务,本质上都是 Gateway 的不同 client 或 surface。
Session:状态边界
Agent 系统最容易被低估的部分是 session。
在简单 demo 里,session 只是一个 messages array。但在真实系统里,session 至少承担五件事:
- 决定对话历史是否共享。
- 决定并发运行是否串行化。
- 决定 transcript 写到哪里。
- 决定 reset、cleanup、compaction 的范围。
- 决定回复应该回到哪个渠道或线程。
OpenClaw 对不同来源采用不同 session 路由策略:
- Direct messages 默认可以共享主 session,适合单用户个人助手。
- Groups、rooms、channels 通常按群或房间隔离。
- Cron jobs 每次运行可以是 fresh session。
- Webhooks 按 hook 隔离。
这个边界不是细节,而是隐私和稳定性的核心。如果一个多人可访问的 Agent 把所有 DM 混进同一个 session,Alice 的私人上下文就可能影响 Bob 的对话。OpenClaw 因此提供 DM isolation 选项,把 session scope 调整为 per-peer、per-channel-peer 或更细粒度。
Session 也是并发边界。一个 session 中同时跑两个 Agent turn,很容易造成 transcript 乱序、工具结果错位、上下文不一致。所以 OpenClaw 会把 run 串行化:同一 session 的工作进入同一条 lane,必要时再经过 global lane。
Agent Runtime:执行面
OpenClaw 的 Agent Runtime 不是“调用一次模型”。它是一条完整流水线:
type AgentRun = {
runId: string
sessionKey: string
input: Message
model: ModelRef
tools: ToolDescriptor[]
}
async function runAgentTurn(run: AgentRun) {
await acquireSessionLane(run.sessionKey)
await acquireTranscriptWriteLock(run.sessionKey)
const session = await loadSession(run.sessionKey)
const skills = await loadSkillSnapshot(session)
const systemPrompt = await buildSystemPrompt({ session, skills })
const context = await assembleContext({ session, systemPrompt })
const stream = model.stream({
model: run.model,
messages: context.messages,
tools: run.tools,
})
for await (const event of stream) {
if (event.type === "assistant_delta") {
emitAgentEvent("assistant", event)
}
if (event.type === "tool_call") {
emitAgentEvent("tool", { phase: "start", call: event.call })
const result = await executeTool(event.call)
await appendToolResult(session, result)
emitAgentEvent("tool", { phase: "end", result })
}
}
await persistTranscript(session)
emitAgentEvent("lifecycle", { phase: "end", runId: run.runId })
}
真实实现当然更复杂:model fallback、auth profile rotation、tool result sanitization、stream chunking、timeouts、abort signals、compaction retries、plugin hooks 都会参与。但这个伪代码能表达关键点:Agent run 是一个被 Gateway 接受、被 Session 串行化、被 Runtime 执行、被 Transcript 记录、被 Events 观察的完整过程。
OpenClaw 还把 agent 和 agent.wait 区分开:
agentrequest 可以先返回 accepted,告诉客户端 run 已经开始。- agent events 负责持续推送 streaming 过程。
agent.wait可以等待 run 的 lifecycle end/error。
这是一种更接近后台任务系统的设计,而不是同步 RPC。
Context:模型真正看到什么
“上下文”不是一句抽象概念。对 Agent 来说,context 是每一轮真正发送给模型的全部输入。
它通常包括:
- OpenClaw 构建的 system prompt。
- 当前 session 的 conversation history。
- 工具调用和工具结果。
- 可见工具的 JSON schemas。
- workspace bootstrap files。
- skills list。
- compaction summaries。
- attachments、media transcripts、channel metadata。
这里有两个容易混淆的点。
第一,memory 不等于 context。Memory 是存储在磁盘或 memory backend 里的长期材料;context 是这一轮模型窗口里实际出现的材料。一个事实写进了 memory,不代表每次都会完整进入 context。它可能需要被搜索、召回、压缩、注入。
第二,tools 也有 context 成本。即使工具没有被调用,它的 schema 也可能被发给模型,占用上下文窗口。工具越多,Agent 越强,但 prompt 成本和选择噪声也越高。因此 OpenClaw 需要 tool policy、provider restrictions、tool search、plugin enablement 等机制来控制暴露面。
这也是为什么 OpenClaw 提供 /status、/context list、/context detail、/compact 这类操作。一个成熟 Agent 框架必须让上下文可观察,否则“模型为什么知道这个 / 忘了那个”就只能靠猜。
Tools、Skills、Plugins
OpenClaw 的能力系统可以用一句话区分:
- Tool 是 Agent 可以调用的动作。
- Skill 是 Agent 应该遵循的工作方法。
- Plugin 是 OpenClaw 运行时的新能力。
比如:
- 读文件、跑命令、搜索网页、发消息,是 tools。
- “如何做代码审查”“如何发布文章”“如何处理某个项目的部署”,是 skills。
- 新增一个聊天渠道、模型 provider、memory backend、web search provider、speech provider,是 plugins。
这个三分法很重要。很多系统会把所有东西都塞进 tool,结果 tool 变成既有执行代码、又有 prompt 指令、又有配置约定、又有第三方 SDK 生命周期的混合物。OpenClaw 把它拆开:
- 工具暴露给模型,必须可描述、可授权、可审计。
- 技能进入 prompt,主要影响 Agent 的行为策略。
- 插件进入 runtime,负责注册能力、加载依赖、管理 manifest、提供 hooks。
插件系统尤其体现 OpenClaw 的工程取舍。它倾向 manifest-first:先通过 manifest 做 discovery、validation、setup hints、activation planning,尽量不要为了回答“这个插件是否存在、是否负责某能力”就加载整个 runtime。
这对长期运行系统很关键。插件一多,如果每次启动或每次请求都 eager load 所有 provider、channel、SDK,启动成本、内存、失败面都会迅速膨胀。
Channels 不是文本管道
一个聊天渠道不是简单的 text input/output。
真实渠道会带来一堆系统问题:
- 消息可能重投,需要 dedupe。
- 用户可能连续发几句,需要 debounce。
- 群聊里只有 mention 或特定前缀才触发。
- group history 和 current message 要分开包装。
- 回复可能要挂在线程、引用原消息、带附件。
- 平台有消息长度限制,需要 chunking。
- 流式输出可能要变成草稿、typing indicator 或分块消息。
- 某些场景需要允许 silent reply。
所以 OpenClaw 把 message flow 拆成:
Inbound message
-> routing / bindings
-> session key
-> queue mode
-> agent run
-> outbound replies
-> channel-specific delivery
这里的 queue mode 也很有意思。如果一个 session 已经在运行,新消息怎么办?
- steer:把新消息导入当前 run 的下一个模型边界。
- followup:等当前 run 完成后追加一轮。
- collect:收集多条后合成后续一轮。
- interrupt:中断当前 run。
这不是 UI 小功能,而是 Agent 与人协作的核心交互模型。
Memory
如果 Agent 只活十分钟,memory 可以不重要。一个个人助手如果活几个月,memory 就是系统生命线。
OpenClaw 的 memory 设计有一个朴素但重要的原则:没有神秘隐藏状态。重要信息需要被写入可检查的存储层,例如 Markdown memory、daily notes、Dream Diary,或者由 memory plugin 管理的索引和检索后端。
它区分:
- Durable facts:长期偏好、身份、稳定决策,适合进入 curated memory。
- Daily notes:当天上下文、临时观察、过程记录,适合进入 daily memory。
- Searchable memory:通过 keyword、embedding、hybrid search 找回。
- Dreaming / consolidation:后台整理和提升长期价值信息。
更关键的是,OpenClaw 把 memory 和 compaction 连起来。长对话压缩前,如果有重要事实还只存在于上下文里,compaction 可能把细节丢掉。因此它会在 compaction 前触发 memory flush,让 Agent 有机会先把重要信息写入长期层。
这是一种很务实的设计:长期记忆不是一次模型调用解决的,而是一组反复运行的整理机制。
主要取舍
OpenClaw 的主取舍可以总结为:把个人 Agent 当作一个长期运行的操作系统,而不是一次性应用。
这带来好处:
- 多渠道可以共享一个稳定控制面。
- session、context、memory、tools 都可观察。
- 插件可以扩展 runtime,而不必改 core。
- 自动化和节点能力可以接入同一套协议。
- 长任务、流式输出、排队、中断、恢复都有位置。
也带来复杂度:
- Gateway 必须常驻并被运维。
- session routing 和 isolation 必须设计清楚。
- tool policy、sandbox、auth、pairing 不能偷懒。
- context 成本必须持续管理。
- plugin 边界必须克制,否则 core 会被 provider/channel 细节污染。
这正是 OpenClaw 值得作为 101 系列样本的原因。它不是最小 Agent,而是一个把“Agent 如何进入真实生活”这个问题摊开的工程案例。
评估清单
读完 OpenClaw 的总图后,可以用这组问题评估任何 Agent 框架:
- 它有没有常驻控制面?还是每个客户端各跑各的?
- 它的 session 边界是什么?DM、群聊、自动化是否隔离?
- 它如何处理 active run 中的新消息?
- 它能不能解释模型这一轮到底看到了什么?
- 工具 schema 成本是否可见?
- 工具权限、sandbox、approval、channel permissions 是否分层?
- memory 是可检查的,还是隐藏在不可控状态里?
- compaction 前是否有 memory flush?
- 插件是 manifest-first,还是启动时加载所有 runtime?
- 出错时能不能从 transcript、events、logs 复现?
这些问题比“支持多少模型”更重要。模型会变,但这些系统边界决定 Agent 能不能长期可靠运行。
下一篇
下一篇会拆 Gateway。
Gateway 是 OpenClaw 的控制面:它用 WebSocket 把 CLI、Control UI、Apps、Nodes、Channels、Cron 和 Agent Runtime 接到一起。理解 Gateway,才能理解 OpenClaw 为什么不是一个聊天机器人,而是一个可以持续运行的 Personal Agent OS。
References
- OpenClaw README
- Gateway architecture
- Agent runtime
- Agent loop
- Session management
- Context
- Messages
- Tools overview
- Plugin internals
- Memory overview