Codex 101|07|MCP Runtime
Codex 既能消费外部 MCP 工具,也能把自己暴露成 MCP server。
MCP 让 agent 可以连接外部工具生态,但也带来新的工程问题:外部工具名字不可控,schema 不一定适合模型,server 可能需要用户确认,工具调用可能要携带 thread、sandbox、trace 等 metadata。
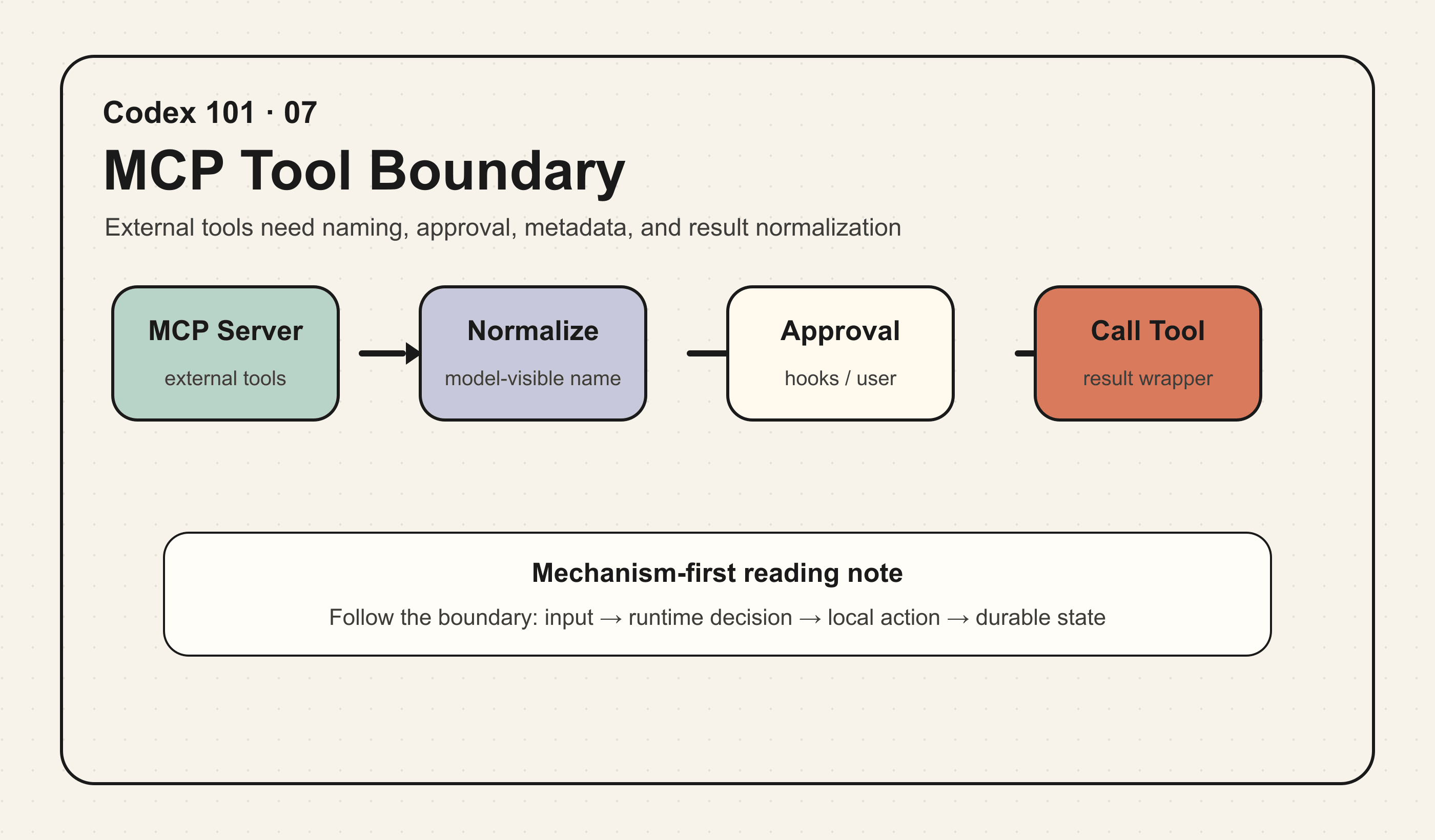
Codex 的 MCP 机制值得学习的地方,是它没有把 MCP 当作“多一个工具类型”简单塞进去,而是建立了 connection manager、tool normalization、approval、elicitation、metadata、server/client 双向身份等完整边界。
学习目标
- 理解 Codex 作为 MCP client 与 MCP server 的两种角色
- 理解 raw tool identity 与 model-visible identity 为什么要分离
- 理解 MCP elicitation 如何进入 session 生命周期
Codex 里的机制边界
MCP 的关键不只是“调用远端工具”,而是把外部工具生态安全地纳入本地 agent 的命名、审批、状态和事件体系。
把它放到“修复失败测试”的例子里,流程会变得很具体:用户不是在等待一次回答,而是在启动一个本地任务。Codex 要决定这一轮能看到哪些历史、模型可以使用哪些工具、哪些命令需要审批、工具输出如何写回上下文、哪些状态需要持久化,以及 UI 应该在什么时候向用户展示中间进展。
这也是 Codex 101 的核心阅读方式:不要只问“某个函数在哪里”,而要问“这个边界解决了什么工程问题”。如果一个边界能同时服务 TUI、exec、SDK、MCP 或 Cloud Tasks,它通常就是架构上的 load-bearing component。
关键源码锚点
| 文件 | 为什么重要 |
|---|---|
codex-rs/codex-mcp/src/connection_manager.rs |
机制锚点 |
codex-rs/codex-mcp/src/tools.rs |
机制锚点 |
codex-rs/codex-mcp/src/runtime.rs |
机制锚点 |
codex-rs/core/src/tools/handlers/mcp.rs |
机制锚点 |
codex-rs/core/src/mcp_tool_call.rs |
机制锚点 |
codex-rs/core/src/session/mcp.rs |
机制锚点 |
codex-rs/mcp-server/src/codex_tool_runner.rs |
机制锚点 |
codex-rs/mcp-server/src/message_processor.rs |
机制锚点 |
这些文件不应该被当作文章目录逐个解释。更好的读法是把它们分成三类:第一类定义协议和数据结构,第二类推进运行时状态,第三类把运行时能力暴露给产品界面或外部调用方。
机制拆解
第一步是入口归一化。无论用户来自 TUI、exec、SDK 还是 app-server,请求最终都需要变成运行时可以理解的结构。这样 core 不需要知道当前前端是终端 UI 还是程序化客户端。
第二步是状态装配。Agent 每一轮并不是裸 prompt,而是由配置、历史、工具、权限、模型能力、当前工作区和用户输入共同构成。Codex 的代码库反复体现了这个原则:模型请求只是 runtime state 的一个投影。
第三步是事件推进。模型流、工具调用、审批请求、命令输出、patch diff、token usage 和完成状态都以事件形式流动。事件既给 UI 渲染,也给状态层记录,还给上层客户端形成稳定 API。
第四步是结果回填。工具执行完并不意味着任务结束。结果需要被包装成模型可读的 item,追加到历史中,再由模型决定下一步。这就是 coding agent 与普通聊天机器人的根本差别。
读者应该抓住的主线
外部 MCP server 暴露的工具要经过命名规范化、schema 暴露、审批、metadata 注入和结果包装。
这也是本篇的核心判断:MCP 的难点不是连接 server,而是把外部工具纳入本地 runtime 的身份、权限和状态系统。 如果只看单个函数,很容易误以为 Codex 只是把用户输入转发给模型;如果从运行时边界看,就能看到它在处理一组更复杂的问题:谁拥有状态,谁负责安全,谁消费事件,谁把结果写回历史,谁对外暴露稳定协议。
用“修复失败测试”串起来
| 阶段 | 表面动作 | Runtime 真正要处理的事 |
|---|---|---|
| 用户输入 | “修复这个失败测试” | 绑定 thread、读取配置、确定当前工作区和可用能力 |
| 模型理解 | 生成分析和下一步动作 | 构造带历史、工具、策略和模型能力的请求 |
| 工具调用 | 运行测试、读取文件或应用 patch | 路由工具、检查审批、选择沙箱、执行并收集输出 |
| 结果回灌 | 模型看到命令输出 | 把 tool result 转成结构化 item,追加到上下文 |
| 完成收束 | 给用户总结 | 持久化 turn/item,更新 UI/SDK 事件,记录可恢复状态 |
这个例子会在系列中反复出现,因为它足够小,又能覆盖 coding agent 的关键机制。一个好的 runtime 不是让模型“更聪明”这么简单,而是让模型的每一步行动都有边界、有记录、有回路。
和普通聊天机器人的差别
| 维度 | 普通聊天 | Codex 这种本地 coding agent |
|---|---|---|
| 输入 | 用户消息 | 用户目标 + 工作区 + 历史 + 配置 + 工具能力 |
| 输出 | 文本回答 | 文本、推理摘要、工具调用、审批请求、diff、执行结果 |
| 状态 | 对话上下文 | thread、turn、item、rollout、SQLite metadata、工具状态 |
| 风险 | 答错 | 误读文件、误执行命令、越权联网、错误修改代码 |
| 关键能力 | prompt quality | runtime boundary、tool policy、state recovery、observability |
因此,Codex 101 的读法不是“看 OpenAI 怎么写代码助手”,而是借 Codex 这个实现,拆解一个本地 agent runtime 应该具备哪些工程边界。
可迁移伪实现:MCP Runtime
// conceptual sketch, not Codex source code
type RuntimeInput = { threadId: string; userGoal: string };
type RuntimeEvent =
| { type: "text_delta"; text: string }
| { type: "tool_call"; name: string; args: unknown }
| { type: "approval_required"; reason: string }
| { type: "completed" };
async function runCodexMechanism(input: RuntimeInput): Promise<RuntimeEvent[]> {
const state = await loadThreadState(input.threadId);
const prompt = buildPromptFromState(state, input.userGoal);
const events: RuntimeEvent[] = [];
for await (const event of streamModelAndRuntime(prompt)) {
events.push(normalizeRuntimeEvent(event));
await persistEvent(input.threadId, event);
}
return events;
}
这个伪实现故意保留了几个抽象函数:loadThreadState、buildPromptFromState、streamModelAndRuntime、persistEvent。真正重要的不是函数名,而是边界:加载状态、构造模型视图、消费结构化事件、持久化事实。
工程取舍
| 取舍 | Codex 的倾向 | 可以迁移的原则 |
|---|---|---|
| UI 与 core | 用协议和事件解耦 | 不要让 UI 直接承载 agent 生命周期 |
| 模型返回 | 流式结构化事件 | 不要只处理最终文本 |
| 工具执行 | 本地 runtime 统一调度 | 模型只提出调用,本地负责执行和安全 |
| 状态存储 | 日志与索引分离 | 事实可回放,查询可优化 |
| 扩展能力 | MCP、skills、hooks 分层 | 工具、上下文、策略不要混成一个概念 |
小结
MCP 的关键不只是“调用远端工具”,而是把外部工具生态安全地纳入本地 agent 的命名、审批、状态和事件体系。
如果只把 Codex 看成一个命令行工具,就会错过它真正值得学习的部分:它是一套把模型、工具、状态、安全和产品界面连接起来的本地 agent runtime。后续章节会继续沿着这条主线,把每个边界拆开来看。