先定义问题:这不是代码补全产品
把 Lovable、Bolt.new、Replit Agent、v0 放在一起看,会发现它们已经不是“AI 帮你写几段代码”的产品。
它们做的是另一件事:用户用自然语言描述一个需求,系统把这个需求推进成一个可以预览、修改、发布、协作和治理的应用。代码当然存在,但对大多数 builder 来说,代码只是中间形态。最后交付给用户的,是一个能打开、能用、能继续迭代的产品。
所以这类产品不能只看 MAU、prompt 数、生成次数或 token 消耗。MAU 可能只是好奇心,prompt 数可能是失败重试,token 消耗甚至可能是上下文浪费。
更应该问的是这些问题:
- 用户有没有拿到第一个可用预览;
- 预览有没有继续走到发布;
- 发布之后有没有人访问、分享、协作或再次编辑;
- 每一次成功发布的模型成本、运行成本和安全风险是否可控。
这篇文章讨论的就是这套指标系统。竞品和 benchmark 只是背景,要解决的问题只有一个:AI app builder 怎么把“从想法到可运营应用”的链路变成可度量、可诊断、可经营的系统。
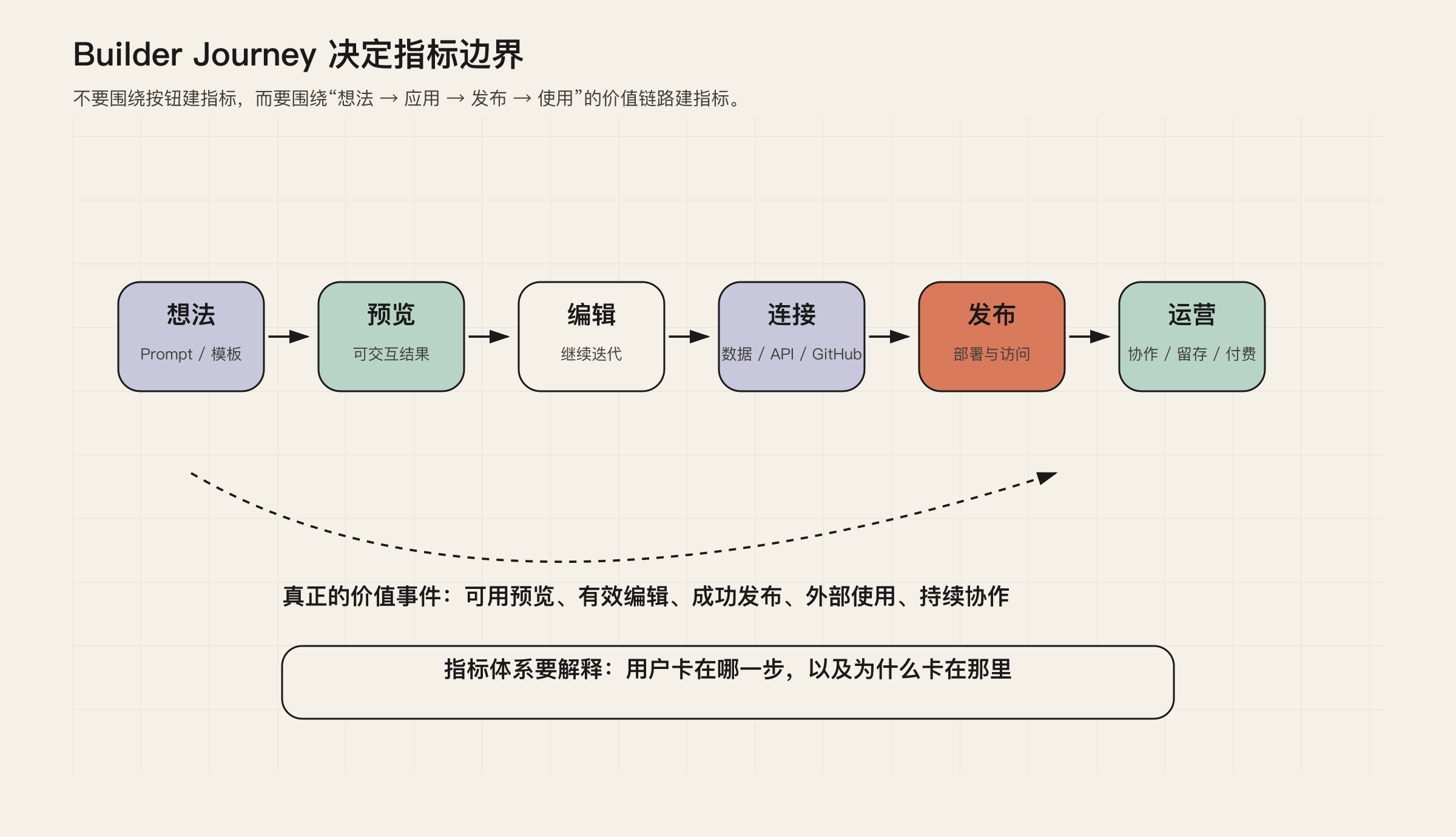
图 1:指标体系应从 Builder Journey 出发,而不是从页面按钮或模型调用出发。
如果团队内部正在争论“到底该看活跃、看生成、看发布,还是看收入”,可以先从这张旅程图开始。它把讨论从功能清单拉回用户结果:用户不是来消耗 token 的,用户是来把一个想法做成东西的。
赛道基线:头部产品已经从生成走向发布和治理
Lovable、Bolt.new、Replit Agent 和 v0 的公开动作指向同一个方向:生成只是入口,后面必须接协作、部署、治理、计费和企业控制面。
Lovable:从 idea to app 到团队治理
Lovable 的公开叙事很清楚:它不是一个代码片段生成器,而是 full-stack AI development platform。它强调自然语言构建、迭代、部署 web app,同时接入真实代码、GitHub 同步、工作区协作和企业治理。
公开信息里最值得关注的不是某个单点功能,而是它把产品链路做成了闭环:生成、预览、部署、云数据库、认证、存储、edge functions、安全扫描、SSO、审计日志。
对指标体系来说,这意味着安全扫描、代码可携带性、协作权限这些东西不能只放在企业版介绍页里。它们会影响发布率、团队转化和留存。
Bolt.new:大方免费层背后是 token 经济学
Bolt.new 的首页和文档都强调“和 AI 聊天构建 apps 和 websites”。但更重要的是,它把 Figma、GitHub、Bolt Cloud、database、hosting、domain、analytics、design system 接入主路径。
Bolt 的定价也说明了另一个事实:AI app builder 的成本不是固定的。项目越大,每轮需要同步给模型的文件系统越重,每次生成的 token 和工具执行成本就越高。
“无限生成”很适合拉新,但很难长期负责。只要项目变大,成本就会沿着上下文和工具执行往上走。这里必须看 cost per successful publish,而不是只看 token 总量。
Replit Agent:agentic workflow 与基础设施一体化
Replit 的优势不只是 Agent,而是 Agent、Publish、Authentication、Database、Hosting、Monitoring、Integrations 和 Enterprise control 的组合。
如果一个产品要从个人试玩走向工作流,基础设施就不能让用户自己拼。生成只是第一步,发布、运行、监控、修复和治理,才决定它会不会被长期使用。
v0:从原型工具走向 business-critical
v0 的新方向尤其值得注意。它不再只是“生成 UI”或“vibe coding”,而是导入任意 GitHub repo、按 chat 建 branch、发 PR、merge 后部署。
这里的产品判断很清楚:有预算的场景通常不是凭空生成一个 demo,而是让 AI 进入已有代码库、开发流程、权限体系和部署链路。
共同趋势:seat + usage 的混合定价
四类产品还有一个一致趋势:从统一月费走向 seat + usage 的混合定价。
- seat 反映团队协作、权限、治理和组织价值;
- usage 反映模型、上下文、工具执行、构建、预览和部署的可变成本;
- top-up 或 effort pricing 让高频、复杂任务的成本更可控。
这对指标体系的含义是:不要只看收入,也不要只看 token。最关键的是把收入、使用量和成功结果连起来:
成功发布是否增长?每次成功发布成本是否下降?激活用户是否留存并付费?
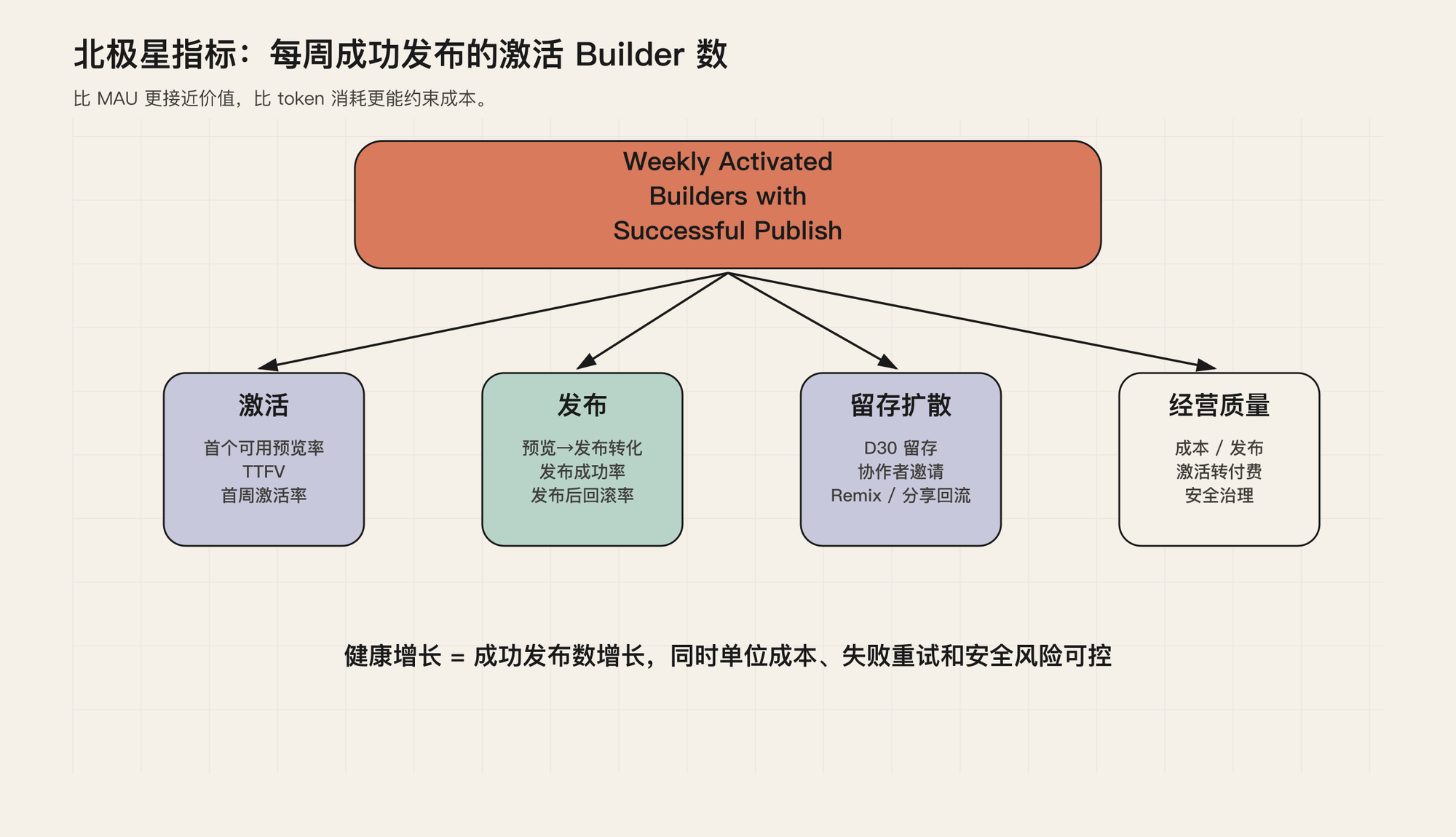
北极星指标:每周成功发布的激活 Builder 数
对 Lovable 类产品,最合适的北极星指标不是 MAU,也不是 prompt 数,而是:
每周成功发布的激活 Builder 数。
这句话需要拆开看。
Builder 不是普通访客,而是确实尝试构建应用的人。激活也不是登录,而是拿到过可用预览、完成过有效编辑,或者发布过项目。成功发布则要比“代码生成成功”更严格:构建通过,部署完成,访问地址生效,基础安全和运行检查没有阻断。
这个指标之所以比 MAU 更有用,是因为它直接贴着产品承诺走。用户来过不算数,做出可运行应用才算数。它也比收入更早。收入通常滞后,但首个预览、首次发布和再次回访会更早暴露产品质量。
更重要的是,它会逼团队同时看增长和成本。生成次数上涨不一定是好事;成功发布数上涨,同时单次成功发布成本下降,才是健康信号。
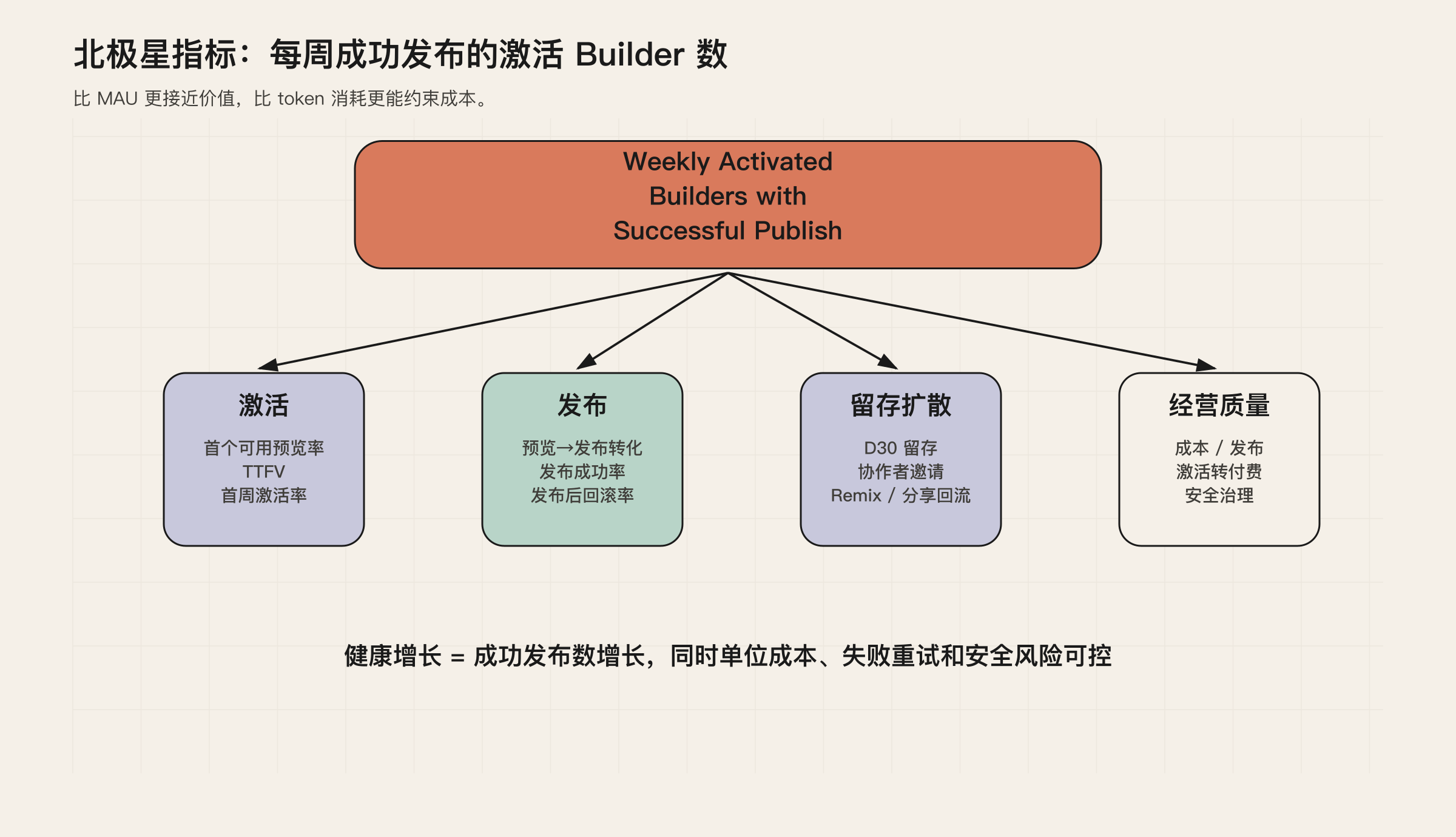
图 2:北极星指标把激活、发布、留存扩散和经营质量连接在一起。
围绕这个北极星,可以建立四个一级分解:
- 激活:有多少用户从想法走到第一个可用预览;
- 发布:有多少预览继续走到可访问应用;
- 留存与扩散:发布后是否有人回来、分享、协作、remix;
- 经营质量:每次成功发布的成本、付费转化、安全风险是否可控。
如果只能先搭一个最小可用的指标系统,先建四个数就够:
- 每周成功发布的激活 Builder 数:判断产品是否在创造真实价值;
- 首个可用预览率:判断新用户是否能快速获得信任;
- 预览到发布转化率:判断产品是否真的跨过 demo 阶段;
- 每次成功发布成本:判断增长是否具备商业可持续性。
这四个数一起看,能避免三种误判:MAU 很高但没人做出东西,生成很多但发布很少,收入增长但模型成本吞掉毛利。
指标体系的七层结构
不要把指标体系做成一张大表。大表看起来完整,但很难指导决策。更合适的方式是分层。
对 Lovable 类产品,可以分成七层:
- 增长入口指标:谁来了,从哪里来,带着什么意图来;
- 激活指标:用户是否拿到第一个可信结果;
- 生成体验指标:生成是否快、稳、可恢复、可继续编辑;
- 发布指标:结果是否能部署上线;
- 留存与协作指标:项目是否持续被使用和传播;
- 商业化与成本指标:收入是否覆盖生成、运行和支持成本;
- 安全与治理指标:发布出来的应用是否可控、可审计、可进入团队工作流。
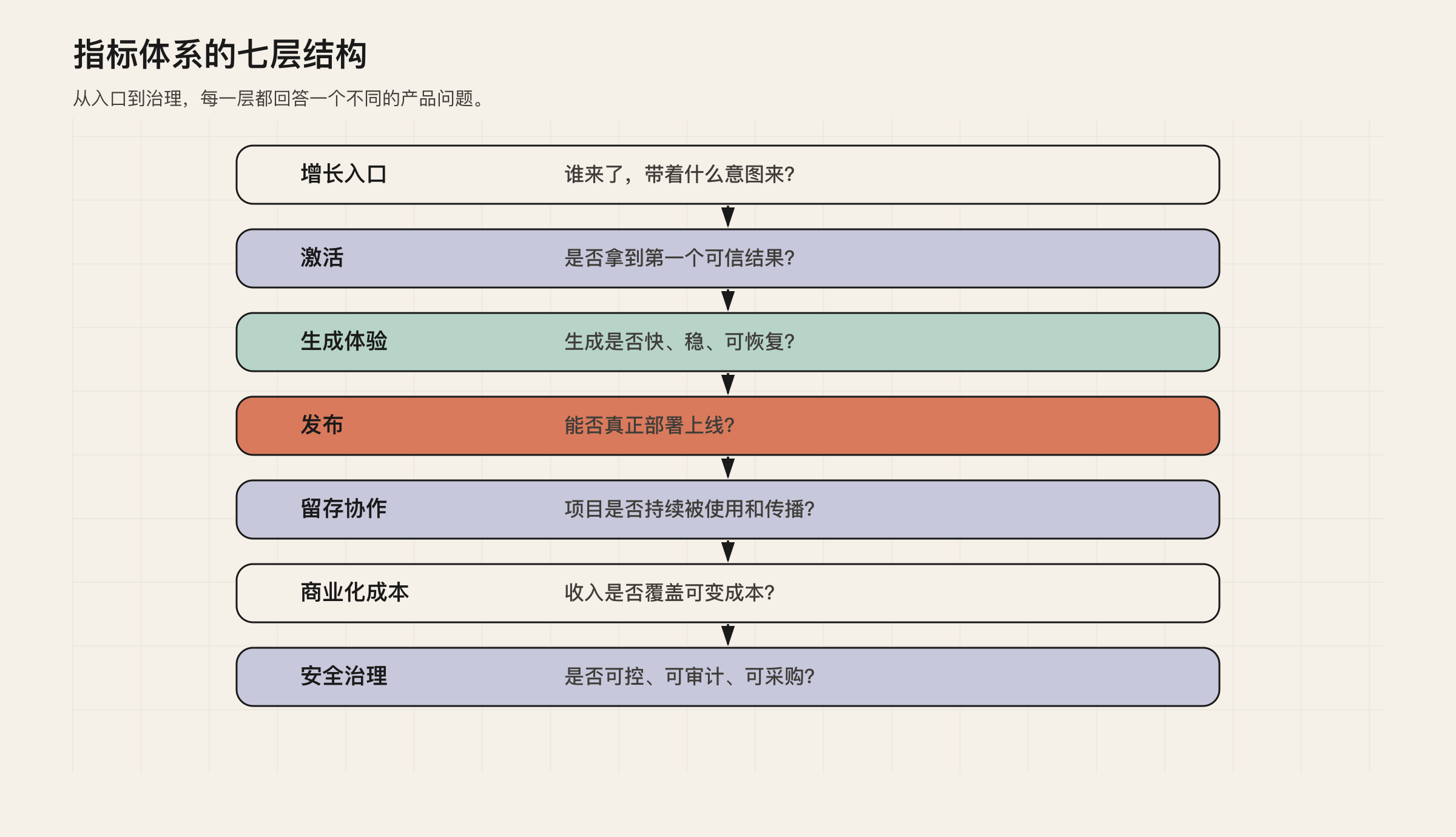
图 3:七层指标结构从用户入口一路延伸到成本、安全和治理。
这七层不是并列 KPI。它们更像一条因果链。
增长入口决定用户质量;激活决定用户是否相信产品;生成体验决定用户是否愿意继续迭代;发布决定产品是否交付真实结果;协作扩散决定增长是否自然发生;商业化和成本决定业务是否可持续;安全治理决定产品能否进入团队与企业场景。
从产品判断上,可以把 AI app builder 分成三种状态:
- 热闹但浅:注册、prompt、token 都在涨,但首个可用预览率和发布率不涨;
- 能交付但不稳定:预览和发布能跑起来,但回滚率、重复修复、成本和安全阻断很高;
- 可经营:成功发布持续增长,激活用户留存和付费提升,单位成本下降,安全与治理进入默认发布链路。
指标体系不是为了证明自己很好看,而是为了尽快看出产品卡在哪一种状态里。
第一层:增长入口指标
增长入口指标的作用不是证明“来了多少人”,而是解释“来了什么样的人”。
这一层至少要看:
- 新增注册用户;
- 来源渠道:自然搜索、社媒分享、模板市场、邀请、广告、开发者社区;
- 首次进入意图:建站、内部工具、表单、dashboard、电商、内容站、原型、自动化流程;
- 首次选择路径:空白 prompt、模板、导入 Figma、导入 GitHub、复制 demo、remix 项目;
- 首次任务复杂度:简单页面、标准 CRUD、多页面应用、带权限应用、带外部 API 应用。
这一层最容易犯的错误,是把“新增注册”当成产品质量指标。对 AI app builder 来说,新增注册更像流量指标,不是价值指标。
有用的入口分析,是把渠道和后续激活连起来看:
- 哪些渠道带来的用户首个预览率高;
- 哪些模板带来的用户发布率高;
- 哪些任务类型的用户 D30 留存高;
- 哪些入口用户付费意愿高,但生成失败率也高。
如果一个渠道注册很多,但首个可用预览率极低,它不是增长资产,而是支持成本和模型成本的来源。
第二层:激活指标
激活是 Lovable 类产品最容易被低估的一层。
传统 SaaS 的激活可能是“创建项目”“邀请同事”“完成设置”。但 AI app builder 的激活必须绑定结果事件,而不是配置事件。
激活可以这样定义:
用户在首次使用周期内,完成一个能让他相信产品有用的应用生成结果。
首个可用预览率
首次 prompt 后,在限定时间内拿到可交互预览的用户占比。
可以先把目标放在 ≥ 65%。
TTFV:Time to First Value
从注册或首次 prompt 到第一个可用预览的时间。
一个偏进取但仍可执行的目标是:中位数 ≤ 10 分钟,P90 ≤ 25 分钟。
首周激活率
注册后 7 天内完成首次可用预览、有效编辑或成功发布的用户占比。
可以先盯 8%–12%。公开产品基准里,day-7 return 达到 7% 已经是很强信号;AI app builder 更应该把 day-7 return 绑定到价值事件,而不是登录。
首个失败恢复率
用户第一次遇到生成失败、预览失败、构建失败后,最终恢复并继续完成预览或发布的比例。
这个指标非常关键。AI 产品一定会失败,决定体验的不是“是否永不失败”,而是失败之后是否能解释、修复、回到主路径。
激活层的 dashboard 不应该只是一条漏斗,而应该能回答:
- 用户在哪一步第一次失败;
- 失败是模型问题、构建问题、依赖问题、权限问题,还是需求表达问题;
- 哪些模板降低了 TTFV;
- 哪些任务类型需要更强引导;
- 首次失败后,哪些恢复机制最有效。
第三层:生成体验指标
生成体验指标衡量的是:用户提出需求后,系统把它变成应用的过程是否稳定、快速、可理解、可继续。
它不只是模型指标,而是整个生成链路指标。
生成成功率
一次生成请求最终产出可用变更的比例。注意,这里的成功不等于模型 API 返回 200,而是用户项目真的出现了可预览、可运行、可继续编辑的变化。
预览成功率
生成完成后,预览环境成功启动并可交互的比例。
编辑采纳率
用户对生成结果没有立即撤销、回滚、大幅重写,而是继续在其基础上修改的比例。
重复修复次数
同一问题在短时间内被用户反复要求修复的次数。这个指标能暴露模型幻觉、上下文丢失、工具链不稳定和状态管理问题。
上下文成本
每次有效生成使用的输入 token、项目文件上下文、检索片段、工具结果和压缩摘要成本。
很多 AI app builder 的成本失控,不是因为用户真的做了更多高价值任务,而是因为每一轮都把过多项目文件、历史消息和无关上下文塞给模型。
因此,生成体验层应该按任务复杂度、模型、provider、项目规模、连接器、用户层级分层,而不是只看全站平均。
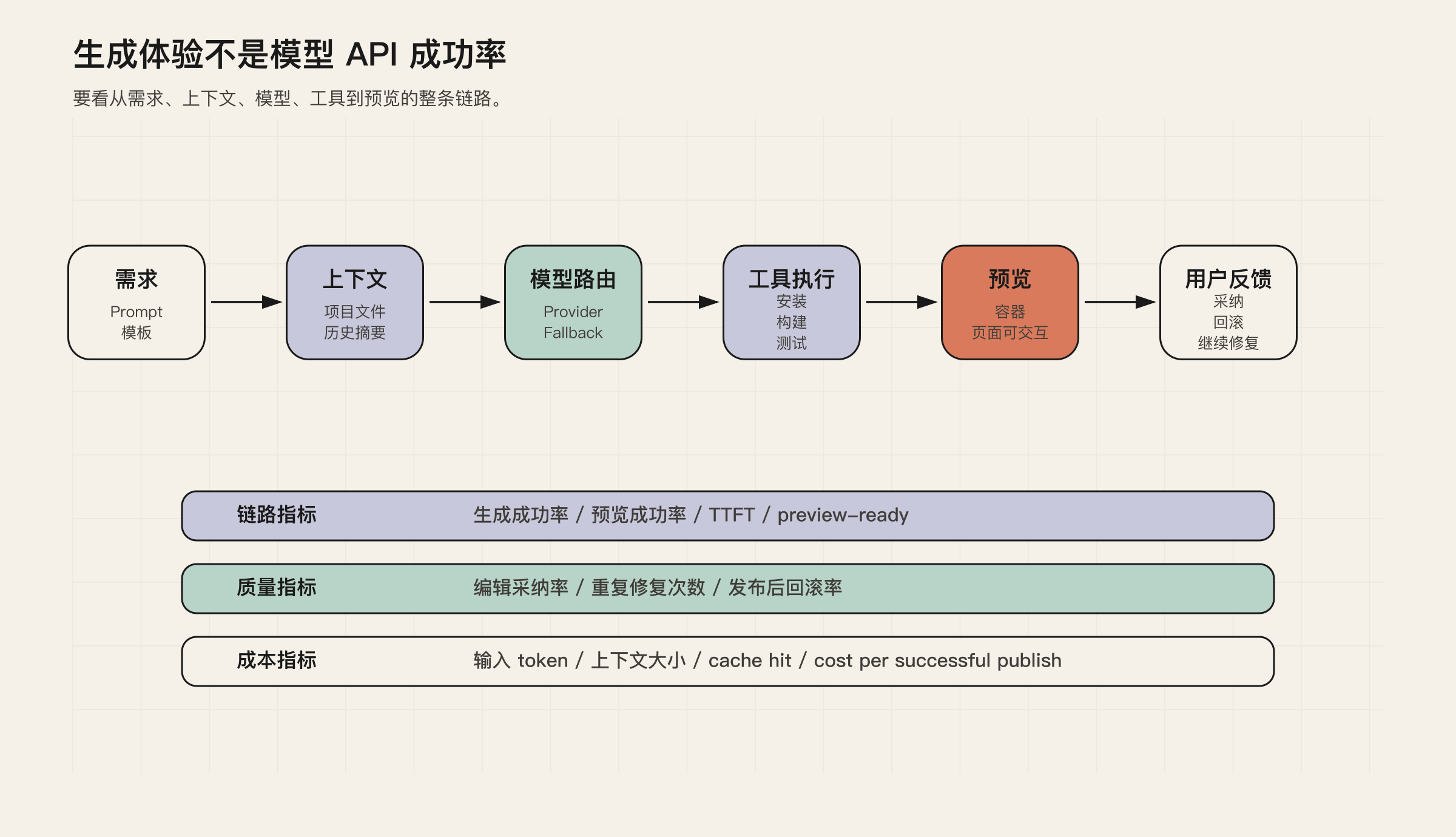
图 4:生成体验要看完整链路,不能只看模型 API 是否返回成功。
第四层:发布指标
发布是这类产品从“AI 玩具”走向“软件工具”的分水岭。
用户能看到一个 preview,并不代表他得到了一个可用产品。发布链路还包括 build、deploy、URL、域名、环境变量、数据库权限、安全扫描、运行时监控。
预览到发布转化率
拿到可用预览的用户中,有多少继续完成发布。
可以先用 15%–25% 作为目标区间。
发布成功率
发布尝试中,最终完成部署、访问地址生效、核心页面可访问的比例。
成熟的发布链路至少应该接近 ≥ 99%。
发布失败原因分布
至少要分清:构建失败、依赖失败、环境变量缺失、权限配置错误、数据库策略错误、域名错误、安全扫描阻断、运行时启动失败。
发布后回滚率
发布后 24 小时内用户主动回滚、撤销或大改的比例。
这个指标比“发布成功率”更真实。系统可以技术上发布成功,但用户发现结果不可用、不安全、不符合预期,仍然说明生成和发布质量有问题。
发布后外部访问率
成功发布的项目中,7 天内有外部访问、分享点击、嵌入使用或团队访问的比例。
发布层的关键问题是:发布不能只是一个按钮,而必须是一套产品化的交付管道。
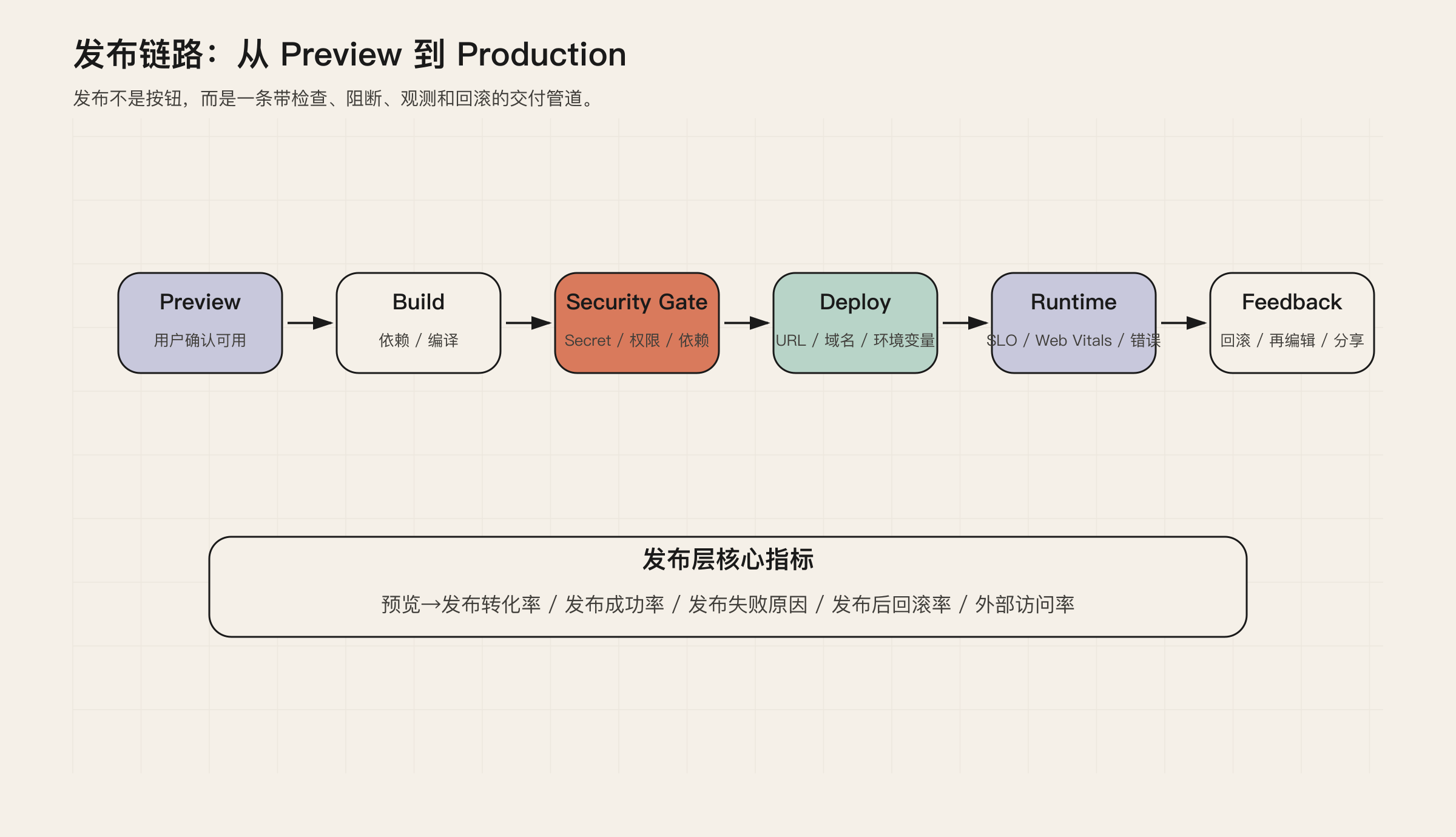
图 5:发布链路需要检查、阻断、观测和回滚能力。
第五层:留存、协作与扩散指标
Lovable 类产品的留存,不应该只看用户有没有再次登录,而要看用户是否继续围绕项目产生价值。
激活用户 D30 留存
完成首个价值事件的用户,到第 30 天仍有价值事件的比例。
可以先把 ≥ 35% 作为激活 cohort 的目标。
项目再次编辑率
发布或预览后的项目,在 7 天、30 天内再次被编辑的比例。
协作者邀请率
激活用户在 14 天内邀请协作者的比例。
可以先看 ≥ 15%。
分享回流率
分享链接、公开项目、模板页、remix 项目带来的新注册或新项目比例。
模板 / Remix 贡献率
由模板或 remix 触发的新项目占比。
可以先看 ≥ 20%。
这层指标能区分两种完全不同的产品状态。
一种是“用户来玩一次,很快离开”。这类产品可能有很高的注册和生成次数,但长期价值很弱。
另一种是“用户围绕一个项目持续迭代,并把别人带进来”。这类产品才有机会形成协作网络和团队预算。
第六层:商业化与成本指标
AI app builder 的商业化不能只看付费转化率。因为模型、工具、预览、构建、部署、运行时都会产生可变成本。
因此,收入指标必须和单位经济模型绑定。
激活转付费率
已激活用户在 30 天内进入付费计划或发生第一次 top-up 的比例。
可以先看 ≥ 8%。
Top-up 加购率
付费账户中发生 credit 或 usage 加购的比例。
可以先看 ≥ 20%。
每次成功发布成本
模型成本、工具执行成本、构建和预览成本、部署资源成本,除以成功发布项目数。
这是 AI app builder 必须单独拉出来看的经营指标。
成功发布贡献毛利
每次成功发布带来的收入或可归因价值,减去模型、工具、运行、存储、带宽和支持成本。
GRR / NRR
团队和企业计划要看收入保留。可以先用 GRR ≥ 90%,NRR ≥ 105% 做目标;成熟后再向 110% 靠拢。
这里要避免一件事:用“无限生成”掩盖成本结构。
更合理的定价结构通常是 seat + usage:席位反映团队协作价值,usage 反映模型和运行成本,top-up 反映高频或复杂使用的弹性需求。
第七层:安全与治理指标
当 AI app builder 生成的是公开应用、内部工具、数据库后台、带登录系统的业务流程时,安全治理就不再是企业版附加功能,而是发布链路的一部分。
发布前安全扫描覆盖率
已发布项目中,在发布前完成代码、依赖、secret、权限、数据库策略扫描的比例。
发布前扫描应该做到 100%。
权限策略覆盖率
含用户数据的应用中,认证、授权、RLS 或访问控制策略覆盖率。
含用户数据的应用,目标应接近 ≥ 95%。
Critical secret leak
生产环境高危密钥泄露数量。
这个指标没有灰度空间,目标就是 0。
高危漏洞逸出率
已发布项目中 critical 漏洞逃逸到生产的比例。
可以先把 < 0.5% 作为警戒线。
审计覆盖率
管理员、计费、权限、发布、数据导出等关键操作是否 100% 留痕。
安全治理层的关键是阻断能力。只提示 warning 不够,系统必须能在发布前阻断高风险项目,并给出用户能理解的修复路径。
质量评测:必须有自己的 golden task
公开编码 benchmark 有参考价值,但不能直接等同于产品质量。
原因有三点。
第一,公开 benchmark 的任务不一定对应真实用户任务。SWE-bench、Terminal-Bench 更接近工程修复或终端任务,而 AI app builder 面对的是 landing page、CRUD、auth、dashboard、content app、workflow app 这类应用构建任务。
第二,模型榜单的差异不一定能稳定迁移到自己的产品链路。不同项目栈、依赖环境、工具调用、预览容器、测试口径,都会影响结果。
第三,评测本身也有噪声。公开研究已经说明,基础设施配置会影响评测结果,benchmark 的测试和判定也可能存在误标。
因此,这类产品必须建立自己的 golden task suite。至少覆盖六类任务:
- landing page:营销页、活动页、产品介绍页;
- CRUD:列表、表单、详情、筛选、分页;
- auth:登录、注册、权限、角色;
- dashboard:图表、数据卡片、过滤器;
- content app:博客、知识库、作品集、文档站;
- workflow app:审批、任务流、状态机、通知。
评测目标可以这样定:
- simple 任务离线通过率 ≥ 80%;
- standard 任务离线通过率 ≥ 65%;
- 离线评测与线上真实成功率偏差 < 5 个百分点;
- 生成后 24 小时内用户主动回滚或大改占比 < 12%。
这里的“通过”不能只定义成测试通过或编译成功,而应该至少包含:预览可打开、主要交互可用、页面无明显破损、主要需求被满足、安全扫描无阻断项、用户可以继续迭代或发布。
事件模型:指标体系的地基
如果事件模型不清楚,指标体系一定会失真。
这些事件应该作为一级事实事件:
signupfirst_prompt_sentpreview_readypreview_failededit_appliedgeneration_failedpublish_attemptpublish_successpublish_failedruntime_requestteam_invite_sentgithub_connectedconnector_attachedsecurity_scan_passedsecurity_scan_blockedtopup_purchasedreturn_value_event
每个事件至少要带上这些属性:
- 用户层级:free、activated、paid、team、business;
- 任务类型:landing、CRUD、auth、dashboard、content、workflow;
- 项目复杂度:simple、standard、complex;
- 模型与 provider;
- 模板来源;
- 是否连接 GitHub;
- 是否连接数据库或外部数据源;
- 是否经过安全扫描;
- 失败错误码;
- 生成成本;
- 预览耗时;
- 发布时间。
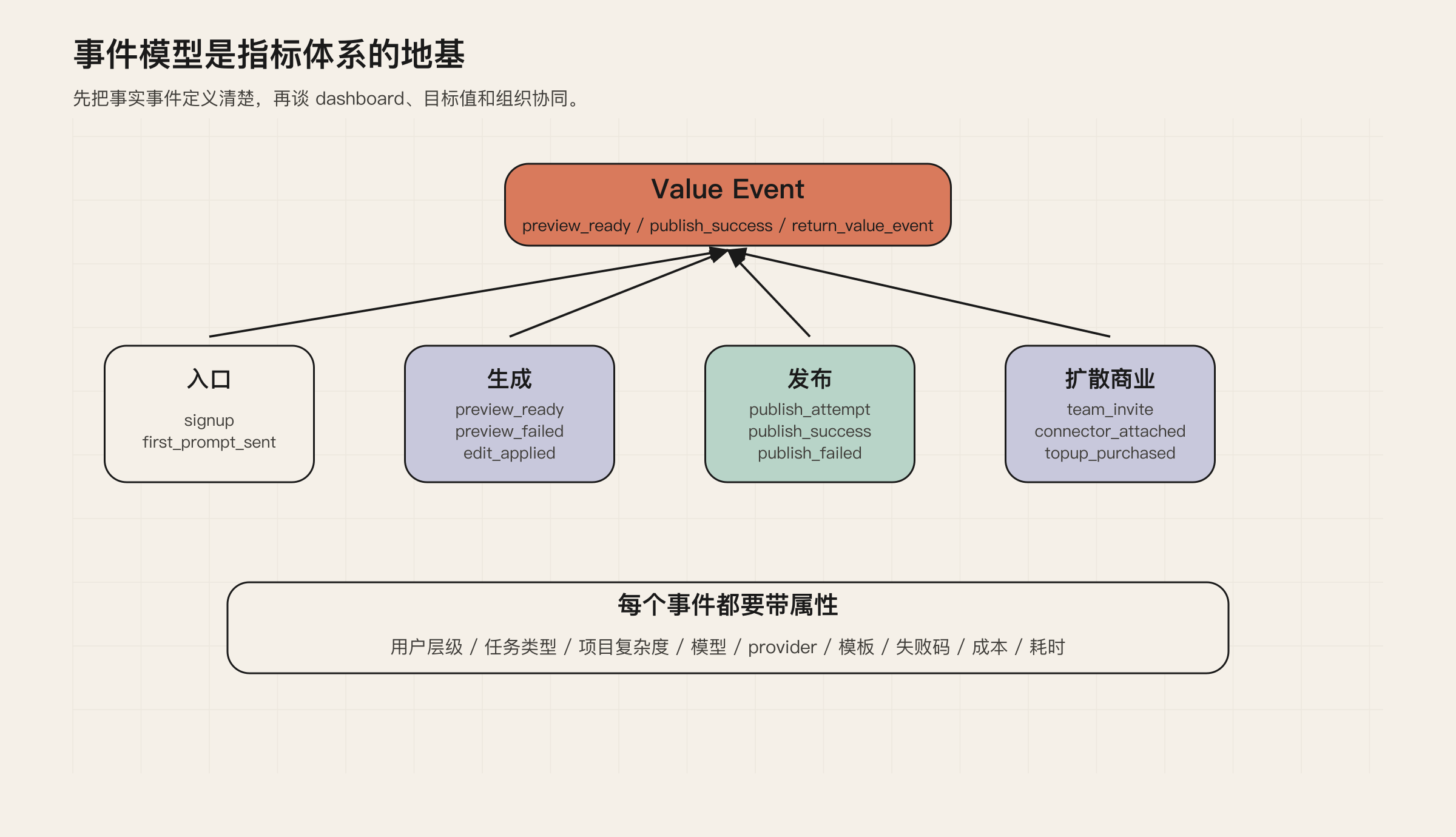
图 6:事件模型决定了后续所有指标是否可信。
active、activation、publish success、value event 这些口径要版本化管理。
否则,团队每个季度都在看“同名但不同义”的指标,最后 dashboard 会变成管理幻觉。
Dashboard:不要堆指标,要按决策场景组织
指标体系最终要落到 dashboard,但 dashboard 不是把所有图表放在一起。
可以分成五类看板。
业务总览看板
只放最关键的结果指标:每周成功发布的激活 Builder 数、首个可用预览率、预览到发布转化率、激活用户 D30 留存、激活转付费率、每次成功发布成本。
Growth / Activation 看板
关注渠道、模板、首个 prompt、首个预览、TTFV、首错原因、失败恢复率。
Generation Quality 看板
关注生成成功率、预览成功率、重复修复次数、回滚率、模型/provider 分层、golden task 通过率。
Publish / Runtime 看板
关注发布成功率、发布失败原因、运行时 SLO、Core Web Vitals、错误预算、区域和设备分层。
运行时体验至少要守住两个底线:
- 已发布应用运行时 SLO ≥ 99.95%;
- Core Web Vitals 满足 LCP ≤ 2.5s、INP ≤ 200ms、CLS ≤ 0.1,并按 75 分位评估。
Cost / Governance 看板
关注 cost per successful publish、provider mix、缓存命中率、上下文大小、安全扫描覆盖率、secret leak、权限策略覆盖率、审计日志。
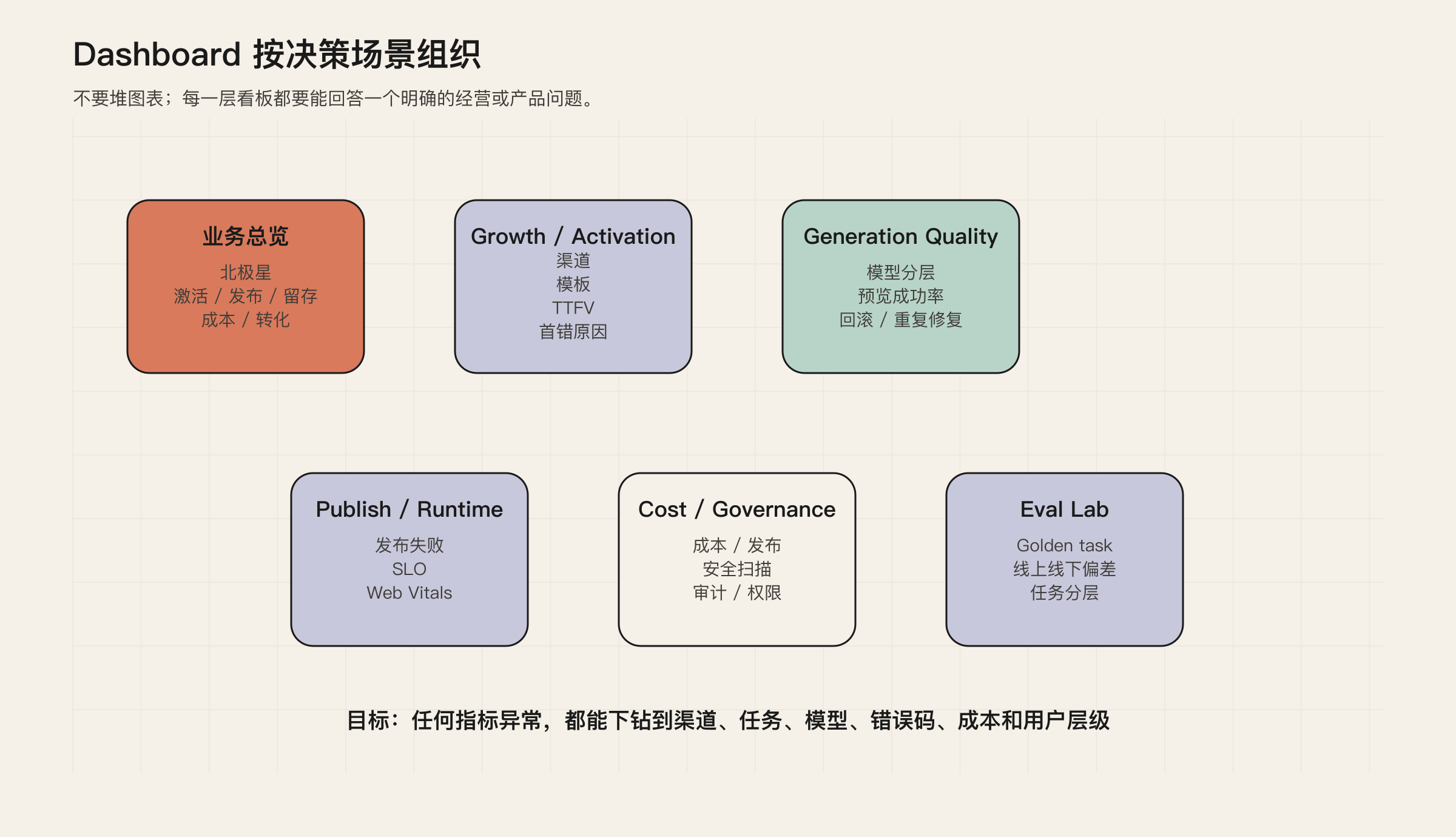
图 7:Dashboard 应按决策场景分层,而不是把所有指标堆在一起。
一个好的 dashboard 应该服务决策,而不是服务展示。
如果首个预览率下降,团队应该能立刻知道是哪个渠道、哪类任务、哪个模板、哪个模型、哪类错误导致的。
如果成本上升,团队应该能分清是高价值复杂项目增加,还是无效上下文和失败重试增加。
如果发布率下降,团队应该能分清是用户信心不足、发布流程复杂,还是安全扫描、构建系统、域名配置造成阻塞。
落地顺序
建立指标体系时,不要一上来做大而全的 BI 工程。更好的方式是分阶段推进。
第一步:统一定义
先定义四个基础口径:
- 什么叫 active;
- 什么叫 activated builder;
- 什么叫 usable preview;
- 什么叫 successful publish。
没有这四个定义,后面的指标都会失真。
第二步:打通主链路事件
优先打通:signup → first_prompt_sent → preview_ready / preview_failed → edit_applied → publish_attempt → publish_success / publish_failed。
先把主链路看清楚,再补协作、商业化、安全和成本。
第三步:建立分层 dashboard
先做用户结果层,再做技术链路层,最后做成本治理层。
用户结果层回答“有没有做出东西”。
技术链路层回答“为什么做不出来”。
成本治理层回答“做出来是否可持续”。
第四步:建立 golden task 和线上线下映射
任务集应该覆盖 landing、CRUD、auth、dashboard、content app、workflow app,并固定验收口径。
最终要看 offline eval 和 online success 的偏差。如果离线评测提升了,但线上首个预览率、发布率、回滚率没有改善,说明评测没有代表用户价值。
第五步:把指标纳入产品机制
到这里,指标体系才算从“看板”进入“产品系统”。落地前可以做一次自查:
- 是否定义了 active、activated builder、usable preview、successful publish;
- 是否能从一次注册追踪到首次 prompt、首次预览、首次编辑、首次发布;
- 是否能区分模型失败、构建失败、权限失败、发布失败和安全阻断;
- 是否能按任务类型、模板、渠道、模型、provider、用户层级分层;
- 是否能算出每次成功发布的成本,而不是只看 token 总额;
- 是否能把离线评测提升映射到线上预览率、发布率、回滚率和留存。
指标不是报表,而应该反过来塑造产品机制。
例如:
- 首个预览率低,就优化模板、prompt 引导和失败恢复;
- 发布率低,就优化发布引导、安全解释和部署检查;
- 成本高,就优化上下文压缩、缓存、模型路由和任务分级;
- 回滚率高,就优化生成验收、预览测试和变更解释;
- 安全阻断高,就把权限、secret、数据库策略做成默认安全配置。
开放问题与限制
这套指标体系不是行业硬标准,而是一个适用于 AI app builder 的建模框架。落地时有三点需要校准。
第一,目标值要根据产品定位调整。首个发布率、激活转付费率、cost per publish 都会受免费层策略、应用复杂度、用户是否偏工程背景、是否偏团队协作影响。
第二,公开公司数据更适合做赛道强度信号,不适合直接拿来当内部 KPI。尤其是 ARR、项目数、访问量等数据,往往有公司披露和媒体转述属性。
第三,如果产品最终不是通用 web app builder,而是内部工具平台、企业流程平台或垂直行业 workflow,那么 GRR、NRR、权限治理和连接器深度的权重要上升,DAU/MAU 的优先级则可能下降。
最后:指标体系的目标是解释“为什么”
Lovable 类产品最容易被三个表面指标误导:MAU、生成次数、token 消耗。
MAU 只能说明有人来过,不能说明用户是否做出了东西。
生成次数可能代表需求旺盛,也可能代表系统反复失败。
token 消耗可能代表产品增长,也可能代表上下文浪费。
有用的指标体系,应该能解释:
- 用户为什么没有完成首个可用预览;
- 为什么预览没有走到发布;
- 为什么发布后没有外部访问和协作;
- 为什么激活用户没有留存;
- 为什么成本上升;
- 为什么生成质量提升没有转化为用户成功;
- 为什么安全和治理会影响团队采购。
指标体系不是为了把产品看起来更好,而是为了让团队更快地找到因果关系。
对 Lovable 类 AI 应用生成产品来说,关键不是证明“有很多用户在生成”,而是证明:
用户能稳定地把想法变成可发布应用,并且这个过程在质量、成本、安全和协作上都是可持续的。
这才是这类产品应该建立的指标体系。
参考资料
- Lovable 官方文档、定价页与安全能力说明。
- Bolt.new 官方首页、定价页、Teams 文档与 token 使用说明。
- Replit 官方产品页、Agent / Deploy / Enterprise 文档与公开新闻资料。
- v0 / Vercel 官方产品更新、定价与企业能力说明。
- Amplitude Product Benchmarks 2025:activation、day-7 return 与长期留存关系。
- Mixpanel Benchmarks 2025:AI 产品 active user 应以结果事件和重复价值定义。
- Pendo Product Benchmarks:time to value、feature adoption 与 retention 参考。
- Google SRE:SLI、SLO 与 error budget 方法。
- Google Web Vitals:LCP、INP、CLS 官方阈值。
- DORA:软件交付绩效指标体系。
- Anthropic Claude 4、SWE-bench、Terminal-Bench 相关公开资料。
- Terminal-Bench 论文与真实 terminal task benchmark 讨论。